Réf: APW
Le fil conducteur du module Analyse et programmation Web (APW) est de visiter différentes technologies qui permettront de développer une application web offrant une interface graphique aux utilisateurs d’un service REST.
Il existe différente approche pour réaliser ce travail. Comme toujours, chacune a ses avantages et ses inconvénients. Il n’y a pas vraiment une bonne solution. Il y a des solutions qui sont plus adaptées à un contexte donné.
Actuellement, l’architecture que l’on retrouve le plus souvent est l’architecture 3-tier. Elle est composée de trois couches:
La couche de présentation se charge de présenter les données à l’utilisateur. Elle peut être composée de pages HTML, de feuilles de style CSS et de scripts Javascript si on a affaire à un client web mais elle peut également être réalisée en application mobile ou en application desktop. Les technologies utilisées sont donc multiples et variées.
La couche métier se charge de traiter les données. Elle peut être réalisée en Java, en C#, en PHP, en Python, en Javascript, etc. Les technologies utilisées sont donc également multiples et variées.
La couche de données se charge de stocker les données. Elle peut être réalisée en SQL, en NoSQL, en XML, en JSON, etc. mais elle peut aussi se charger, par exemple, de créer des instances de conteneurs, les données étant alors les conteneurs eux-mêmes.
Dans notre cas, les couches de données et métier seront déjà implémentées. Notre travail se focalisera sur la couche de présentation.
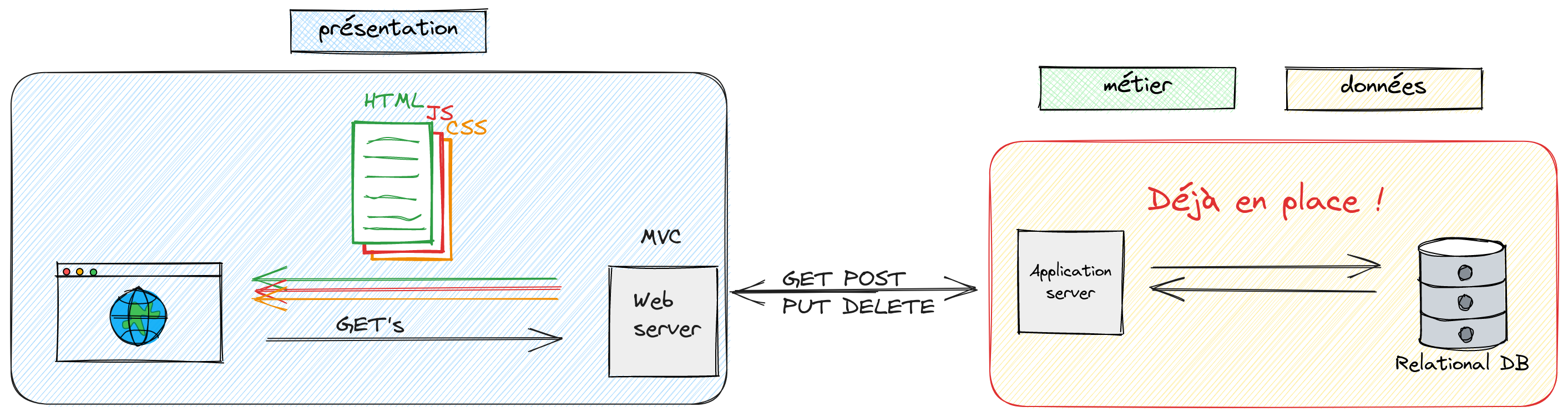
Les années précédentes, le cours s’articulait autour de cette
infrastructure (ci-dessous). Les élèves réalisaient non seulement la
partie présentation côté client, mais également une partie présentation
côté serveur intermédiaire Web Server. Cette partie était
réalisée en Java. La partie cliente faisait des requêtes au
serveur web et c’était le serveur web qui réalisait les requêtes au
serveur d’application. Le serveur web se chargeait également de mettre
en forme les données avant de les retourner au client sous forme
HTML.
En détails, ça donne ceci:

Nous allons moderniser un peu le schéma de fonctionnement. En effet, de plus en plus de travail est déporté chez le client. Cela permet de réduire la latence et d’améliorer la réactivité de l’application puisque nous accédons directement aux données sans passer par le serveur web intermédiaire. Par exemple, si je veux obtenir une liste d’utilisateurs, je peux la demander au serveur web qui va la demander au serveur d’application qui va la demander au serveur de données. Cela fait trois allers-retours. Si je peux demander directement la liste des utilisateurs au serveur d’application, je court-circuite le serveur web.
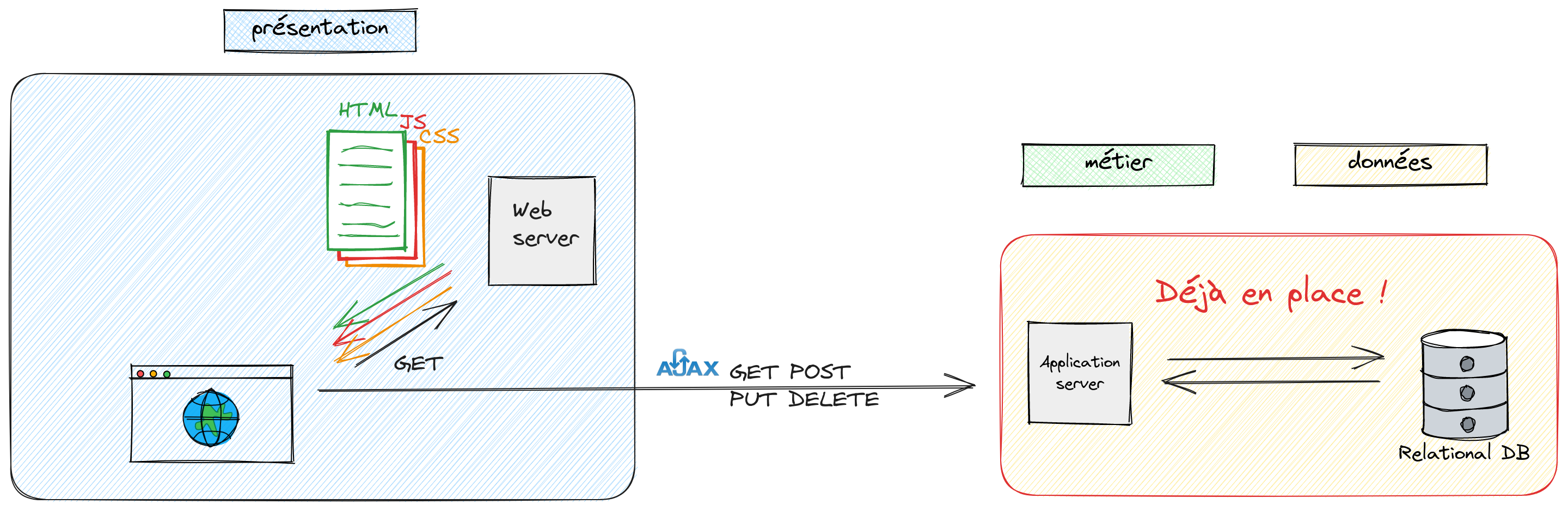
Idéalement, le principe sera le suivant:

Le client recevra au départ une page HTML ainsi qu’une page CSS pour la mise en forme. Il recevra également une ou plusieurs pages Javascript. Ces pages Javascript seront chargées de récupérer les données auprès du serveur d’application. Elles seront également chargées de mettre en forme les données et de les afficher à l’utilisateur.
Les requêtes effectuées par le navigateur au serveur de données seront réalisées en AJAX. Les données transiteront en JSON entre le serveur d’application et le client. Le CRUD sera réalisé au travers des opérations standard du protocole HTTP à savoir POST, GET, PUT et DELETE. On pourra ainsi prétendre à une architecture REST.
L’affichage devant être responsive sur tous les navigateurs mais aussi sur toutes les plateformes (PC, tablette, smartphone, etc.), nous utiliserons une librairie CSS qui se nomme Bootstrap. Elle offre des fonctionnalités de mise en forme et de mise en page qui permettent de s’adapter à toutes les tailles d’écrans.
Pour terminer, nous utiliserons un serveur web Apache.
[OPTIONNEL]
On pourra installer le serveur Apache dans un conteneur Incus. Pour démarrer construire et configurer correctement le conteneur Incus, nous pourrons utiliser un outil nommé cloud-init.
Si on résume les sujets à aborder, nous avons:
Autant dire tout de suite qu’on ne va pas s’ennuyer 🤯.
Il existe de multiple resources sur le web pour apprendre à utiliser les technologies que nous allons aborder. Voici quelques liens qui pourront vous aider:
Hé oui, on est obligé de parler de ce perroquet statisticien. Car il s’agit exactement de ça. En 2023, il n’y a pas encore officiellement d’IA
En d’autres termes, la machine en sait bien moins sur les chats qu’un enfant de cinq ans. Et pourquoi? Parce que l’enfant a déjà vu un chat, qu’il l’a caressé, qu’il l’a entendu ronronner et que toutes ces informations sont venues enrichir la «carte» du chat qu’il a dans son cerveau.
Vous devez utiliser ChatGPT avec parcimonie et SURTOUT, vous devrez valider les réponses qui vous seront fournies si vous ne voulez pas tomber dans le même travers que cet avocat lire l’article.
J’ai moi-même expérimenté ChatGPT et je peux vous affirmer que les trois codes que je lui ai demandé de réaliser étaient faux. Vous pouvez trouver sur ce lien un des trois examples. ChatGPT n’est pas conçu pour être utilisé dans un contexte de programmation. Copilot est un bien meilleur choix pour ce genre de tâche.
Comme il est illusoire et pas malin de vous empêcher d’utiliser ces outils, je vous demande d’utiliser CoPilot en tant qu’extension de votre outil de programmation. Par exemple, pour Visual Code, il existe cette extension officielle. Le compte de l’école vous permet d’utiliser CoPilot qui est normalement payant.

Vous devez tenir compte du fait que tout ces assistants consomment énormément de resources et à l’heure actuelle ce n’est pas banale. Il est donc important de ne pas abuser de cette technologie et lorsque vous êtes en cours, et bien, demandez à votre enseignant de vous aider. Il est payé pour ça et il emmet peut de CO2.
Parce qu’il n’y a pas que ChatGPT, posez-vous les questions suivantes :
Il n’y a pas de jugement dans ces questions, c’est juste des questions qui peuvent vous amener à réfléchir sur votre consommation d’énergie parce qu’on est tous dans le même bateau. 🚢
Qu’est-ce que c’est que ça encore? 🤔
HTTP est le protocole de communication utilisé sur Internet par les navigateurs. C’est un protocole qui évolue et qui est actuellement à sa version 3.0. C’est un protocole dont vous avez déjà entendu parlé lors de vos précédents cours et c’est ici uniquement un rappel.
La vidéo ci-dessous correspond au cours e rappel que je vous aurai donné. Je vous invite à la regarder attentivement. Vous pouvez également la regarder en accéléré si vous le souhaitez 🤓. Vous pouvez tester la partie NodeJS Express ainsi que Postman mais nous y reviendront plus tard.
Le dessin ci-dessous vous permet de visualiser chaque étape de fonctionnement d’une requête HTTP.
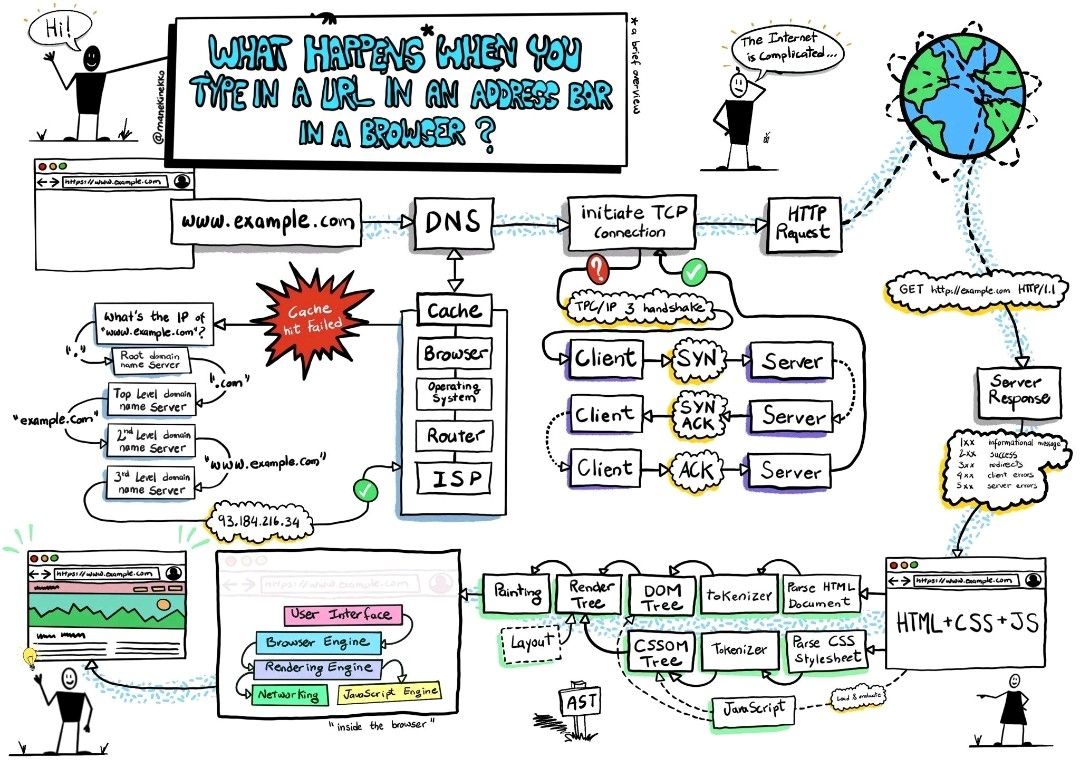
💬 Placez-vous dans la peau d’un septique. En regardant l’image ci-dessus, il voit la partie DNS, suivie par TCP encore suivi d’HTTP. Mais voilà, en bon septique il a besoin de voir pour croire. Trouvez un moyen de montrer ces 3 étapes à un septique. 🤔

💬 Que veut dire HTTP?
💬 Que veut dire HTTPS?
💬 Où puis-je trouver la spécification HTTP?
💬 Si je reçois un code 4XX, qu’est-ce que ça veut dire?
💬 Si je reçois un code 5XX, qu’est-ce que ça veut dire?
💬 Si je reçois un code 2XX, qu’est-ce que ça veut dire?
💬 Que signifie cette requête?
POST /user HTTP/1.1
Host: example.org
Content-Type: application/json
Content-Length: 112
{"username":"jdoe", "password":"secret", "email":"john.doe@example.org", "first_name":"John", "last_name":"Doe"}L’objectif de cet exercice, c’est de faire une requête HTTP à la
main. C’est-à-dire que vous devrez écrire la requête lettre par
lettre, manipuler les headers et comprendre les codes de
retour.
Le travail est le suivant:
Vous trouver un serveur à l’adresse https://pdf-cours.ch/http/. Vous devez envoyer une requête au bon fichier avec:
X-HTTP-APW
contenant la valeur cours_apwAPW
ayant comme valeur cookie_apwmy ayant comme valeur nameis ayant comme valeur slimshadySi votre requête est correctement effectuée, vous recevrez le flux
JSON suivant en réponse:
{"status":"success"}Vous devez faire votre requête à la main sans navigateur. Par exemple avec openssl s_client.
$ openssl s_client -connect pdf-cours.ch:443
CONNECTED(00000003)
...
read R BLOCK
GET / HTTP/1.1
Host: pdf-cours.ch
HTTP/1.1 200 OK
...Pourquoi en ligne de commande? 🤔 La ligne de commande doit être vue comme une formidable boite à outils. Comme pour un électricien dont la boite à outils contient des tournevis, des testeurs de courant, des pinces etc. votre boite à outils contient des utilitaires pour lister les fichiers, filtrer des informations, configurer une interface réseau etc.
Chaque outil a une fonction bien précise et il possède des options qui permettent de changer son mode de fonctionnement. Imaginez une interface graphique GUI mettant en pratique toutes les options de la commande find. En plus, en utilisant des pipes on peut combiner les outils pour réaliser des tâches complexes.
Exemple
Si je vous demande de me fournir uniquement les 3 fichiers zip de plus de 100Mo présent dans votre répertoire personnel et qui ont été créer le jeudi entre 8h et 9h ?
$ find ~ -type f -name "*.zip" -size +100M -newermt "2023-06-01 08:00:00" ! -newermt "2023-06-01 09:00:00"Ou encore, les 3 plus gros fichiers zip de plus de 100Mo présent dans votre répertoire personnel ?
$ find ~ -type f -name "*.zip" -size +100M -exec du -b -h {} \; | sort -h -r | head -n 3De plus, avec ces outils il est possible de scripter des actions et de les automatiser. On peut par exemple, mettre en place une tâche planifiée qui va archiver tous les fichiers de plus de 30 jours dans un répertoire.
select(any(.Names[];
contains(“data”))|not)|.Id)[])
curl est un outil en ligne de commande
qui permet de faire des requêtes HTTP. Il est disponible sur toutes les
plateformes et des bindings existent pour tous les langages de
programmation. Si vous savez utiliser curl en ligne de
commande, vous savez l’utiliser en C ou en PHP. Il est, par
ailleurs, présent nativement dans toutes les distributions Linux même
celles dérivées comme Android.
Il possède une grande quantité d’options parmi lesquelles :
-X pour spécifier la méthode HTTP, par défaut c’est
GET mais avec -X POST on peut faire une requête de type
POST-H pour spécifier un header HTTP, par exemple
-H "Content-Type: application/json" pour spécifier que le
contenu de la requête est du JSON-d pour spécifier le corps de la requête, par exemple
-d '{"username":"jdoe", "password":"secret"}' pour
spécifier que le corps de la requête est du JSON-v pour afficher les détails de la requête et de la
réponse, notamment les headers-s pour ne pas afficher la barre de progression-o pour spécifier le fichier de sortie, par exemple
-o response.json pour écrire la réponse dans un fichier
response.json-k pour ignorer les erreurs de certificat SSL, par
exemple, si vous faites une requête sur un serveur en HTTPS qui a un
certificat auto-signé$ curl -sX GET https://swapi.dev/api/people/3/ | jq
{
"name": "R2-D2",
"height": "96",
"mass": "32",
"hair_color": "n/a",
"skin_color": "white, blue",
"eye_color": "red",
"birth_year": "33BBY",
"gender": "n/a",
"homeworld": "https://swapi.dev/api/planets/8/",
"films": [
"https://swapi.dev/api/films/1/",
"https://swapi.dev/api/films/2/",
"https://swapi.dev/api/films/3/",
"https://swapi.dev/api/films/4/",
"https://swapi.dev/api/films/5/",
"https://swapi.dev/api/films/6/"
],
"species": [
"https://swapi.dev/api/species/2/"
],
"vehicles": [],
"starships": [],
"created": "2014-12-10T15:11:50.376000Z",
"edited": "2014-12-20T21:17:50.311000Z",
"url": "https://swapi.dev/api/people/3/"
}Vous trouverez cet utilitaire sur le site web du même nom httpie. Il est disponible sur toutes
les plateformes et plus précisément via snap sur Linux et
choco sur Windows.
openssl possède un outil permettant de réaliser des requêtes sécurisées. Il peut-être utilisé pour tester un serveur en HTTPS car il permet de voir les détails des échanges TLS.
printf "GET /api/people/1 HTTP/1.1\nHost: swapi.dev\n\n" | openssl s_client -ign_eof -connect swapi.dev:443
CONNECTED(00000003)
depth=2 C = US, O = Internet Security Research Group, CN = ISRG Root X1
verify return:1
depth=1 C = US, O = Let's Encrypt, CN = R3
verify return:1
depth=0 CN = swapi.dev
verify return:1
---
Certificate chain
0 s:CN = swapi.dev
i:C = US, O = Let's Encrypt, CN = R3
a:PKEY: rsaEncryption, 2048 (bit); sigalg: RSA-SHA256
v:NotBefore: May 16 10:20:18 2023 GMT; NotAfter: Aug 14 10:20:17 2023 GMT
1 s:C = US, O = Let's Encrypt, CN = R3
i:C = US, O = Internet Security Research Group, CN = ISRG Root X1
a:PKEY: rsaEncryption, 2048 (bit); sigalg: RSA-SHA256
v:NotBefore: Sep 4 00:00:00 2020 GMT; NotAfter: Sep 15 16:00:00 2025 GMT
2 s:C = US, O = Internet Security Research Group, CN = ISRG Root X1
i:O = Digital Signature Trust Co., CN = DST Root CA X3
a:PKEY: rsaEncryption, 4096 (bit); sigalg: RSA-SHA256
v:NotBefore: Jan 20 19:14:03 2021 GMT; NotAfter: Sep 30 18:14:03 2024 GMT
---
Server certificate
-----BEGIN CERTIFICATE-----
MIIFFzCCA/+gAwIBAgISA8GW4WREzkOCuPi+s6g1q4sxMA0GCSqGSIb3DQEBCwUA
MDIxCzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQD
EwJSMzAeFw0yMzA1MTYxMDIwMThaFw0yMzA4MTQxMDIwMTdaMBQxEjAQBgNVBAMT
CXN3YXBpLmRldjCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAKAbQ9O5
+hkP1hLqjnvqJHQ3dvfv1yO2nqUyVsW4gA/a69o3oXHvmrKw/mfsKxAhLKJtQl7Z
bJrhRUsfeU0EGC9eo9xaZ6K9L7wcPVwPHdKRA0FgKTHPxkB9HZPF3+OVLVYBah+1
NYXM7DihqMXg1Z5KHocBPLZ1vXAbIdG5FiSqVby3KkJvduG/CVab51n3oFmOYIok
KSlYWVmfLXSNF6v62+m+sriM4kS2Yfk5+CgZ+iD35MrcL+m2cx5ci/KL0+Qlz70r
AUlG1VDixyqUS1tFBzM8kKGw4k5o80Vkytsm3HKcQVesA1c0ICCKxhpORHNuvZNh
Elctl7ltCkAkCi0CAwEAAaOCAkMwggI/MA4GA1UdDwEB/wQEAwIFoDAdBgNVHSUE
FjAUBggrBgEFBQcDAQYIKwYBBQUHAwIwDAYDVR0TAQH/BAIwADAdBgNVHQ4EFgQU
KD+LA9LBgyXppPXXQGntsRx26dIwHwYDVR0jBBgwFoAUFC6zF7dYVsuuUAlA5h+v
nYsUwsYwVQYIKwYBBQUHAQEESTBHMCEGCCsGAQUFBzABhhVodHRwOi8vcjMuby5s
ZW5jci5vcmcwIgYIKwYBBQUHMAKGFmh0dHA6Ly9yMy5pLmxlbmNyLm9yZy8wFAYD
VR0RBA0wC4IJc3dhcGkuZGV2MEwGA1UdIARFMEMwCAYGZ4EMAQIBMDcGCysGAQQB
gt8TAQEBMCgwJgYIKwYBBQUHAgEWGmh0dHA6Ly9jcHMubGV0c2VuY3J5cHQub3Jn
MIIBAwYKKwYBBAHWeQIEAgSB9ASB8QDvAHYAtz77JN+cTbp18jnFulj0bF38Qs96
nzXEnh0JgSXttJkAAAGIJEokZgAABAMARzBFAiBbG6sKdbllCMhv2ds9cFs2xk/P
KE66x/7LqBjGFkdrZQIhALxkZovcqRrsu9vfnhgRz+v7kfxXD4HhQoWb0KfanvRg
AHUAejKMVNi3LbYg6jjgUh7phBZwMhOFTTvSK8E6V6NS61IAAAGIJEokmwAABAMA
RjBEAiAUtw+WSoYh4jM0i7gRqX4l+TcOHOhbIFcM2DDzIzACMQIgd+5GTJzb+8RJ
LiTiDWEk5HHw0RQbRnjGSQP9xPDRg6QwDQYJKoZIhvcNAQELBQADggEBAJ0P11kL
6ZUbpngEY17a9fiAQ1k/c1sfWrXkbE3IpIxhNjotEpcOOPWzJgS5Tn4qPUBtJDq9
A/Snb9SJ/9IC0JU5qowipO1jufwbcLW+zkBKtRO7cZcI6IoJvYf/SrkENmoEROhA
+j2RmCfORV9zGQjgFLDpWWjg9ca1NWCFYVREhTi0aFp7EJOsMMS0eEjE29Ev8a4w
ofY08pCU38ojBkyYzvlIQZdKSe0LX9Z3ss/VTe1E2Yb8xok7qJPPBpdJqsNcspRW
LgQ2GbTMuTMV1n2yJOG/doU7T2x4PaPz9ZjdAtKmgGGnj49Ic38xdfnYoP+phy9p
ndwbzlL25wgNGsg=
-----END CERTIFICATE-----
subject=CN = swapi.dev
issuer=C = US, O = Let's Encrypt, CN = R3
---
No client certificate CA names sent
Peer signing digest: SHA512
Peer signature type: RSA
Server Temp Key: ECDH, prime256v1, 256 bits
---
SSL handshake has read 4510 bytes and written 437 bytes
Verification: OK
---
New, TLSv1.2, Cipher is ECDHE-RSA-AES128-GCM-SHA256
Server public key is 2048 bit
Secure Renegotiation IS supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
SSL-Session:
Protocol : TLSv1.2
Cipher : ECDHE-RSA-AES128-GCM-SHA256
Session-ID: 27EB63E13DA55C462B3A373D8D06E816A9A07D2C5C482299395E1399604F118F
Session-ID-ctx:
Master-Key: 7A5339ACD3910E259EEAD5BBED474D08A72537604D7EC738668D6D6C530AFB0806E8ED5E512ECDD7DD6D4FA8EEF237DC
PSK identity: None
PSK identity hint: None
SRP username: None
Start Time: 1687766383
Timeout : 7200 (sec)
Verify return code: 0 (ok)
Extended master secret: no
---
HTTP/1.1 200 OK
Server: nginx/1.16.1
Date: Mon, 26 Jun 2023 07:59:43 GMT
Content-Type: application/json
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept, Cookie
X-Frame-Options: SAMEORIGIN
ETag: "ee398610435c328f4d0a4e1b0d2f7bbc"
Allow: GET, HEAD, OPTIONS
Strict-Transport-Security: max-age=15768000
287
{"name":"Luke Skywalker","height":"172","mass":"77","hair_color":"blond","skin_color":"fair","eye_color":"blue","birth_year":"19BBY","gender":"male","homeworld":"https://swapi.dev/api/planets/1/","films":["https://swapi.dev/api/films/1/","https://swapi.dev/api/films/2/","https://swapi.dev/api/films/3/","https://swapi.dev/api/films/6/"],"species":[],"vehicles":["https://swapi.dev/api/vehicles/14/","https://swapi.dev/api/vehicles/30/"],"starships":["https://swapi.dev/api/starships/12/","https://swapi.dev/api/starships/22/"],"created":"2014-12-09T13:50:51.644000Z","edited":"2014-12-20T21:17:56.891000Z","url":"https://swapi.dev/api/people/1/"}
0Après avoir crée un compte sur le site mockapi.io, créez une API REST qui permet de gérer des utilisateurs. Chaque utilisateur doit avoir un id, une date de création, un nom, un prénom, un email et un mot de passe.
Vous devez pouvoir créer (C), lire (R), modifier (U) et supprimer (D) un utilisateur en utilisant uniquement des outils en ligne de commande. Vous devez également pouvoir lire tout les utilisateurs en une seule requête.
Par exemple:
$ curl -s https://6499484179fbe9bcf83ee6bd.mockapi.io/api/v1/users | jq
[
{
"createdAt": "2023-06-25T18:29:39.754Z",
"firstName": "Walton",
"lastName": "Koepp",
"email": "Daisy.Hahn8@hotmail.com",
"password": "864a619a0cfb0167c50c683bada4bec0b20aa22c",
"id": "1"
},
{
"createdAt": "2023-06-25T10:56:16.977Z",
"firstName": "Charity",
"lastName": "Lynch",
"email": "Maxie88@hotmail.com",
"password": "0420eeb065f85c9f1144c3acd953e6c5dff43142",
"id": "2"
},
{
"createdAt": "2023-06-26T06:27:29.946Z",
"firstName": "Gideon",
"lastName": "Kris",
"email": "Doyle_Renner52@yahoo.com",
"password": "15f9f4bf9fab0ab37e3b9e99b27e3646ce51c5f5",
"id": "3"
},
{
"createdAt": "2023-06-25T15:23:31.527Z",
"firstName": "Marcel",
"lastName": "Trantow",
"email": "Kristopher51@hotmail.com",
"password": "fe0bcca27dfaacea8e51da4bccdaa9cfac67b080",
"id": "4"
}
]Le web scraping, parfois appelé harvesting ou en français moissonnage, est une technique d’extraction des données de sites Web par l’utilisation d’un script ou d’un programme dans le but de les transformer et les réutiliser dans un autre contexte comme l’enrichissement de bases de données, le référencement ou l’exploration de données.
Objectif
L’objectif de cet exercice est de créer un scrapper spécifique qui va parcourir le site web du CPNE-TI et qui va récupérer les images des tuiles de la page d’accueil.

Vous devez utiliser uniquement des outils en ligne de commande et, si vous le souhaitez, réunir ces commandes dans un script bash.
Analyse sommaire
Il faut identifier des points communs entre les tuiles qui permettent
de les différencier du reste du code HTML. Par exemple, on peut voir que
toutes les tuiles ont une classe ms-tileview-tile-root et
que toutes les images ont une classe
ms-tileview-tile-content.
Une fois que vous avez identifié ces points communs, vous pouvez, par exemple:
curl pour récupérer le code HTML de la page
d’accueilgrep pour filtrer les lignes qui contiennent
les points communssed pour extraire les liens des imagesxargs pour télécharger les imagesVous n’avez pas le droit d’installer des outils supplémentaires à l’exception de xpath et/ou xmllint. Vous devez utiliser uniquement les outils de base de Linux.
Ceux qui ont lu la donnée jusqu’ici peuvent maintenant analyser plus
finement le code HTML et se rendre compte que les classe
ms-tileview-tile-root ne sont pas présentes dans le code
HTML reçue avec un outil en ligne de commande. C’est normale car les
classes sont appliquée dynamiquement par du code Javascript. Hors, une
commande comme curl ne peut pas exécuter du code
Javascript. Le code HTML qu’on regarde dans le navigateur ne
correspond donc pas à celui reçu à la base, avant que Javascript ne
fasse son travail.
C’est de plus en plus souvent le cas. La majorité des gros sites web fonctionnent de cette manière. C’est le cas d’un site assez connu nommé Google 😜 mais aussi du site Pixabay.
Il faut donc reprendre l’analyse au début…
Dans la page HTML reçue, les futurs tuiles sont présentes sous la forme d’un tableau. Chaque ligne du tableau correspond à une tuile.
#!/bin/env bash
OUTPUT="images"
BASE_URL="https://cpne-t.rpn.ch"
HTML=$(curl -s "$BASE_URL/Pages/Accueil.aspx")
TDS=$(echo $HTML | xmllint --quiet --nowarning --html --xpath '//table/tr/td[@class="ms-vb2"]/a/@href' - 2>/dev/null | sed 's/href="\([^"]*\)"/\1/g' | grep -Pi "\.(png|jpg|jpeg)$")
if [[ ! -e $OUTPUT ]]; then
mkdir $OUTPUT
fi
while IFS= read -r line; do
trimmed=$(echo $line | sed 's/ *$//g')
filename=$(basename -- "$trimmed")
extension="${filename##*.}"
filename="${filename%.*}"
curl --output "$OUTPUT/$filename.$extension" "$BASE_URL$trimmed"
done <<< "$TDS"Contexte
Le site rottentomatoes est un site qui classifie les films en fonction des avis de la presse et des spectateurs. De part son contenu, il est également une source fiable pour récupérer des informations sur les films tel que le titre, le synopsis, la date de sortie, la durée, le genre, le réalisateur, les acteurs, etc.
Objectif
Réaliser un script qui :
audience_highest
(les films les mieux notés par le public)<script type="application/ld+json">info.json qui contient les
informations du filmpostercast qui contient les photos des
acteurs que l’on trouve selon le même principe sur la page rottentomatoes du film
#!/usr/bin/env bash
BASE_URL="https://www.rottentomatoes.com"
TOP_MOVIES="browse/movies_in_theaters/sort:top_box_office"
OUTPUT="data"
MOVIES=$(curl -s "$BASE_URL/$TOP_MOVIES" | tr -d '\n' | grep -Po '(?<=<script type="application/ld\+json">).*?(?=</script>)')
for row in $(echo "$MOVIES" | jq -r '.itemListElement.itemListElement[] | @base64');
do
NAME=$(echo "$row" | base64 -d | jq -r .name)
IMAGE_URL=$(echo "$row" | base64 -d | jq -r .image)
MOVIE_URL=$(echo "$row" | base64 -d | jq -r .url)
mkdir -p "$OUTPUT/$NAME"
curl -s -o "$OUTPUT/$NAME/$NAME.xxx" "$IMAGE_URL"
EXT=$(file -b --extension "$OUTPUT/$NAME/$NAME.xxx" | cut -d '/' -f1)
mv "$OUTPUT/$NAME/$NAME.xxx" "$OUTPUT/$NAME/$NAME.$EXT"
mkdir -p "$OUTPUT/$NAME/actors"
ACTORS=$(curl -s "$MOVIE_URL" | tr -d '\n' | grep -Po '(?<=<script type="application/ld\+json">).*?(?=</script>)')
for actor in $(echo "$ACTORS" | jq -r '.actor[] | @base64');
do
ACTOR_NAME=$(echo "$actor" | base64 -d | jq -r .name)
ACTOR_IMAGE_URL=$(echo "$actor" | base64 -d | jq -r .image)
curl -s -o "$OUTPUT/$NAME/actors/$ACTOR_NAME.xxx" "$ACTOR_IMAGE_URL"
EXT=$(file -b --extension "$OUTPUT/$NAME/actors/$ACTOR_NAME.xxx" | cut -d '/' -f1)
mv "$OUTPUT/$NAME/actors/$ACTOR_NAME.xxx" "$OUTPUT/$NAME/actors/$ACTOR_NAME.$EXT"
done
doneContexte
Qui ne connait pas le site twitter ? Ou plutôt X qui se
trouve à l’adresse twitter. Bizarre 🤔.
Pour pouvoir utiliser le site il faut posséder un compte. Pour cet exercice vous pouvez utiliser votre compte personnel ou créer un compte factice dédié uniquement à cet exercice. Pour ma part j’utilise un compte factice grâce à une adresse email jetable mohmal.
Objectif
On aimerait récupérer les tweets attachés à un hashtag. Par exemple,
on aimerait récupérer les tweets qui contiennent le hashtag
#javascript.
Pour cela, il faut:
SearchTimeline qui se présente ainsi:
https://twitter.com/i/api/graphql/HgiQ8U_E6g-HE_I6Pp_2UA/SearchTimeline?variables={"rawQuery":"#javascript","count":20,"querySource":"typed_query","product":"Top"}&...authorization qui contient le token d’authentification
authorization Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJU4FA33AGWWjCpTnBx-csrf-tokenauth_tokentweet_results qui
contient les tweets.Maintenant que vous êtes en possession de toutes les informations nécessaires, vous pouvez réaliser le script qui permet de récupérer les tweets.
curl 'https://twitter.com/i/api/graphql/HgiQ8U_E6g-HE_I6Pp_2UA/SearchTimeline?variables=%7B%22rawQuery%22%3A%22%23javascript%22%2C%22count%22%3A20%2C%22querySource%22%3A%22typed_query%22%2C%22product%22%3A%22Top%22%7D&features=%7B%22responsive_web_graphql_exclude_directive_enabled%22%3Atrue%2C%22verified_phone_label_enabled%22%3Afalse%2C%22creator_subscriptions_tweet_preview_api_enabled%22%3Atrue%2C%22responsive_web_graphql_timeline_navigation_enabled%22%3Atrue%2C%22responsive_web_graphql_skip_user_profile_image_extensions_enabled%22%3Afalse%2C%22c9s_tweet_anatomy_moderator_badge_enabled%22%3Atrue%2C%22tweetypie_unmention_optimization_enabled%22%3Atrue%2C%22responsive_web_edit_tweet_api_enabled%22%3Atrue%2C%22graphql_is_translatable_rweb_tweet_is_translatable_enabled%22%3Atrue%2C%22view_counts_everywhere_api_enabled%22%3Atrue%2C%22longform_notetweets_consumption_enabled%22%3Atrue%2C%22responsive_web_twitter_article_tweet_consumption_enabled%22%3Atrue%2C%22tweet_awards_web_tipping_enabled%22%3Afalse%2C%22freedom_of_speech_not_reach_fetch_enabled%22%3Atrue%2C%22standardized_nudges_misinfo%22%3Atrue%2C%22tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled%22%3Atrue%2C%22rweb_video_timestamps_enabled%22%3Atrue%2C%22longform_notetweets_rich_text_read_enabled%22%3Atrue%2C%22longform_notetweets_inline_media_enabled%22%3Atrue%2C%22responsive_web_media_download_video_enabled%22%3Afalse%2C%22responsive_web_enhance_cards_enabled%22%3Afalse%7D' -H 'content-type: application/json' -H 'authorization: Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJU4FA33AGWWjCpTnB' -H 'Cookie: guest_id=v1%3A170608344965347818; gt=1750066947759231257; g_state={"i_p":1706090653360,"i_l":1}; d_prefs=MjoxLGNvbnNlbnRfdmVyc2lvbjoyLHRleHRfdmVyc2lvbjoxMDAw; _twitter_sess=BAh7BiIKZmxhc2hJQzonQWN0aW9uQ29udHJvbGxlcjo6Rmxhc2g6OkZsYXNo%250ASGFzaHsABjoKQHVzZWR7AA%253D%253D--1164b91ac812d853b877e93ddb612b7471bebc74; kdt=mYseqxgjXJ2TDPHg0ON1yFBNGrbwkfxJpbqAgmXv; twid=u%3D1750067637814480896; ct0=a46700da11dcef1e232cbcedc349b233012bd7a9ac5049bf53cec7aab94ab8fda7f0b68ef435ec2ea78d253823bd3c84ba05df5463326bbc6be3a863a73f97cc18db20c40b5e8cd6a3a13530595ba2d5; auth_token=0e9305e81febb7ade43ae2062a2ea6ddd1d18dc7; lang=en' -H 'x-csrf-token: a46700da11dcef1e232cbcedc349b233012bd7a9ac5049bf53cec7aab94ab8fda7f0b68ef435ec2ea78d253823bd3c84ba05df5463326bbc6be3a863a73f97cc18db20c40b5e8cd6a3a13530595ba2d5' | jq .data.search_by_raw_query.search_timeline.timeline.instructions[0].entries[] | jq 'select(.content.itemContent.tweet_results.result.legacy.full_text != null)' | jq '.entryId + " " + .content.itemContent.tweet_results.result.legacy.full_text'"tweet-1750074961232810035 JavaScript Tip 💡\n\nRest parameters can also be used to collect the remaining properties of an object into another object. \n\nThis is a handy way to extract some properties from an object and store the rest in another object. 🙋♂️\n\nFor example, you can do this:\n#javascript https://t.co/bNNsplumAC"
"tweet-1749710798820167847 Made a lot of progress with @bestmodsio recently! Still a lot to do and areas to improve in, but I think it's in a decent state for now. Now it's time to work on services for @deaconn_!\n\n#100daysofcode #buildinpublic #coding #javascript #website #gaming #react #modding #tech https://t.co/BlpBzG03X7"
"tweet-1749790966016336195 Day 16 - Text-shadow effect using #JavaScript.\nMouse movements trigger a dynamic blend of text and background, with content changing every 3 seconds. 🚀\n\n#JavaScript30\n#100DaysOfCode\n#HTML \n#CSS https://t.co/xyQqYBsY0h"
"tweet-1750061323847889173 How to Create a Responsive Slideshow with CSS and JavaScript\n#css #javascript\nhttps://t.co/DsEwtkcnDh"
"tweet-1750068365392216409 Build 16 JavaScript Projects - Vanilla JavaScript Course\n#javascript\nhttps://t.co/KOKVGS7SAm"
"tweet-1749695867727270018 CSS Box Shadow Generator using JavaScript with Source Code\n#html #css #javascript\nhttps://t.co/3sef1Ottn0"
"tweet-1747642458140254376 100 days coding challenge Day 16.\n\nSeperation of concerns I'm Nodejs application.\nFull video: \nhttps://t.co/7I8pmHiBJi\n\n#100DaysOfCode #javascript #nodejs #mongodb #express https://t.co/KzXDQIVGxd"
"tweet-1750061954977464585 Implementation of Post-Order Traversal recursively in #javascript https://t.co/m1rVC4l608"
"tweet-1750049437844746384 Implementation of Post-Order Traversal iteratively using Two Stack in #JavaScript\nTC: O(n) https://t.co/2QWtgnI1RC"
"tweet-1750064848896229609 Crop and Download Images with HTML, CSS, and JavaScript\n#html #css #javascript \nhttps://t.co/YfI8A0tc9r"
"tweet-1749909539565023703 Day 49 #100DaysOfCode of learning #javascript programming for #frontendDevelopment\n\nLearned to destructure arrays and objects. Also learned to work with the spread operator...\n\ncc: @iamdanztee https://t.co/en2hkTw5fu"
"tweet-1749898969403294065 Check out a Random Colour Generator that I built using HTML, CSS and JavaScript!\n\nView the App: https://t.co/cX9UhfYyGW\nView Code: https://t.co/91N3tbg5yV\n\nWould love your feedback!🙌\n#javascript #buildinpublic #FrontEnd #webdevelopment #coding #html #CSS https://t.co/LD1i1HOTqP"
"tweet-1749824064888435087 Day 22 of #100daysofcode challenge || The odin project || #theodinproject #coding #javascript https://t.co/xXcZOsxPpw"
"tweet-1749879518217527306 Day 6of #100daysofcode of code with #js \n\nToday I learnt about : \nData transformation using the\n- map method\n- filter method\n- reduce method\n\n#100daysofcode #javascript https://t.co/vPvrpdZ0Mp"
"tweet-1749823461361635371 🌟Day 38 of #100DaysOfCode 🌟\n\nToday, I tackled try-catch and learned how to handle errors in JavaScript! 🚀💻\n\nMaking coding smoother, one step at a time! 👏🔥\n\n#CodingJourney #webdev #javascript #tech #buildinginpublic"
"tweet-1749825180694925412 Responsive Movie Website Using HTML CSS And jQuery with Source Code\n#html #css #javascript\nhttps://t.co/VMSEbPJq8Y"
"tweet-1749957153526321496 This Fall, let's handle your:-\n#Assignments\n#Calculus\n#Homework\n#Fallclasses\n#Onlineclass\n#Finance\n#Accounting\n#Essaydue\n#Engineering\n#Music\n#Art\n#Nursing\n#Law\n#Javascript\n#Python\n#Programming\n\n#Fallsemester\n#CodeNewbies \n#100daysofcode\n#AI\n#WebDev\nHit our Bio for More info:) https://t.co/Kt2j87u2g4"
"tweet-1749433173522448668 Day 15 - A minimalistic to-do list using #HTML, #CSS, and #JavaScript. It allows users to add, check, uncheck and clear items on the to-do list, and all the data is stored locally in the browser using the Local Storage API.\n\n#JavaScript30\n#100DaysOfCode https://t.co/6pqvkmU14x"Après avoir crée un compte sur le site root-me, réalisez les challenges suivants sans demander aucune aide extérieure 😡:
1.1 vs
2 vs 3Nous ferons ici l’impasse sur les version 0.9 et
1.0 qui ne sont plus utilisées.
Après une longue période de stagnation, le protocole
HTTP ne cesse de se mettre à jour. L’objectif visé étant la
rapidité et la sécurité.
| Version | Date | Description |
|---|---|---|
HTTP/0.9 |
1991 | La première version qui ne supporte que la méthode
GET. |
HTTPS |
1994 | La version qui ajoute le chiffrement TLS. |
HTTP/1.0 |
1996 | La version qui supporte les méthodes GET,
HEAD et POST. |
HTTP/1.1 |
1997 | Ajout du champ Host permettant le multi-hébergement. |
HTTP/2 |
2015 | La version qui apporte le multiplexage, la compression des headers et le Push du serveur. |
HTTP/3 |
2020 | La version qui utilise UDP à la place de TCP et qui gère le chiffrement TLS en interne. |
1.1Dans son fonctionnement de base, le protocole HTTP/1.1
utilise une connexion TCP au dessus de laquelle il va coupler le
chiffrement TLS. Le protocole TCP requière 3 paquets pour la
synchronisation, SYN, SYN-ACK et
ACK. Le protocole TLS quand à lui demande 5 paquets pour
l’échange des clés et des certificats. On peut donc dire que chaque
connexion utilisera au minimum 8 échanges avant même de savoir ce que
l’on veut faire. De plus, TCP va divisé une grosse resource en plusieurs
petits paquets et pour chaque paquet, il va demander un ACK
pour s’assurer que le paquet est bien arrivé.
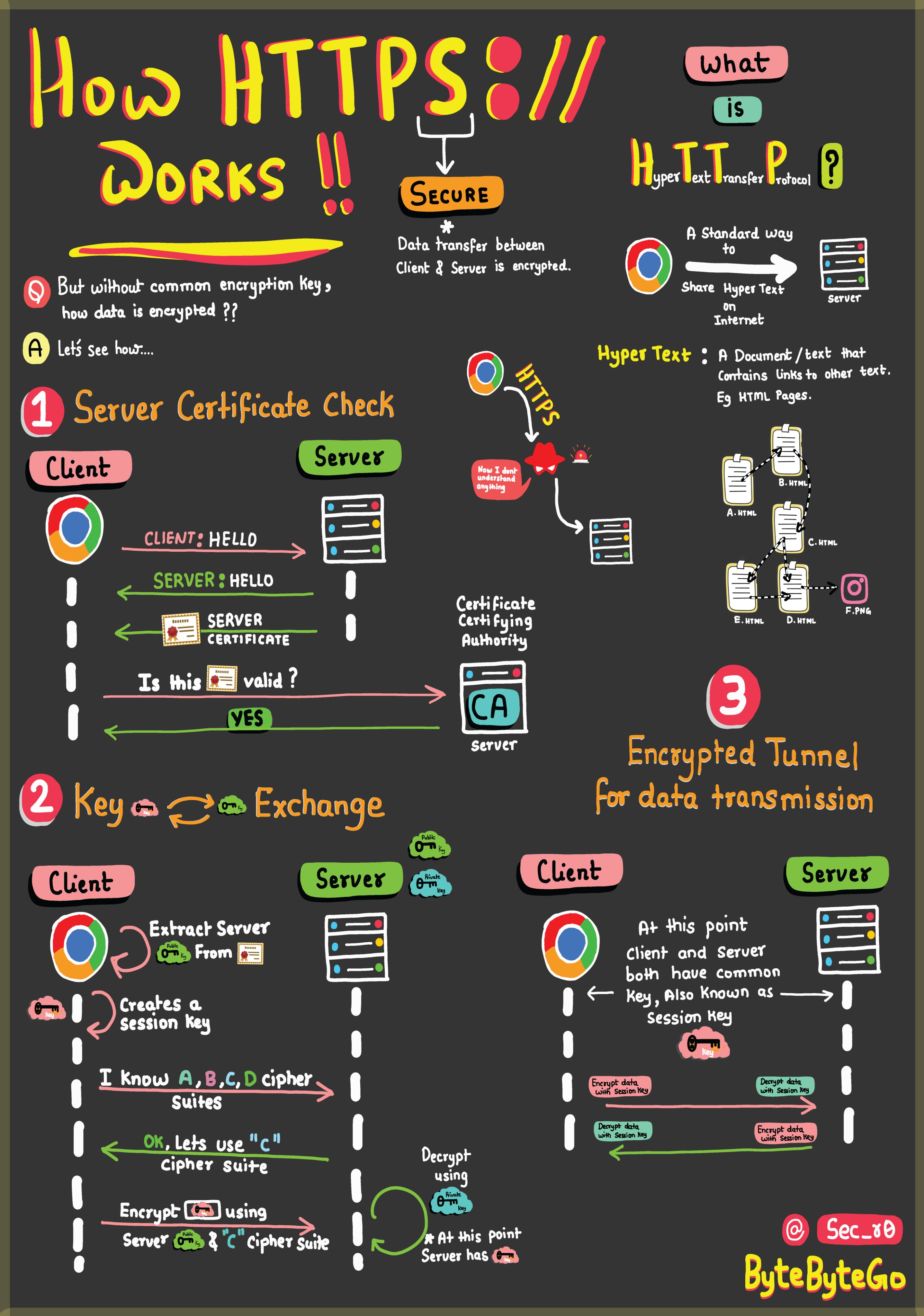
Lors de l’appel de la page d’accueil du CPNE-TI, ça donne quelque chose comme ceci:
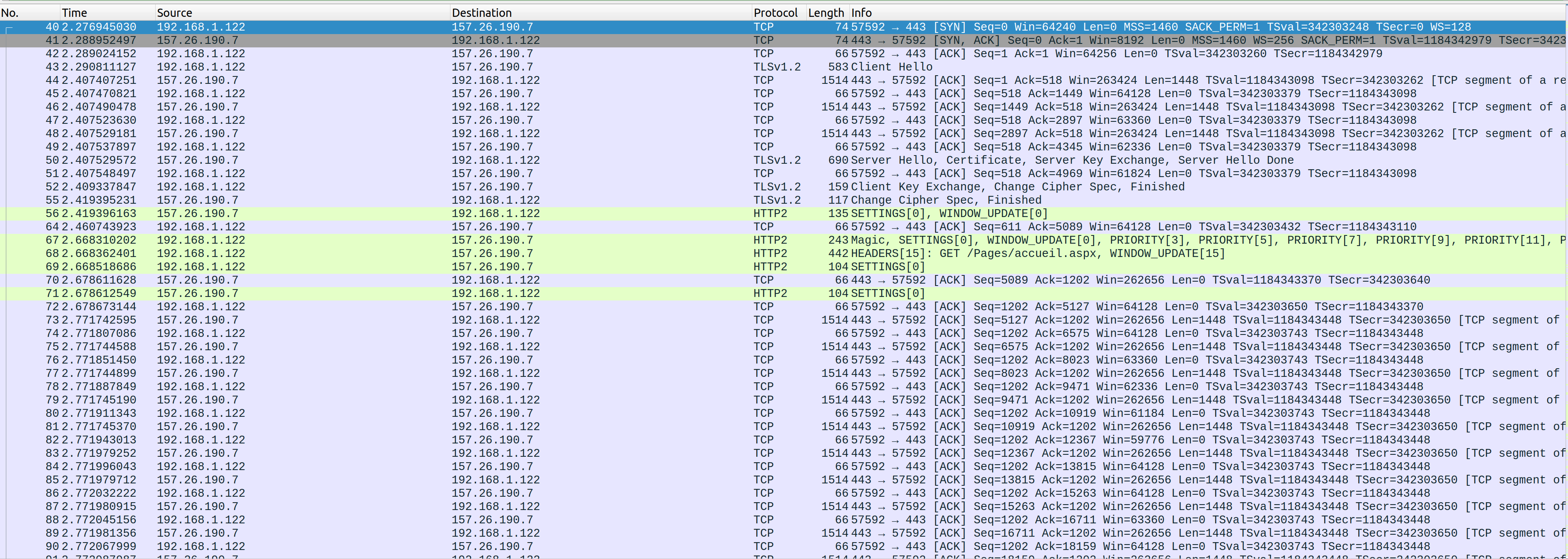
On peut y voir les 3 premiers paquets qui correspondent à l’ouverture
de la connexion TCP. Juste après, on trouve le premier paquet TLS
Client Hello. Ce paquet va demander par moins de 6 ACK,
signe que le Client Hello à été divisé en plusieurs
parties. On trouve ensuite la réponse du serveur TLS
Server Hello suivit des échanges de clés. La première
requête HTTP se trouve en 15ème position et la requête
GET pour l’obtention de la page d’accueil ne se trouve
qu’en 18ème position. On peut également voir le nombre d’ACK qui suivent
la demande de la page d’accueil.
si vous faite le même travail sur votre poste, vous ne verrez pas le contenu des paquets TLS et c’est normal vu qu’ils sont chiffrés. J’ai fait en sorte de voir leur contenu avant de lancer Wireshark 😎
Ce protocole souffre de plusieurs défauts:
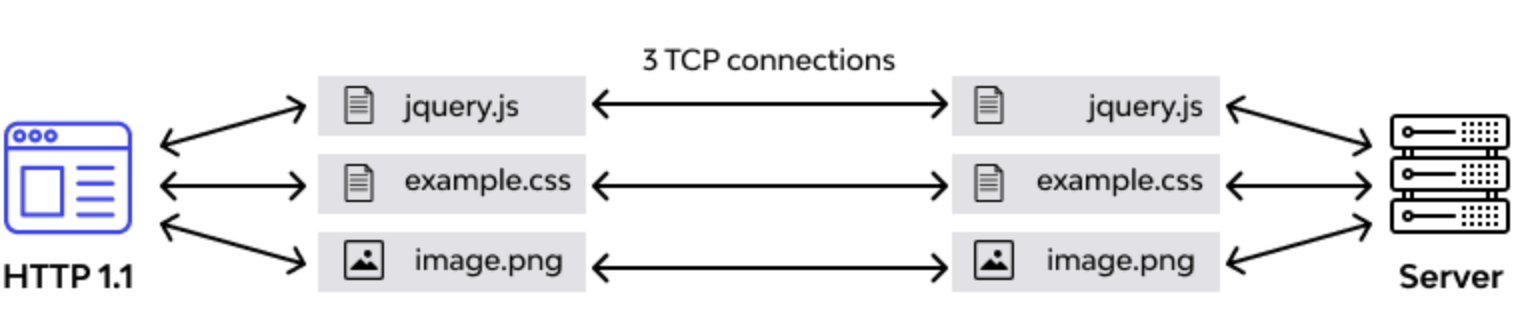
2La version HTTP/2 est une évolution de la version
HTTP/1.1. Il utilise toujours TCP mais il va utiliser le
multiplexage pour envoyer plusieurs resources en même temps sur la même
connexion. HTTP/2 force l’utilisation du chiffrement et
peut compresser les entêtes HTTP. Il peut également pousser (PUSH) des
resources au client sans que celui-ci ne les demande.

3L’idée du protocole HTTP 3 c’est d’utiliser UDP en lieu et place de TCP et de gérer en interne la partie chiffrement TLS. UDP ne demande pas de synchronisation et ne demande pas d’ACK. Il est donc plus rapide que TCP. De plus, HTTP/3 va utiliser le multiplexage pour envoyer plusieurs requêtes en même temps sur la même connexion. C’est ce que fait déjà HTTP/2 mais HTTP/3 va encore plus loin en envoyant les requêtes dans le désordre et en les réordonnant à l’arrivée. Cela permet de ne pas bloquer une requête qui prendrait plus de temps que les autres.
Tout ça semble très prometteur sur papier mais dans les faits ? 🤔 Difficile d’établir un protocole de test parfaitement fiable mais voici un comparatif qu’un utilisateur pourrait faire entre les 3 versions.
| Protocole | Nb requêtes | Taille | Durée | Requête |
|---|---|---|---|---|
| HTTP/1.1 | 50 | 6.35MB | 3.53s | https://www.google.com/search?q=linux |
| HTTP/2 | 47 | 6.18MB | 2.53s | https://www.google.com/search?q=linux |
| HTTP/3 | 46 | 6.17MB | 2.31s | https://www.google.com/search?q=linux |
| HTTP/1.1 | 70 | 3.96MB | 4.21s | Idem mais onglet images |
| HTTP/2 | 66 | 3.92MB | 3.87s | Idem mais onglet images |
| HTTP/3 | 66 | 3.92MB | 3.90s | Idem mais onglet images |
Méthode de test:
Dans un navigateur firefox, désactiver http3, http2 et quic dans “about:config”.
Dans ma méthode extrêmement basique, on ne voit pas une énorme différence. Dans l’emploi quotidien, il ne faut pas s’attendre à des vitesses foudroyantes. Cependant, avec un protocole de test plus abouti et un réseau mobile de piètre qualité, on constate quand même des différences notables.
La Transport Layer Security (TLS) ou « Sécurité de la couche de transport », et son prédécesseur la Secure Sockets Layer (SSL) ou « Couche de sockets sécurisée »1, sont des protocoles de sécurisation des échanges par réseau informatique, notamment par Internet. Le protocole SSL a été développé à l’origine par Netscape Communications Corporation pour son navigateur Web. L’organisme de normalisation Internet Engineering Task Force (IETF) en a poursuivi le développement en le rebaptisant Transport Layer Security (TLS). On parle parfois de SSL/TLS pour désigner indifféremment SSL ou TLS.
La TLS (ou SSL) fonctionne suivant un mode client-serveur. Il permet de satisfaire les objectifs de sécurité suivants :
Le protocole est très largement utilisé, et sa mise en œuvre est facilitée par le fait que les protocoles de la couche application, comme le HTTP, n’ont pas à être profondément modifiés pour utiliser une connexion sécurisée, mais seulement implémentés au-dessus de la SSL/TLS, ce qui pour le HTTP a donné le protocole HTTPS.
Pour comprendre la mise en oeuvre du chiffrement TLS, il faut comprendre chacun des principes qui le composent.
On nomme fonction de hachage, de l’anglais hash function, une fonction particulière qui, à partir d’une donnée fournie en entrée, calcule une empreinte numérique servant à identifier rapidement la donnée initiale, au même titre qu’une signature pour identifier une personne. Les fonctions de hachage sont utilisées en informatique et en cryptographie notamment pour reconnaître rapidement des fichiers ou des mots de passe.
Souvent considérer à tort comme une fonction de chiffrement, les fonctions de hachage sont irréversibles. Elles ne font le travail que dans un sens. On peut facilement comprendre cela avec l’exemple qui est donnée sur le site de wikipedia. Pour leur exemple, il prenne le texte du livre Vingt mille lieues sous les mers en libre consultation et il en crée une empreinte numérique de type MD5. On peut facilement reproduire cette exemple ainsi:
$ wget --output-document=20milles.txt http://www.gutenberg.org/files/54873/54873-0.txt
--2020-12-17 16:43:22-- http://www.gutenberg.org/files/54873/54873-0.txt
Résolution de www.gutenberg.org (www.gutenberg.org)… 2610:28:3090:3000:0:bad:cafe:47, 152.19.134.47
Connexion à www.gutenberg.org (www.gutenberg.org)|2610:28:3090:3000:0:bad:cafe:47|:80… connecté.
requête HTTP transmise, en attente de la réponse… 200 OK
Taille : 955890 (933K) [text/plain]
Enregistre : «20milles.txt»
20milles.txt 100%[===================================================>] 933.49K 835KB/s ds 1.1s
2020-12-17 16:43:24 (835 KB/s) - «20milles.txt» enregistré [955890/955890]Grâce aux messages du téléchargement, nous pouvons directement savoir combien il y a d’octets dans ce fichier ; 955890 octets.
On peut maintenant créer une empreinte numérique de type MD5 ainsi:
$ md5sum 20milles.txt
172d6a9aeea4bf2eea9deaa6c3edde88 20milles.txtCette empreinte est unique c’est-à-dire que si vous changez un seul caractère parmi les 955890, même si ce changement ne porte que sur 1 bit, alors l’empreinte sera complètement différente.
Dans le fichier 20milles.txt je vais remplacer un seul ‘a’ par un ‘c’.
Par exemple:
L’année 1866 fut marquée…
Par
L’cnnée 1866 fut marquée…
Du point de vue binaire je n’aurai changé qu’un seul bit puisque selon la table ASCII:
En générant la nouvelle empreinte on obtient:
$ md5sum 20milles.txt
5dbbf02429e89c2edfc0d763e9e527b0 20milles.txtFonction inverse ?
Il est facile de comprendre qu’en partant des 16 octets de l’empreinte il me sera impossible de reconstruire tout le livre.
La fonction de hachage MD5 est maintenant connue pour ne pas être fiable. Elle souffre de plusieurs maux.

Dans le cas d’un mot de passe haché cela revient à tester toutes les combinaisons de texte jusqu’à trouver celle qui donne la même empreinte.
Si je vous dis: l’empreinte de mon mot de passe est 3ffb51be62aab6610d53e0d88413ab83. Pour trouver mon mot de passe, vous devrez tester toutes les combinaisons de lettres, chiffres et caractères spéciaux possibles.
$ md5sum aaaa ?= '3ffb51be62aab6610d53e0d88413ab83'
$ md5sum aaab ?= '3ffb51be62aab6610d53e0d88413ab83'
$ md5sum aaac ?= '3ffb51be62aab6610d53e0d88413ab83'
...
$ md5sum AAAA ?= '3ffb51be62aab6610d53e0d88413ab83'
$ md5sum AAAB ?= '3ffb51be62aab6610d53e0d88413ab83'
$ md5sum AAAC ?= '3ffb51be62aab6610d53e0d88413ab83'
...
$ md5sum aaa1 ?= '3ffb51be62aab6610d53e0d88413ab83'
$ md5sum aaa2 ?= '3ffb51be62aab6610d53e0d88413ab83'
$ md5sum aaa3 ?= '3ffb51be62aab6610d53e0d88413ab83'
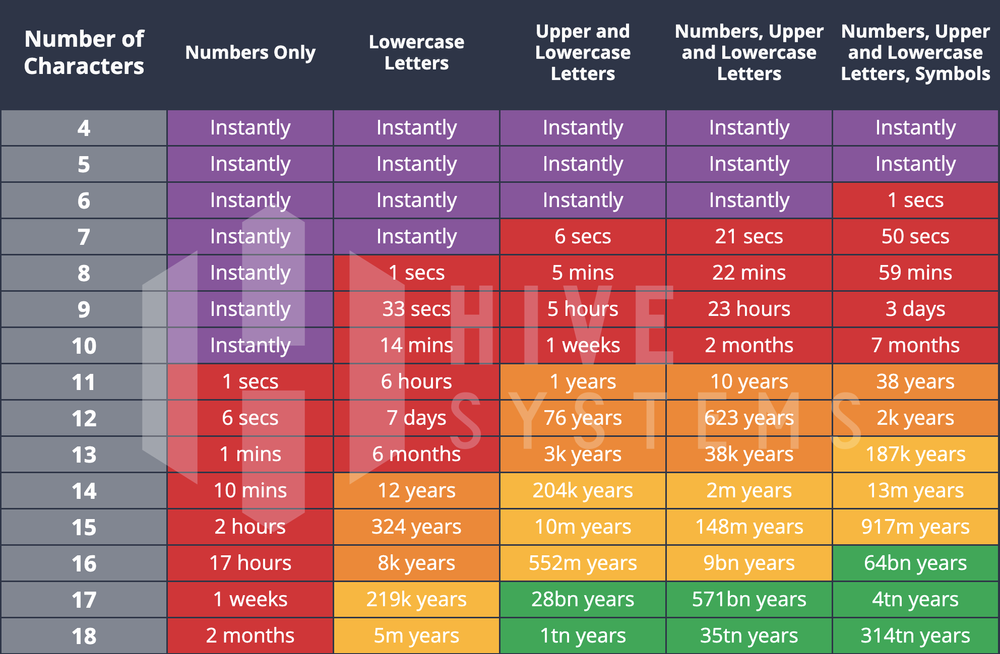
...Avec 95 caractères, alphanumériques [a-zA-Z0-9] auxquels on ajoute
les caractères spéciaux [._!{} etc], on obtient:
Pour n caractères dans le mot de passe :
Soit quelques millions d’années pour arriver à tester toutes les possibilités de mon mot de passe de 16 caractères.
Selon ce site, pour tester toutes les possibilités d’un mot de passe de 8 caractères composé aléatoirement de lettre MAJUSCULE et minuscule, de chiffre et de symbols il faut:
Il faut actuellement (2024) utiliser des mots de passe d’au minimum 12 caractères (2k années) pour être à l’abri d’une attaque par force brute avec une carte graphique courante RTX4090.
Les fonctions d’empreintes numériques peuvent souffrir de collision. Une collision c’est le faite d’avoir deux entrées différentes qui produisent le même résultat. Voyez plutôt l’exemple expliqué ici
d131 devient 31d1 dans le fichier. C’est
normal. On est en petit-boutisme avec
les architectures x86-64
$ echo -n "d131dd02c5e6eec4693d9a0698aff95c2fcab58712467eab4004583eb8fb7f8955ad340609f4b30283e488832571415a085125e8f7cdc99fd91dbdf280373c5bd8823e3156348f5bae6dacd436c919c6dd53e2b487da03fd02396306d248cda0e99f33420f577ee8ce54b67080a80d1ec69821bcb6a8839396f9652b6ff72a70" | xxd -r -p > block1.bin
$ hexdump block1.bin
0000000 31d1 02dd e6c5 c4ee 3d69 069a af98 5cf9
0000010 ca2f 87b5 4612 ab7e 0440 3e58 fbb8 897f
0000020 ad55 0634 f409 02b3 e483 8388 7125 5a41
0000030 5108 e825 cdf7 9fc9 1dd9 f2bd 3780 5b3c
0000040 82d8 313e 3456 5b8f 6dae d4ac c936 c619
0000050 53dd b4e2 da87 fd03 3902 0663 48d2 a0cd
0000060 9fe9 4233 570f e87e 54ce 70b6 a880 1e0d
0000070 98c6 bc21 a8b6 9383 f996 2b65 f76f 702a
0000080
$ echo -n "d131dd02c5e6eec4693d9a0698aff95c2fcab50712467eab4004583eb8fb7f8955ad340609f4b30283e4888325f1415a085125e8f7cdc99fd91dbd7280373c5bd8823e3156348f5bae6dacd436c919c6dd53e23487da03fd02396306d248cda0e99f33420f577ee8ce54b67080280d1ec69821bcb6a8839396f965ab6ff72a70" | xxd -r -p > block2.bin
$ hexdump block2.bin
0000000 31d1 02dd e6c5 c4ee 3d69 069a af98 5cf9
0000010 ca2f 07b5 4612 ab7e 0440 3e58 fbb8 897f
0000020 ad55 0634 f409 02b3 e483 8388 f125 5a41
0000030 5108 e825 cdf7 9fc9 1dd9 72bd 3780 5b3c
0000040 82d8 313e 3456 5b8f 6dae d4ac c936 c619
0000050 53dd 34e2 da87 fd03 3902 0663 48d2 a0cd
0000060 9fe9 4233 570f e87e 54ce 70b6 2880 1e0d
0000070 98c6 bc21 a8b6 9383 f996 ab65 f76f 702a
0000080
$ md5sum block*
79054025255fb1a26e4bc422aef54eb4 block1.bin
79054025255fb1a26e4bc422aef54eb4 block2.binLes deux chaînes de caractères vous paraissent identiques ? Et pourtant, en y regardant de plus près on peu voir les différences.
d131dd02c5e6eec4693d9a0698aff95c2fcab58712467eab4004583eb8fb7f89 55ad340609f4b30283e488832571415a085125e8f7cdc99fd91dbdf280373c5b d8823e3156348f5bae6dacd436c919c6dd53e2b487da03fd02396306d248cda0 e99f33420f577ee8ce54b67080a80d1ec69821bcb6a8839396f9652b6ff72a70
Et
d131dd02c5e6eec4693d9a0698aff95c2fcab50712467eab4004583eb8fb7f89 55ad340609f4b30283e4888325f1415a085125e8f7cdc99fd91dbd7280373c5b d8823e3156348f5bae6dacd436c919c6dd53e23487da03fd02396306d248cda0 e99f33420f577ee8ce54b67080280d1ec69821bcb6a8839396f965ab6ff72a70
Un exemple plus parlant peut-être réalisé avec ces deux images qui sont complètement différentes et qui pourtant, produise la même empreinte MD5 (clique droite / enregistrer sous):


$ md5sum plane.jpg
253dd04e87492e4fc3471de5e776bc3d plane.jpg
$ md5sum ship.jpg
253dd04e87492e4fc3471de5e776bc3d ship.jpgIl existe des mots de passe qui une fois haché en MD5 fournissent une empreinte qui permet de se connecter sans connaître le mot de passe. C’est ce qu’on appelle un magic hash.
Imaginons que votre mot de passe soit HFS_9/rKCeq8tcY9.
Vous vous pensez à l’abri car il contient 16 caractères de toutes les
familles. Malheureusement, une conjonction de deux éléments va jouer
contre vous.
Le premier élément:
une fois haché en MD5, le mot de passe HFS_9/rKCeq8tcY9
donne l’empreinte 0e632684922796334502827808200584. C’est
cette empreinte qui est stockée dans la base de donnée.
db_users
| id | username | password |
|---|---|---|
| 1 | admin | 0e632684922796334502827808200584 |
Le deuxième élément:
Le codeur de l’application web a fait une erreur de débutant. Il
compare les deux empreintes en utilisant l’opérateur == au
lieu d’utiliser l’opérateur ===.
$password_from_db = $model_user->getUser('admin')->password; // HFS_9/rKCeq8tcY9
$password_from_user = $_POST['password']; // 0
if ($password_from_db == $password_from_user) {
$logued = true;
print "Welcome admin";
}L’empreinte obtenue est un magic hash qui
permet de se connecter sans connaître le mot de passe. Pourquoi ? Et
bien parce que le hash commence par 0e et que PHP considère
que 0e est égal à 0. Il suffit donc de se
connecter avec le mot de passe 0 pour être authentifié.
Il s’agit ici d’un problème PHP mais il existe des problèmes similaires pour d’autres langages de programmation et pour d’autres fonctions de hachage. Vous trouverez une liste non exhaustive spécifique au PHP ici.
C’est pour toutes ces raisons que l’empreinte de type MD5 a été abandonnée au profit d’empreinte de type SHA-256
Le chiffrement XOR est un chiffrement bit à bit qui utilise les propriétés mathématiques de la fonction OU EXCLUSIF notamment cette égalité
On peut également le représenter sous forme de table de vérité:
| A | B | A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Ce chiffrement n’est plus acceptable de nos jours mais il met en évidence le principe d’un chiffrement symétrique. C’est-à-dire que la même clé est utilisée pour chiffrer et déchiffrer. Par exemple (table de codage Windows-1252):
| Opération XOR, se lit de haut en bas ↓ | ||||||||
|---|---|---|---|---|---|---|---|---|
Valeur en claire (0x70 → p) ↓ |
0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
Clé (0x95) ↓ |
1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
Valeur chiffrée (0xe5 → å) ↓ |
1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 |
Clé (0x95) ↓ |
1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
Valeur en claire (0x70 → p) |
0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
Le chiffrement AES aussi connu sous le nom Rijndael est un chiffrement symétrique. C’est-à-dire que les deux parties utilisent la même clé de chiffrement pour chiffrer et déchiffrer. L’algorithme ainsi que les tables intermédiaires sont connus.
L’algorithme prend en entrée un bloc de 128 bits (16 octets), la clé fait 128, 192 ou 256 bits. Les 16 octets en entrée sont permutés selon une table définie au préalable. Ces octets sont ensuite placés dans une matrice de 4x4 éléments et ses lignes subissent une rotation vers la droite. L’incrément pour la rotation varie selon le numéro de la ligne. Une transformation linéaire est ensuite appliquée sur la matrice, elle consiste en la multiplication binaire de chaque élément de la matrice avec des polynômes issus d’une matrice auxiliaire, cette multiplication est soumise à des règles spéciales selon GF(28) (groupe de Galois ou corps fini). La transformation linéaire garantit une meilleure diffusion (propagation des bits dans la structure) sur plusieurs tours.
Finalement, un OU exclusif XOR entre la matrice et une autre matrice permet d’obtenir une matrice intermédiaire. Ces différentes opérations sont répétées plusieurs fois et définissent un « tour ». Pour une clé de 128, 192 ou 256, AES nécessite respectivement 10, 12 ou 14 tours.
Tout la sécurité repose donc sur le secret, c’est-à-dire, sur la clé.
on peut utiliser l’outil openssl pour montrer le
fonctionnement du chiffrement AES.
On commence par créer un fichier texte contenant un message de votre
choix. Le fichier texte se nomme message.txt.
$ echo "Ceci est mon message" > message.txt
$ cat message.txt
Ceci est mon messageOn va maintenant chiffrer ce fichier en utilisant AES en mode CBC avec une clé de 256 bits. Comme on ne souhaite pas imaginer 256 bits aléatoires on va demander à l’outil de dériver (de créer) une clé et un vecteur d’initialisation pour nous. Pour cela, l’outil nous demandera un texte, faussement appeler password duquel il dérivera, grâce à la méthode pbkdf2, la clé et le vecteur.
On peut également choisir nous même un clé key et un
vecteur iv mais dans le monde du chiffrement, il est
préférable de laisser faire l’outil car vous ne connaissez pas toutes
les subtilitées. Lisez simplement la partie Vecteur
d’initialisation.
Génération de la clé et du vecteur d’initialisation
$ openssl enc -aes-256-cbc -nosalt -pass pass:Pass1234 -P -pbkdf2
key=9ECD8AEE26BAD7778C4AFC42CF3FA81DCD1F5D05F1198CE7CC98CEC6A7205912
iv =71E2E67597110B892039A210656E0B9FLe vecteur iv permet d’avoir un chiffrement différent à
chaque fois même si le message est le même. Par contre, le couple
key, iv ne doit exister qu’une seule fois. Ce
doit être un nonce. Si
vous souhaitez réutiliser la même clé il faudra régénérez un nouveau
vecteur d’initialisation.
un nouveau fichier message.enc peut également être créer
avec le texte chiffrer à l’intérieur. Le vecteur iv est
nécessaire au démarrage du chiffrement. En effet, le premier bloc de 128
bits du message est chiffré en utilisant le vecteur d’initialisation.
Les blocs suivants sont chiffrés en utilisant le bloc précédent. Le
vecteur d’initialisation est donc nécessaire pour commencer
l’opération.
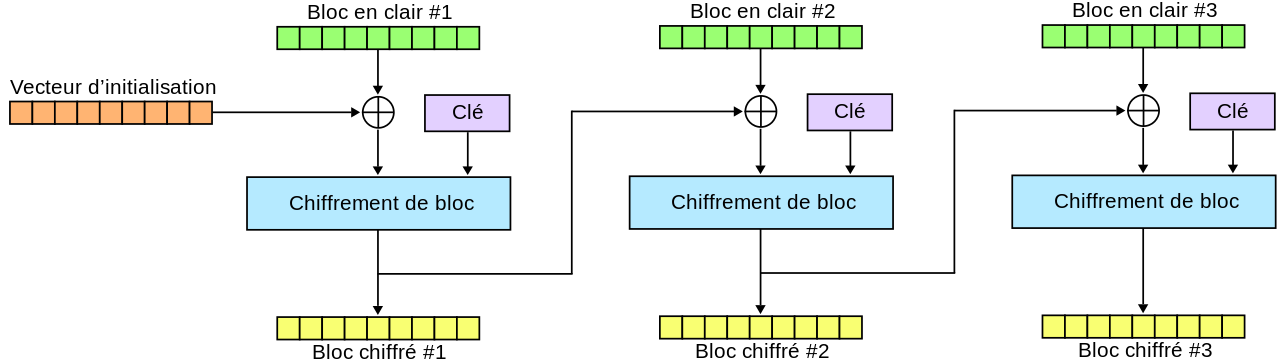
Chiffrement
$ openssl enc -aes-256-cbc -a -nosalt -in message.txt -out message.enc -K 9ECD8AEE26BAD7778C4AFC42CF3FA81DCD1F5D05F1198CE7CC98CEC6A7205912 -iv 71E2E67597110B892039A210656E0B9F
## Le message est encodé en base64 pour être affiché dans le terminal. C'est l'option -a qui fait ça.
$ cat message.enc
2ItzO/jfjebh6P+rS6ekDoKnxkpgiMhN+LRJoYoGycY=
## Sinon c'est pas vraiment affichable
$ cat message.enc | base64 -d
؋s;�ߍ�����K�����J`��M��I����pLa clé et le vecteur d’initialisation sont les secrets à conserver
précieusement. Il faut également les fournir à la personne qui sera
censé pouvoir déchiffrer le fichier message.enc.
Déchiffrement
Pour déchiffrer, on peut utiliser le même utilitaire
$ openssl enc -d -aes-256-cbc -a -nosalt -in message.enc -out decrypt.txt
-K 9ECD8AEE26BAD7778C4AFC42CF3FA81DCD1F5D05F1198CE7CC98CEC6A7205912
-iv 71E2E67597110B892039A210656E0B9F
$ cat decrypt.txt
Ceci est mon messageOn comprend tout de suite que dans le cas d’un échange de message
chiffré entre Alice et Bob qui se trouvent éloignés l’un de l’autre, la
difficulté sera de faire passer les secrets key,
iv entre les deux personnes.
Le chiffrement asymétrique repose sur deux clés. Une clé privée et une clé publique. La clé privée est secrète et ne doit être connue que de son propriétaire. La clé publique est diffusée à tout le monde. La clé privée permet de chiffrer et de signer. La clé publique permet de déchiffrer et de valider une signature.
Le chiffrement asymétrique est bidirectionnel. Dans un sens on parle de chiffrement alors que dans l’autre sens on parle de signature. Le principe de fonctionnement reste le même.
Pour comprendre comment il fonctionne, réalisons les deux opérations en utilisant les clés proposées sur la page wikipedia.
La clé publique d’Alice est (n, e) = (33, 3), et sa clé privée est (n, d) = (33, 7).
Avant de commencer, il faut comprendre qu’un message, quel qu’il
soit, est toujours divisé en blocs de bits de taille fixe. Chaque bloc
peut alors être vu comme une valeur entière indépendament de ce qu’il
représente à la base. Par exemple, une image de 10x10 pixels RGBA (4
octets par pixel) peut être vue comme une suite de 400 octets. Les 400
octets peuvent être divisés en paquet de 32 bits et donc comme un
Int32. Cela fait 100 valeurs entières.
Dans l’exemple, et pour faire vraiment simple, Bob veut transmettre
le message 4 à Alice. Il va chercher sur Internet la clé
publique d’Alice et réalise les opérations suivante:
Alice reçoit alors le message 31 qu’elle seul peut
déchiffrer grâce à sa clé privée ainsi:
Alice retrouve alors le message original de Bob, à savoir
4.
Alice veut prouver à Bob que c’est elle qui a écrit un message. Pour
ce faire elle utilise sa clé privée qu’elle est la seule à posséder et
elle crée une signature du message qu’elle a écrit. Prenons comme
message 8:
Elle diffuse le message 8 ainsi que le chiffré
2 à Bob (et au monde entier). Bob veut vérifier que c’est
bien Alice qui a écrit le message 8. Il se rend sur
Internet et trouve la clé publique d’Alice. Il utilise alors cette clé
publique pour validée que le chiffré a été calculé avec la clé privée
d’Alice:
Comme le calcul utilisant la signature d’Alice et la clé publique d’Alice donne le même résultat que le message qu’Alice à diffusé, Bob peut être sûr que c’est bien Alice qui l’a écrit.
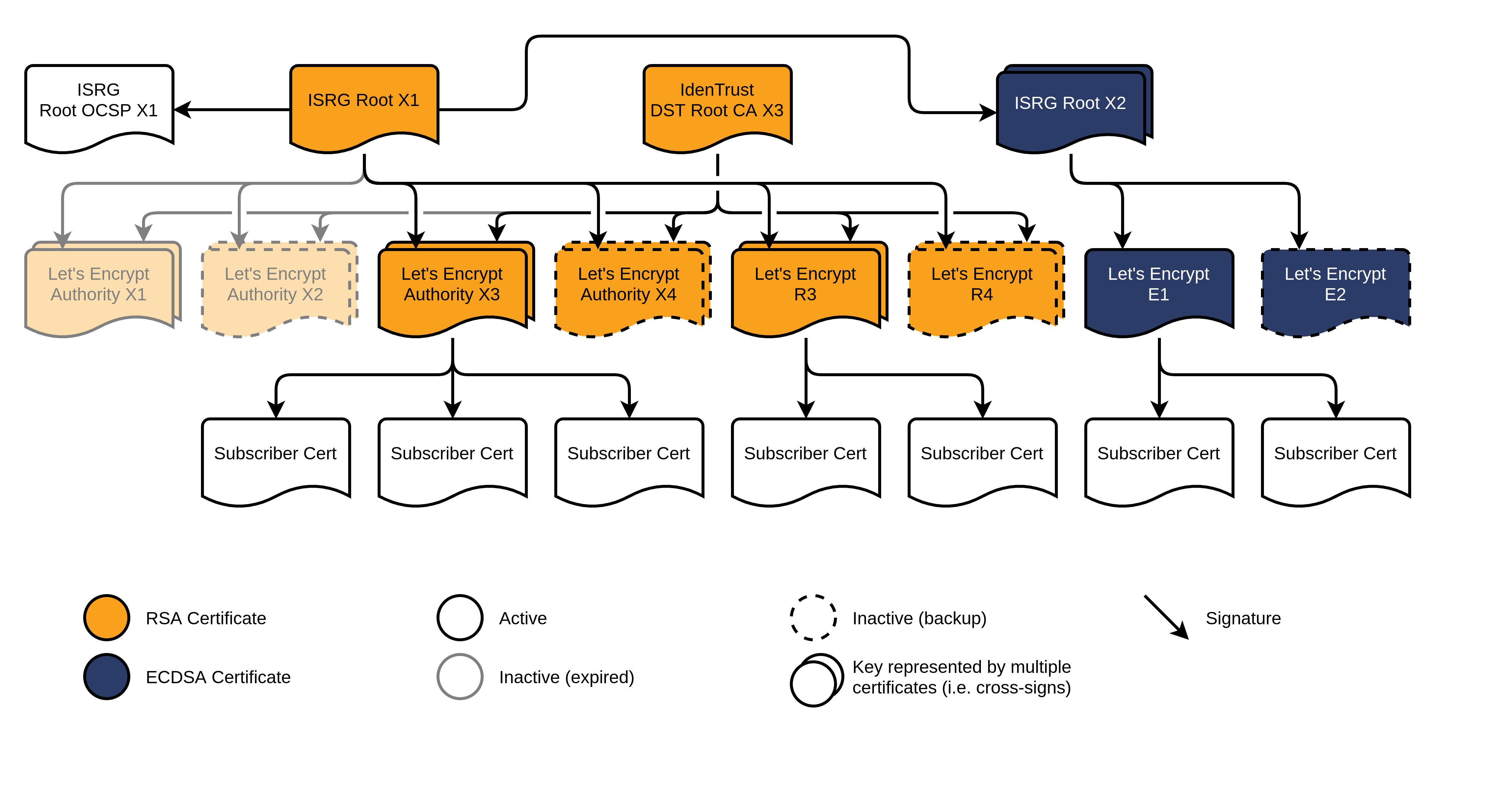
Prenons l’exemple du certificat piferrari.org délivré par Let’s Encrypt.
Dans cette hiérarchie, le certificat de piferrari.org se trouve tout en bas. Il
fait partie des Subscriber Cert. Il appartient donc à la Chain of
trust incluant piferrari.org ↢ R3 ↢ ISRG Root X1. Ça
signifie que piferrari.org est
certifié par R3 qui est
lui-même certifié par ISRG Root X1.
Voyons les étapes à réaliser pour valider un certificat.
Pour récupérer le certificat on peut utiliser plusieurs techniques tel que:
openssl pour télécharger le certificatC’est cette solution qui est montrée ci-dessous.
$ openssl s_client -connect piferrari.org:443
...
-----BEGIN CERTIFICATE-----
MIIFJjCCBA6gAwIBAgISBM6mEuAPcp7S698c52Exl1l3MA0GCSqGSIb3DQEBCwUA
MDIxCzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MQswCQYDVQQD
EwJSMzAeFw0yMDEyMTIwMjIyMTJaFw0yMTAzMTIwMjIyMTJaMBMxETAPBgNVBAMT
CGRydWlkLmVzMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAuM49uSSM
NREXiKTBUsGJ+rOPTOX+8t8qxPQ5ysyRaRP1wVaRuw/tfW8KHwR4YdJPsddymZvy
qkhOCB7tDKjU+0hMGSmMRBZnmlJotx5PF9VFDiHz8NtoUvLZBkIi8IwlOnNkLs48
HVW9Sbipn+n0wlzu7isMEpFdvFVCFCnsZoenE+lr38gG94OhEgVnpoVJgVhyZV+h
nvCXnhXrMEWEFVN1Mhi0yV5LtpHfLyBpeOOTsldyVVfxcCjT+i9M4vobkeDRx2L+
RKhairJGimaND33lkktxT3NEMEk7A5lvCgOVrgysBev7aeCuFZ0xSoHP7dGZAeJ0
/U/nTiPYb7wsrwIDAQABo4ICUzCCAk8wDgYDVR0PAQH/BAQDAgWgMB0GA1UdJQQW
MBQGCCsGAQUFBwMBBggrBgEFBQcDAjAMBgNVHRMBAf8EAjAAMB0GA1UdDgQWBBTV
UgXEK4UuVKcWEM/Asasg2o+4HTAfBgNVHSMEGDAWgBQULrMXt1hWy65QCUDmH6+d
ixTCxjBVBggrBgEFBQcBAQRJMEcwIQYIKwYBBQUHMAGGFWh0dHA6Ly9yMy5vLmxl
bmNyLm9yZzAiBggrBgEFBQcwAoYWaHR0cDovL3IzLmkubGVuY3Iub3JnLzAhBgNV
HREEGjAYgghkcnVpZC5lc4IMd3d3LmRydWlkLmVzMEwGA1UdIARFMEMwCAYGZ4EM
AQIBMDcGCysGAQQBgt8TAQEBMCgwJgYIKwYBBQUHAgEWGmh0dHA6Ly9jcHMubGV0
c2VuY3J5cHQub3JnMIIBBgYKKwYBBAHWeQIEAgSB9wSB9ADyAHcAlCC8Ho7VjWyI
cx+CiyIsDdHaTV5sT5Q9YdtOL1hNosIAAAF2VPhg1wAABAMASDBGAiEA7LtamkFh
o4kDJCoDmLXifpgCslhigQvY1feKqtVxovMCIQDXfjEfXILKCjcTv8Yt9tPNbZKc
ipUvy9zSDCApnI2oPwB3AH0+8viP/4hVaCTCwMqeUol5K8UOeAl/LmqXaJl+IvDX
AAABdlT4YPcAAAQDAEgwRgIhAPpX8ZVFutGnWLeo7MFGL15NxeWty+l1g97+OxE4
WPdJAiEAkt6/N1nEIVKcS3O8Yc7epmUAUUrkbdoBtumM6Kltm3AwDQYJKoZIhvcN
AQELBQADggEBAJeixyzaDBLZlP0IpzmoaTpO7vU66qqGCVcXZ0n5xTTX8KU/Ab6x
RtRvaPVuhLrD+9ykc/oAQa75cJ2pNUye/sC/VdRj0n7Wx3pO/NFogl/iSQuwbucf
WLzyaI4Ytt2p1IB22QFq9/ok1Gm4qCYnh6WMwbalyV1be/iLG9IUSwa2YlkjQT+d
GltpCuNIIx48b+RUPDzt5bntrd4PKpaa7tNUxXQkPrKveAdBOlB6+Yy2v+p1d+xz
ndULhqINJ0TmZqyEdnuBr2IzF/tbRtfzjocwV8a0fbGGTQk5k27RT93tC+1c2xqB
fxuLg5sr57ZR4Ur4ku4qTm21aQevFDZ/WNQ=
-----END CERTIFICATE-----
...Le certificat est affiché ici en base64 c’est-à-dire uniquement avec des caractères ASCII. C’est comme ça que le navigateur le reçoit. Bon, et après ?
Voyons ce qu’il y a dedans. On commence par mettre le contenu du
certificat dans un fichier que l’on nomme piferrari.org.pem
puis on utilise l’outil openssl pour afficher ce certificat
en mode texte lisible.
$ openssl x509 -in piferrari.org.pem -text
...
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = US, O = Let's Encrypt, CN = R3
Subject: CN = piferrari.org
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
RSA Public-Key: (2048 bit)
Modulus:
00:b8:ce:3d:b9:24:8c:35:11:17:88:a4:c1:52:c1:
...
Exponent: 65537 (0x10001)
Signature Algorithm: sha256WithRSAEncryption
97:a2:c7:2c:da:0c:12:d9:94:fd:08:a7:39:a8:69:3a:4e:ee:
...On y trouve:
Signature Algorithm)Issuer)Subject)Subject Public Key Info)Signature Algorithm)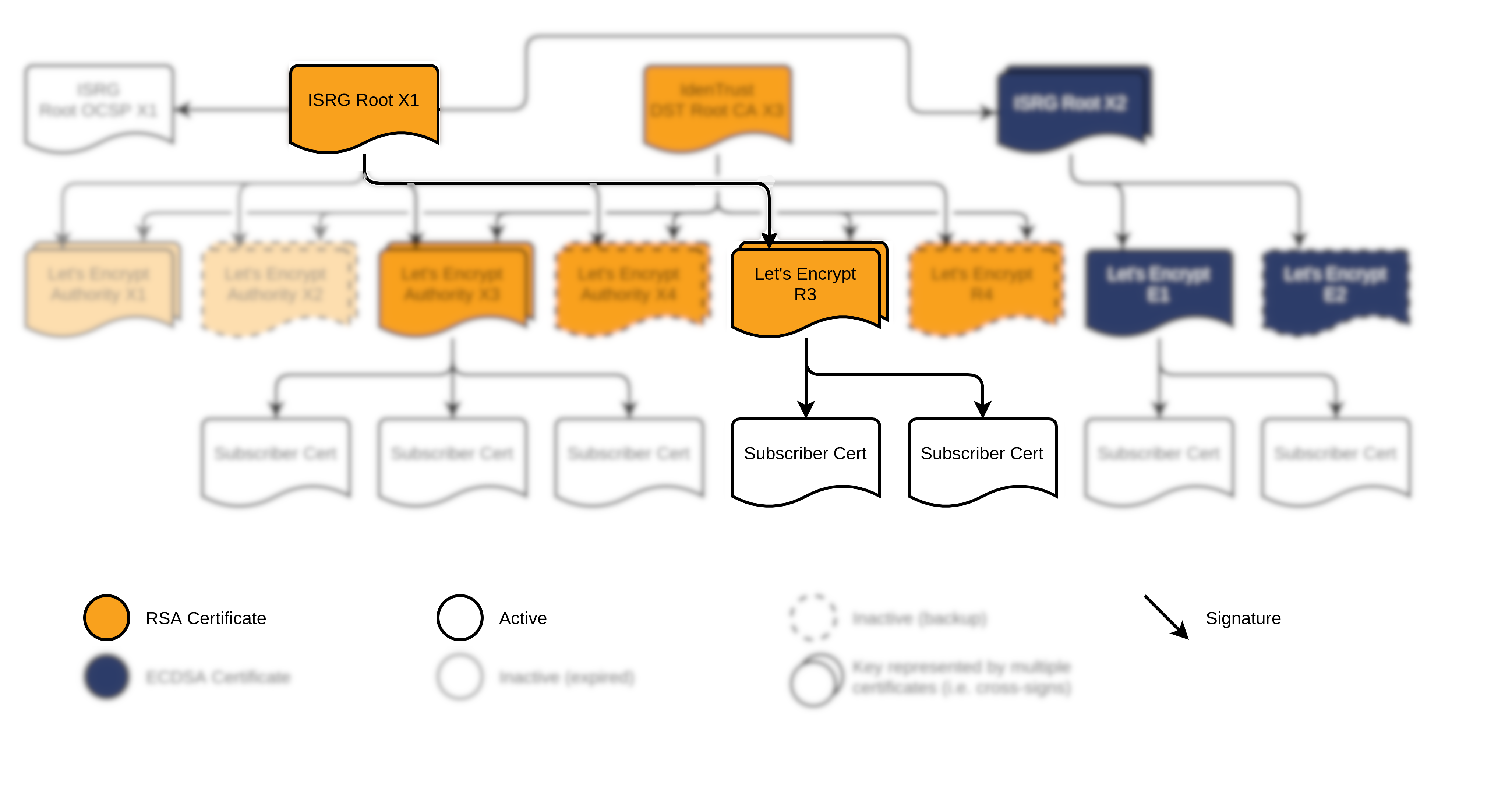
Selon le schéma fournit par Let’s Encrypt, on peut voir que l’autorité qui a délivré le certificat est la branche R3, elle-même étant certifié par l’autorité racine ISRG Root X1. C’est donc la clé publique de R3 qui a été utilisée pour signé le certificat de piferrari.org et c’est la clé publique de ISRG Root X1 qui a été utilisée pour signé le certificat de R3. On a donc bien une Chain of trust.
Le travail du navigateur consiste à valider cette Chain of trust pour pouvoir affirmer que le certificat que lui propose piferrari.org est LE VRAI et pas un certificat pirate. Il va donc devoir:
Il faut avoir au préalable téléchargé les 3 certificats en utilisant les liens ci-dessous:
On commence par extraire la signature du certificat. Elle se trouve à la fin du certificat.
Signature Algorithm: sha256WithRSAEncryption
97:a2:c7:2c:da:0c:12:d9:94:fd:08:a7:39:a8:69:3a:4e:ee:
f5:3a:ea:aa:86:09:57:17:67:49:f9:c5:34:d7:f0:a5:3f:01:
be:b1:46:d4:6f:68:f5:6e:84:ba:c3:fb:dc:a4:73:fa:00:41:
ae:f9:70:9d:a9:35:4c:9e:fe:c0:bf:55:d4:63:d2:7e:d6:c7:
7a:4e:fc:d1:68:82:5f:e2:49:0b:b0:6e:e7:1f:58:bc:f2:68:
8e:18:b6:dd:a9:d4:80:76:d9:01:6a:f7:fa:24:d4:69:b8:a8:
26:27:87:a5:8c:c1:b6:a5:c9:5d:5b:7b:f8:8b:1b:d2:14:4b:
06:b6:62:59:23:41:3f:9d:1a:5b:69:0a:e3:48:23:1e:3c:6f:
e4:54:3c:3c:ed:e5:b9:ed:ad:de:0f:2a:96:9a:ee:d3:54:c5:
74:24:3e:b2:af:78:07:41:3a:50:7a:f9:8c:b6:bf:ea:75:77:
ec:73:9d:d5:0b:86:a2:0d:27:44:e6:66:ac:84:76:7b:81:af:
62:33:17:fb:5b:46:d7:f3:8e:87:30:57:c6:b4:7d:b1:86:4d:
09:39:93:6e:d1:4f:dd:ed:0b:ed:5c:db:1a:81:7f:1b:8b:83:
9b:2b:e7:b6:51:e1:4a:f8:92:ee:2a:4e:6d:b5:69:07:af:14:
36:7f:58:d4On pourrait procéder avec un copier / coller et remise en forme mais
il y a plus simple. On peut utiliser la fonctionnalité
asn1parse de l’utilitaire openssl.
$ openssl asn1parse -in piferrari.org.pem
...
1048:d=2 hl=2 l= 9 prim: OBJECT :sha256WithRSAEncryption
1059:d=2 hl=2 l= 0 prim: NULL
1061:d=1 hl=4 l= 257 prim: BIT STRING <-- ELLE EST ICI
$ openssl asn1parse -in piferrari.org.pem -out signature -noout -strparse 1061
$ hd signature
00000000 97 a2 c7 2c da 0c 12 d9 94 fd 08 a7 39 a8 69 3a |...,........9.i:|
00000010 4e ee f5 3a ea aa 86 09 57 17 67 49 f9 c5 34 d7 |N..:....W.gI..4.|
00000020 f0 a5 3f 01 be b1 46 d4 6f 68 f5 6e 84 ba c3 fb |..?...F.oh.n....|
00000030 dc a4 73 fa 00 41 ae f9 70 9d a9 35 4c 9e fe c0 |..s..A..p..5L...|
00000040 bf 55 d4 63 d2 7e d6 c7 7a 4e fc d1 68 82 5f e2 |.U.c.~..zN..h._.|
00000050 49 0b b0 6e e7 1f 58 bc f2 68 8e 18 b6 dd a9 d4 |I..n..X..h......|
00000060 80 76 d9 01 6a f7 fa 24 d4 69 b8 a8 26 27 87 a5 |.v..j..$.i..&'..|
00000070 8c c1 b6 a5 c9 5d 5b 7b f8 8b 1b d2 14 4b 06 b6 |.....][{.....K..|
00000080 62 59 23 41 3f 9d 1a 5b 69 0a e3 48 23 1e 3c 6f |bY#A?..[i..H#.<o|
00000090 e4 54 3c 3c ed e5 b9 ed ad de 0f 2a 96 9a ee d3 |.T<<.......*....|
000000a0 54 c5 74 24 3e b2 af 78 07 41 3a 50 7a f9 8c b6 |T.t$>..x.A:Pz...|
000000b0 bf ea 75 77 ec 73 9d d5 0b 86 a2 0d 27 44 e6 66 |..uw.s......'D.f|
000000c0 ac 84 76 7b 81 af 62 33 17 fb 5b 46 d7 f3 8e 87 |..v{..b3..[F....|
000000d0 30 57 c6 b4 7d b1 86 4d 09 39 93 6e d1 4f dd ed |0W..}..M.9.n.O..|
000000e0 0b ed 5c db 1a 81 7f 1b 8b 83 9b 2b e7 b6 51 e1 |..\........+..Q.|
000000f0 4a f8 92 ee 2a 4e 6d b5 69 07 af 14 36 7f 58 d4 |J...*Nm.i...6.X.|On voit que le contenu du fichier signature est le même
que la signature affichée dans le certificat.
La signature a été créé avec la clé publique de R3. Cette clé publique se trouve dans le certificat de R3. On peut donc extraire la clé publique et déchiffrer cette signature pour obtenir le sha256.
$ openssl x509 -in lets-encrypt-r3.pem -pubkey -noout > lets-encrypt-r3.pub.keyOn obtient un nouveau fichier qui contient la clé publique de R3. On peut maintenant déchiffrer la signature.
$ openssl pkeyutl -verifyrecover -in signature -pubin -inkey lets-encrypt-r3.pub.key -asn1parse
0:d=0 hl=2 l= 49 cons: SEQUENCE
2:d=1 hl=2 l= 13 cons: SEQUENCE
4:d=2 hl=2 l= 9 prim: OBJECT :sha256
15:d=2 hl=2 l= 0 prim: NULL
17:d=1 hl=2 l= 32 prim: OCTET STRING
0000 - e1 e4 5c 56 51 f5 84 68-47 b1 f7 d1 fb 24 e2 57 ..\VQ..hG....$.W
0010 - 62 97 4d 01 89 94 85 de-69 0d 6c 50 9e 7d 75 39 b.M.....i.lP.}u9On connait maintenant le sha256 qui a été utilisé pour créer la signature. On peut donc comparer ce sha256 avec celui que l’on a créé à partir du certificat de piferrari.org. Il nous faut donc extraire la partie n°4 du certificat de piferrari.org et en faire un sha256.
Pourquoi la partie 4 du certificat ? Parce que c’est le champ
tbsCertificate qui contient les informations qui ont été
signées par R3. C’est
donc ce champ qui a été hashé pour créer la signature.
TBSCertificate ::= SEQUENCE {
version [0] EXPLICIT Version DEFAULT v1,
serialNumber CertificateSerialNumber,
signature AlgorithmIdentifier,
issuer Name,
validity Validity,
subject Name,
subjectPublicKeyInfo SubjectPublicKeyInfo,
issuerUniqueID [1] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
subjectUniqueID [2] IMPLICIT UniqueIdentifier OPTIONAL,
-- If present, version MUST be v2 or v3
extensions [3] EXPLICIT Extensions OPTIONAL
-- If present, version MUST be v3
}Cette séquence se trouve en partie 4 du certificat.
$ openssl asn1parse -in piferrari.org.pem
0:d=0 hl=4 l=1318 cons: SEQUENCE
4:d=1 hl=4 l=1038 cons: SEQUENCE <- ICI ICI ICIMaintenant que nous avons le sha256 créer par R3 et que nous connaissons ce que R3 a utilisé pour le créer, nous pouvons faire le même travail que R3 c’est-à-dire, créer notre propre sha256. Si les deux sont identique nous pourrons affirmer que le certificat proposé par piferrari.org et rigoureusement identique à celui que R3 à certifié.
Selon la rfc5280,
le sha256 est le résultat du hashage du champ
tbsCertificate du certificat et ce champ correspond à
l’entrée numéro 4.
On commence par extraire la partie n°4 du certificat de piferrari.org que l’on place dans le
fichier tbsCertificate
$ openssl asn1parse -in piferrari.org.pem -out tbsCertificate -noout -strparse 4Et on en crée un sha256
$ openssl sha256 -c tbsCertificate
SHA256(tbsCertificate)= e1:e4:5c:56:51:f5:84:68:47:b1:f7:d1:fb:24:e2:57:62:97:4d:01:89:94:85:de:69:0d:6c:50:9e:7d:75:39On peut maintenant affirmer que le certificat est authentique car les deux sha256 sont identiques.
0000 - e1 e4 5c 56 51 f5 84 68-47 b1 f7 d1 fb 24 e2 57 ..\VQ..hG....$.W
0010 - 62 97 4d 01 89 94 85 de-69 0d 6c 50 9e 7d 75 39 b.M.....i.lP.}u9SHA256(la_partie_4)= e1:e4:5c:56:51:f5:84:68:47:b1:f7:d1:fb:24:e2:57:62:97:4d:01:89:94:85:de:69:0d:6c:50:9e:7d:75:39Non! On a affaire à une Chain of trust ce qui impose que l’on doit valider TOUTE la chaîne. En effet, imaginons que R3 se soit fait pirater? Et bien on aura fait toute notre validation avec une clé publique piratée. On doit donc faire le même travail pour le certificat de R3 en utilisant ISRG Root X1 et valider que R3 soit bien le certificat validé par ISRG Root X1.
La cryptographie à courbe elliptique (ECC) représente une avancée significative par rapport à la cryptographie RSA traditionnelle.
L’ECC est basé sur la structure algébrique de courbes elliptiques sur des corps finis, contrairement au RSA qui repose sur la factorisation de grands nombres premiers.
Taille des clés réduite : L’ECC offre une sécurité équivalente à RSA avec des clés beaucoup plus courtes.
| Sécurité RSA (bits) | Sécurité ECC (bits) |
|---|---|
| 2048 | 224 |
| 3072 | 256 |
| 7680 | 384 |
Performances améliorées : Les clés plus courtes permettent des calculs plus rapides et une utilisation moindre des ressources, particulièrement bénéfique pour les appareils à capacité limitée.
Sécurité renforcée : Pour une taille de clé donnée, l’ECC offre une puissance cryptographique supérieure à RSA.
RSA : ECC (ECDHE) :
Client Serveur Client Serveur
| | | |
| Génère | | Génère |
| clé symé- | |paire ECDH |
| trique | | éphémère |
| | | | | |
| v | | v |
| Chiffre | | Calcule |
| avec clé | | secret |
| publique | | partagé |
| | | | | |
| v | | v |
| Envoie | | Envoie |
| --------> | | --------> |
| | | |
| | Déchiffre | | Calcule
| | avec clé | | secret
| | privée | | partagéRSA
Le client génère une clé symétrique aléatoire, la chiffre avec la clé publique RSA du serveur, et l’envoie. Seul le serveur peut la déchiffrer avec sa clé privée RSA.
ECC (ECDHE)
Le client et le serveur génèrent chacun une paire de clés ECDH (Elliptic Curve Diffie-Hellman) éphémères (ECDHE). Ils calculent ensuite un secret partagé à partir de leur propre clé privée et la clé publique de l’autre partie. Ce secret partagé est utilisé pour chiffrer les données.
Cette approche, où les deux parties génèrent de nouvelles paires de clés ECDH pour chaque session assure la propriété de confidentialité persistante (Perfect Forward Secrecy ou PFS).
Le principe fondamentale de PFS est que la compromission d’une clé privée ne doit pas compromettre la confidentialité des sessions passées. Le PFS génère des clés de session uniques et temporaires pour chaque interaction entre un client et un serveur. Ces clés sont indépendantes de la clé privée à long terme du serveur.
La donnée est vraiment simple. Crackez ces hash MD5:
| Hash | Password |
|---|---|
5f4dcc3b5aa765d61d8327deb882cf99 |
|
823da4223e46ec671a10ea13d7823534 |
|
d796b1242dc89cedffe596d14517f2ac |
|
c62d929e7b7e7b6165923a5dfc60cb56 |
Le fichier est ici et la clé est
0x8b.
Vous recevez un message ce message:
Voici votre note pour le cours de cryptographie: 6 🎉
P. FerrariAvec cette signature:
MIGIAkIBGdim0gjfyT3XZtgg327NHtKQFfbbFwTkARzbL8BTWdycUD1C4lhRxQpUwcbb1IAKMtHy
rc0ILT7blTK/6i8SpYECQgFp1Q/Jkf0Y9l4lg544J/Uw0QIaNJ5qbjo3zIxfrT9JFP5E4n8RzJkL
4oO5XyFdAr8hEUvFbyhB5U2B1rxN+x0kfQ==Vous aimeriez être sûr que c’est un message authentique. Vous savez que P. Ferrari possède une clé privée et une clé publique. Vous avez également sa clé publique. Vous pouvez donc vérifier que le message a bien été signé par P. Ferrari.
La clé publique de P. Ferrari est ici.
Étape réalisée pour la signature:
digest.sha256digest.sha256 avec la clé privée de P.
Ferrarisignature$ openssl dgst -sha256 -binary message.txt > digest.sha256
$ openssl pkeyutl -sign -inkey ec-privatekey.pem -out signature -rawin -in digest.sha256Votre travail, validez que le message est bien signé par P. Ferrari.
openssl
et pas en base64
$ openssl pkeyutl -verify -pubin -inkey ec-pubkey.pem -rawin -in digest.sha256 -sigfile signature
Signature Verified SuccessfullyOn vous demande de valider manuellement le certificat du site de l’école.
$ openssl s_client -connect cpne-t.rpn.ch:443
$ openssl asn1parse -in cpne-ti.pem
$ openssl asn1parse -in cpne-ti.pem -out signature -noout -strparse 1312
$ openssl x509 -in SectigoRSADomainValidationSecureServerCA.crt -pubkey -noout > sectigo.pub.key
$ openssl rsautl -verify -in signature -inkey sectigo.pub.key -pubin -asn1parse
The command rsautl was deprecated in version 3.0. Use 'pkeyutl' instead.
0:d=0 hl=2 l= 49 cons: SEQUENCE
2:d=1 hl=2 l= 13 cons: SEQUENCE
4:d=2 hl=2 l= 9 prim: OBJECT :sha256
15:d=2 hl=2 l= 0 prim: NULL
17:d=1 hl=2 l= 32 prim: OCTET STRING
0000 - 85 62 6e 33 17 da 52 8d-54 63 fd 81 40 98 9d c8 .bn3..R.Tc..@...
0010 - 73 ef 0f d2 e0 7d 43 be-09 e8 a2 4a 5f a8 47 a2 s....}C....J_.G.Selon la rfc5280,
le sha256 est le résultat du hashage du champ
tbsCertificate du certificat et se champ correspond à
l’entrée numéro 4. On peut donc le vérifier. ATTENTION,
quand on dit champ numéro 4 on parle de la partie 4 du
certificat complet et pas du champ numéro 4 ci-dessus.
$ openssl asn1parse -in cpne-ti.pem
0:d=0 hl=4 l=1569 cons: SEQUENCE
4:d=1 hl=4 l=1289 cons: SEQUENCE
...
$ openssl asn1parse -in cpne-ti.pem -out tbsCertificate -noout -strparse 4
$ openssl dgst -sha256 tbsCertificate
SHA2-256(tbsCertificate)= 85626e3317da528d5463fd8140989dc873ef0fd2e07d43be09e8a24a5fa847a2On vous demande de sécuriser la connexion à un serveur web. Le travail se fera sur un serveur web Apache2.
Étape 1
Vous recevez un fichier dump réseau réalisé par une personne malveillante à l’aide d’un sniffer tel que Wireshark. On y trouve une connexion HTTP entre un client et un serveur web. Vous devez analyser le dump et trouver le mot de passe utilisé par le client pour se connecter au serveur web et ainsi prouver qu’une connexion HTTP n’est pas sécurisée.
Étape 2
Dans une machine Linux, par exemple un conteneur incus, vous
devez installer et configurer un serveur web Apache2. Le serveur web
contiendra un hôte virtuel qui servira le contenu du répertoire
/var/apw. Ce répertoire contiendra un fichier
index.html qui affichera le message
Bienvenue sur le serveur chiffré APW. Le serveur web sera
accessible uniquement en local grâce aux adresses
https://apw.local ou
https://www.apw.local.
Le fichier de configuration de l’hôte virtuel se trouvera dans
/etc/apache2/sites-available/apw.local.conf.
<VirtualHost *:443>
ServerName apw.local
ServerAlias *.apw.local
DocumentRoot /var/apw
ErrorLog ${APACHE_LOG_DIR}/apw.error.log
CustomLog ${APACHE_LOG_DIR}/apw.access.log combined
SSLEngine on
SSLCertificateFile /etc/apache2/tls/apw.crt
SSLCertificateKeyFile /etc/apache2/tls/apw.key
SSLProtocol all -TLSv1.1 -TLSv1 -SSLv2 -SSLv3
SSLCipherSuite EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:ECDHE-RSA-AES128-SHA:DHE-RSA-AES128-GCM-SHA256:AES256+EDH:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA256:ECDHE-RSA-AES256-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES256-GCM-SHA384:AES128-GCM-SHA256:AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA:DES-CBC3-SHA:HIGH:!aNULL:!eNULL:!EXPORT:!DES:!MD5:!PSK:!RC4
<Directory "/var/apw">
Require all granted
</Directory>
</VirtualHost>SSLCipherSuite qui
contient des valeurs que vous ne connaissez pas 😕. Pour réalisez
correctement cette configuration (qui n’est sûrement plus actuelle) vous
pouvez vous aiser de
moz://a
SSL Configuration Generator
Le certificat auto-signé se trouvera dans
/etc/apache2/tls/apw.crt et la clé privée dans
/etc/apache2/tls/apw.key.
Pour générez le certificat et la clé privée, vous pouvez utiliser la commande suivante:
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout apw.key -out apw.crt
Generating a 2048 bit RSA private key
............................................................................+++
..........+++
writing new private key to 'apw.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:CH
State or Province Name (full name) [Some-State]:Neuchatel
Locality Name (eg, city) []:Neuchatel
Organization Name (eg, company) [Internet Widgits Pty Ltd]:apw
Organizational Unit Name (eg, section) []:techniciens
Common Name (e.g. server FQDN or YOUR name) []:www.apw.local
Email Address []:techniciens@apw.localÉtape 3
Il reste à tester que la connexion est bien chiffrée. Pour cela, vous
devez utiliser un navigateur web et vous connecter à l’adresse
https://apw.local. Vous devez valider que le certificat est
bien celui que vous avez créé et que la connexion est bien chiffrée.
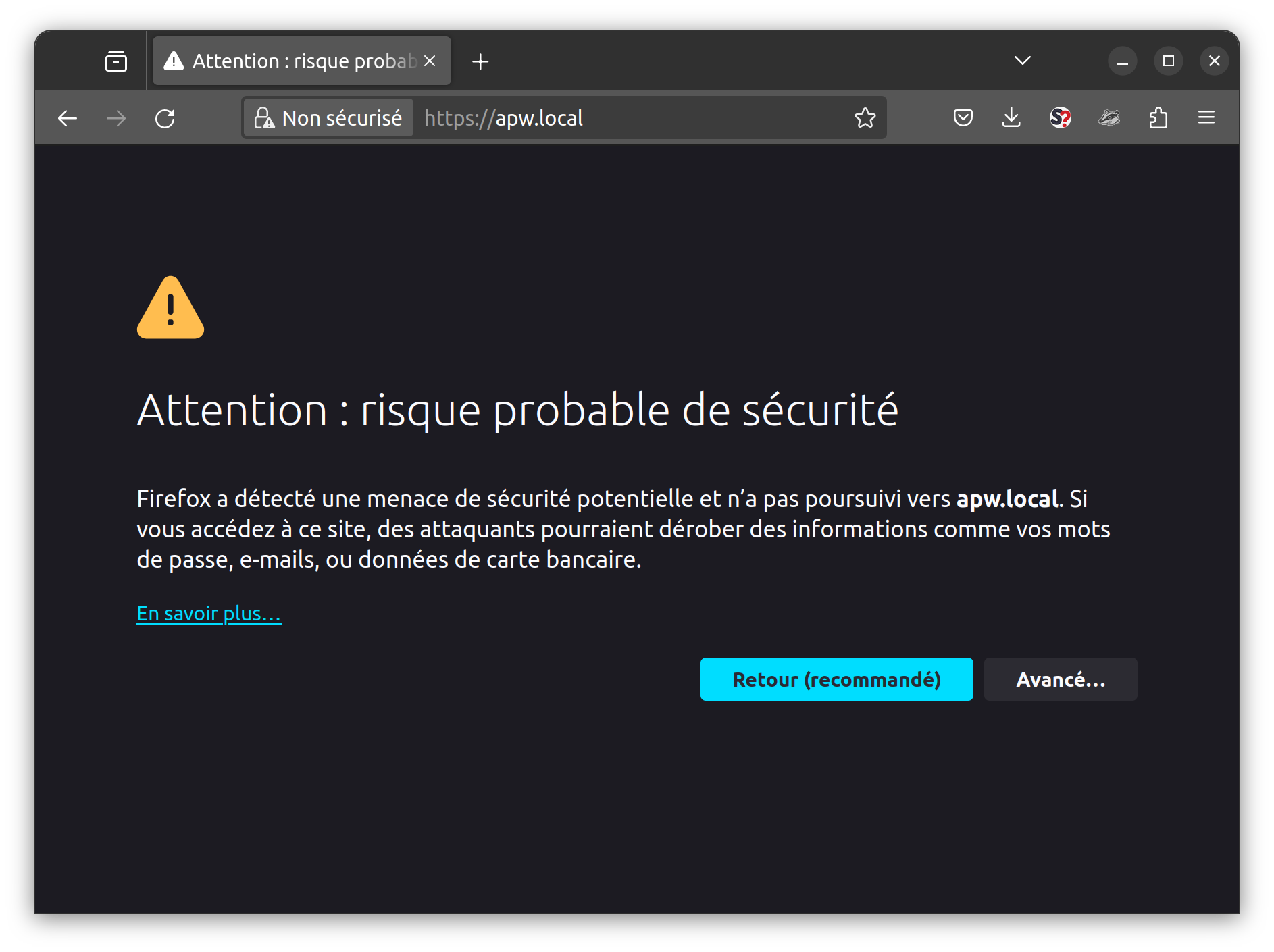
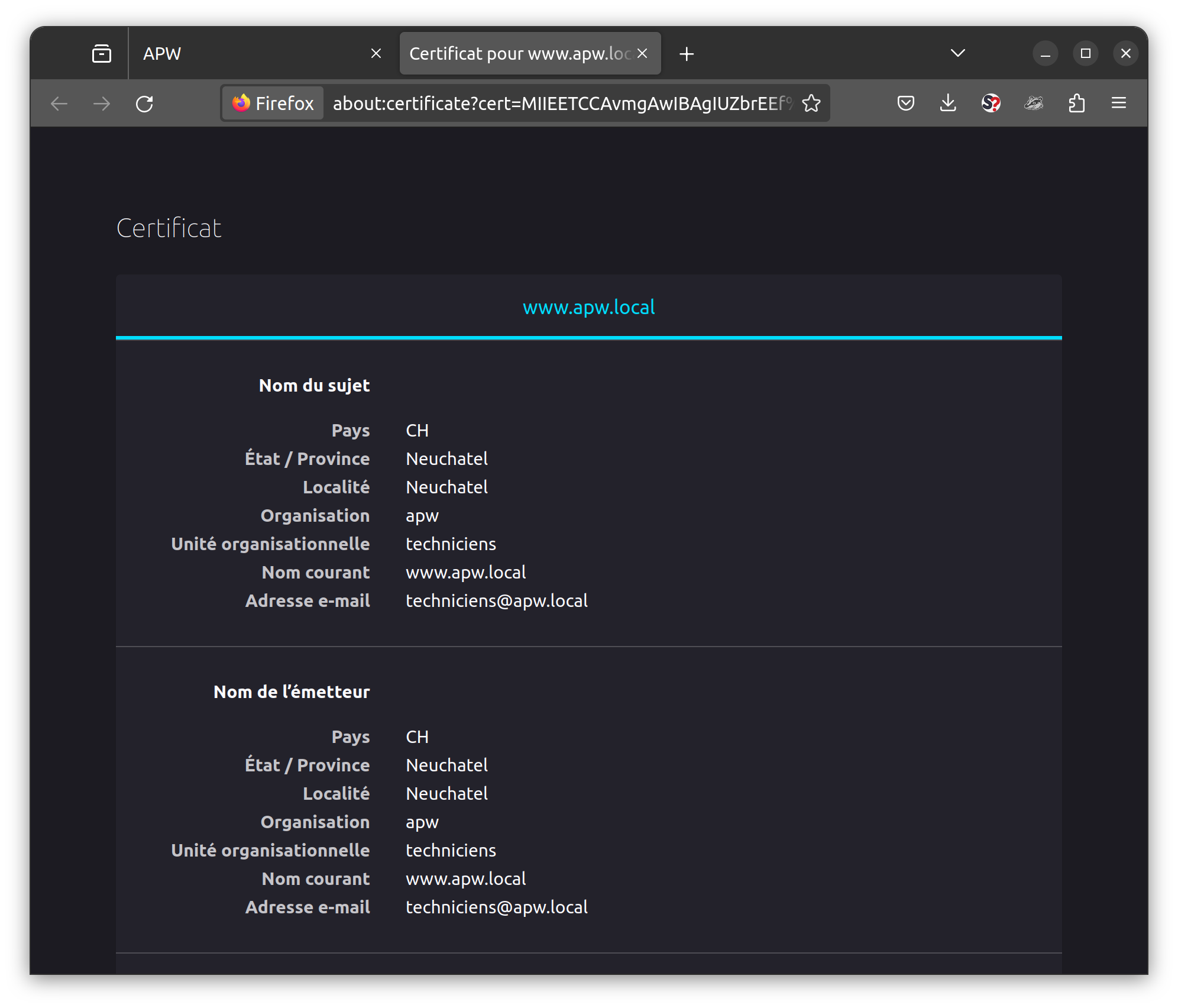
Qu’est-ce que c’est que ça encore? 🤔
Imaginez les requêtes permettant de gérer une voiture sur un site web des années 2000. Elles pourraient ressembler à ça:
Etc.
Les valeurs de retour de ces requêtes sont souvent des pages
HTML complètes ou des messages tel que Car added,
success, La voiture a été ajoutée avec l'id 3,
erreur de création avec un lien pour retourner sur la page
d’accueil.
On se rend compte que:
GET ou
parfois une requête POST mais c’est plus compliquéadd_car.php, update_car.php,
delete_car.phpla voiture a été ajoutée avec l'id 3
force le programmeur à faire du scraping pour récupérer l’id de
la voiture et à relancer une requête pour obtenir les informations de la
voiture.C’est un peu le bazar non? 😕
En sachant que HTTP/1.1 was first published as RFC 2068 in January 1997 et que HTTP:
GET, POST,
PUT, PATCH, DELETE pour définir
l’action200 OK,
201 Created, 204 No Content,
400 Bad Request, 404 Not Found,
500 Internal Server Error pour définir le résultat de
l’actionLocationRewrite
pour modifier les urls tel que
https://www.example.com/add_car.php?brand=Renault&model=Clio&year=2023
pourrait devenir
https://www.example.com/cars/renault/clio/2023On peut se dire que l’on peut faire mieux et qu’il n’est nul besoin de réinventer la roue. C’est là qu’intervient REST.
Que dit Wikipedia à ce sujet?
REST (representational state transfer) est un style d’architecture logicielle définissant un ensemble de contraintes à utiliser pour créer des services web. Les services web…

💬 Il faut rendre à César ce qui est à César et REST à … à qui?
💬 Quelles sont les principales propriétés et contraintes à respecter pour être RESTful?
💬 Quelles sont les 4 méthodes HTTP utilisées par REST?
💬 Quel est le lien entre les méthodes CRUD et les méthodes HTTP?
💬 Il faut préférer nouns à verbs. Ca veut dire quoi?
get provient de la
méthode HTTP

Tout programme se doit d’avoir ses tests unitaires. C’est par les tests unitaires que l’on peut s’assurer de la qualité du code. Pour créer des tests unitaires sur une API REST, on peut utiliser Postman. Non seulement cet outil nous permet de comprendre comment fonctionne les requêtes HTTP sur l’API mais il nous permet également de lancer et préparer des tests unitaires.
Tout en regardant la vidéo ci-dessous, je vous propose de réaliser les tests unitaires sur l’API REST Simple Book API en même temps qu’il les explique.
DELETE y.c.
Ci-dessous, vous pouvez trouver un exemple, pas complet, de tests unitaires pour l’API REST Simple Book API.
mockapi.io permet de créer des API REST en deux coups de cuillère à pot.
On vous demande de créez une API REST qui permet de gérer des
familles. Chaque famille doit avoir un id, une
date de création, un nom et un
uniqid. Vous pouvez utiliser la création automatisée de
valeurs pour tous les champs.
Example
[
{
"createdAt": "2023-06-04T22:10:43.047Z",
"name": "My Family",
"uniq": "12bb34dd56ff",
"id": "1"
},
{
"createdAt": "2022-10-26T09:21:43.047Z",
"name": "Other Family",
"uniq": "690b451bdb5e",
"id": "2"
},
{
"createdAt": "2023-09-07T13:50:33.634Z",
"name": "Unknown Family",
"uniq": "0dc2763787bc",
"id": "3"
}Dans Postman, créez une
collection de requêtes pour l’API famille ainsi qu’un jeu
de test unitaire. Les requêtes doivent correspondre aux méthodes HTTP
GET, POST, PUT et
DELETE. On aimerait donc pouvoir lister toutes les
familles, lister une famille, créer une famille, modifier une famille et
supprimer une famille (CRUD).
Vous pouvez également ajouter des tests pour chaque requête. Par exemple,
Toute la partie test se trouve dans l’unité 2 de la vidéo.
Un remplacant de postman qui prend de l’empleur se nomme Bruno. Il a l’énorme avantage de stocker tout le travail localement, d’être opensource et de possèder une version gratuite.
Bruno utilise la librairie Chai pour les tests unitaires.
L’objectif de cette partie est de présenter, au travers la création d’une application simple, les différents documents créés lors de l’analyse du projets.
Ces documents seront utilisés lors des discussion avec le client pour faciliter la compréhension du fonctionnement de l’application.
Besoin de l’utilisateur
L’utilisateur est définit par un identifiant unique, un nom et une date de naissance.
Ces esquisses permettent d’avoir rapidement une idée de l’interface utilisateur. Elles permettent également de valider avec le client que l’on a bien compris ses besoins.
Ces esquisses ne sont là que pour valider le concept de fonctionnement de l’application.
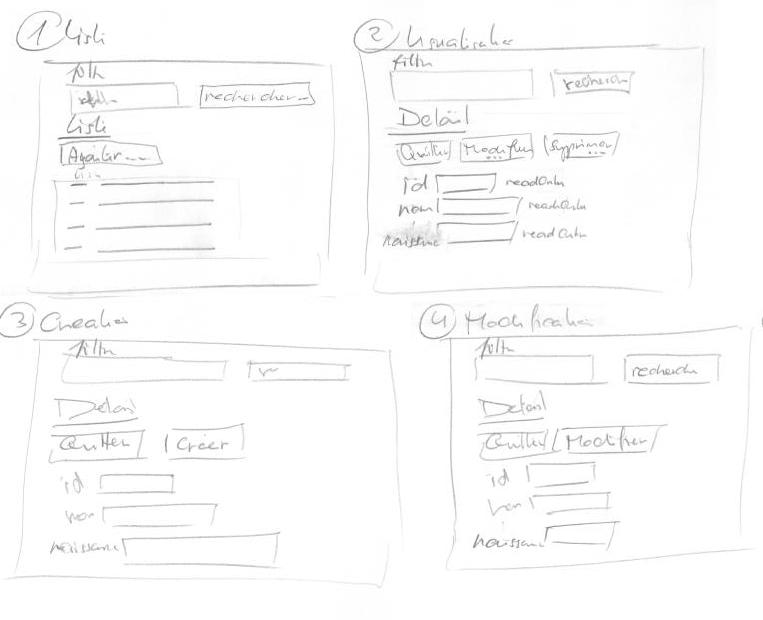
Il va permettre d’avoir une idée plus précise de comment l’utilisateur atteindra les différentes fonctionnalités de l’application. Il permettra également au développeur de savoir comment il devra organiser son code.
Cet écran permet de définir l’agencement des différents éléments de l’interface utilisateur. Il permet également de définir les différents éléments qui seront présents sur l’interface utilisateur. C’est par exemple à ce moment que l’on va définir les différents boutons, les différents champs de saisie, etc.
Et tout à coup se rendre compte que le bouton administration suppose que l’on puisse se connecter à l’application, que l’on ait un compte administrateur et que l’on aura toute une partie administration à développer à laquelle on n’avait pas pensé.
On pourra également utiliser ces écrans pour discuter plus précisément de l’interface utilisateur avec le client mais il faut bien faire comprendre au client que ce n’est pas le design final de l’application. C’est juste le principe de fonctionnement de l’application.

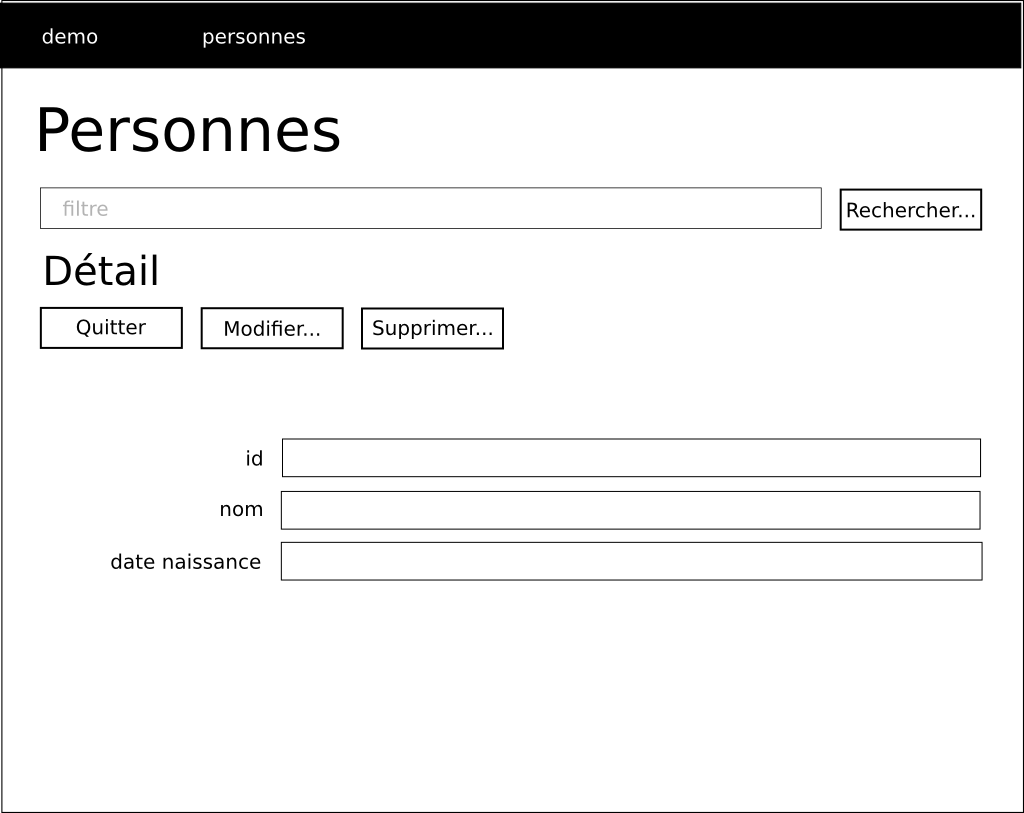
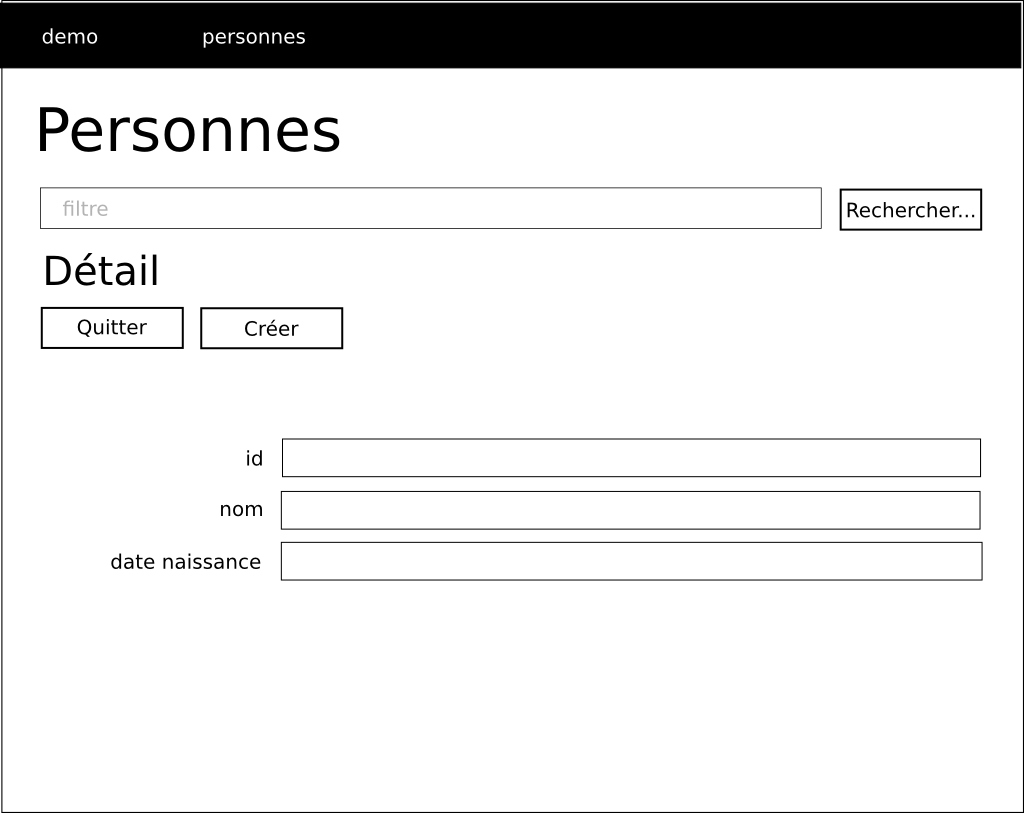
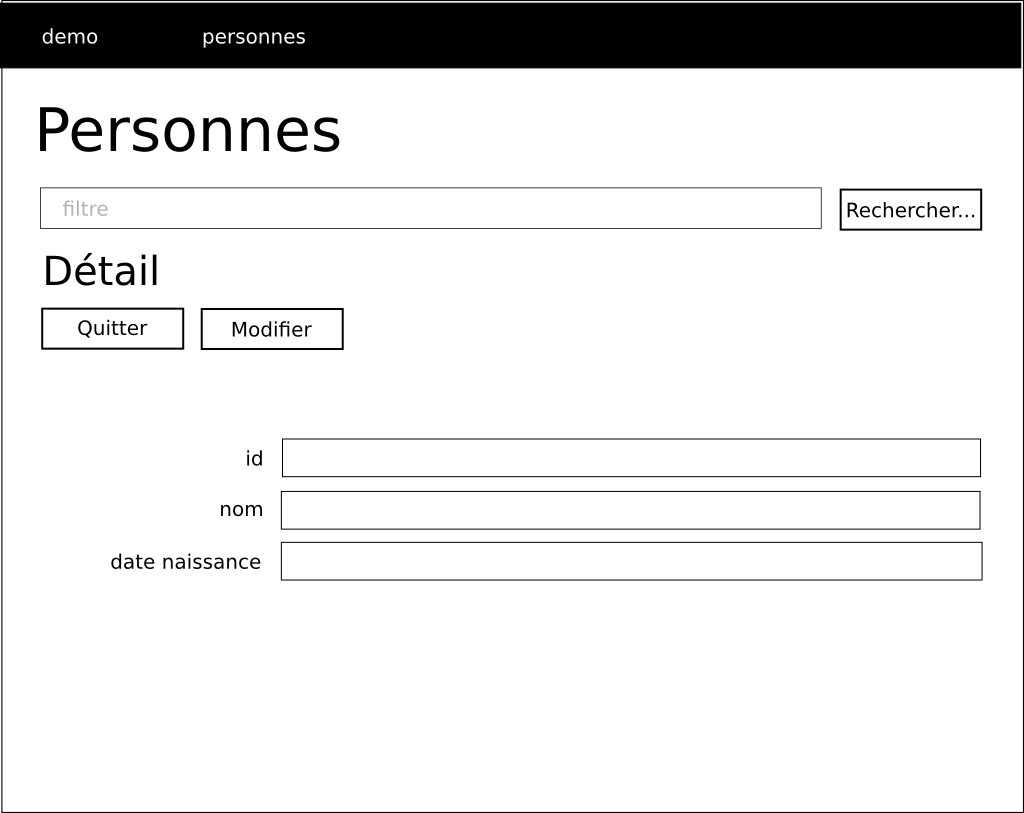
On complète l’analyse avec un liste d’url qui permettra de définir les différentes routes de l’application. Garder à l’esprit qu’une url ne doit pas changer. En effet, si on référence une url dans un document ou dans un moteur de recherche, il faut que cette url soit toujours valide. Si on change l’url, il faut également changer le document qui référence cette url et le moteur de recherche risque de fournir un lien qui n’aboutira pas.
| Méthode HTTP | URL | Description |
|---|---|---|
| GET | / | Page d’accueil |
| GET | /personnes | Liste des personnes |
| GET | /personnes/:personneId | Détail d’une personne |
| POST | /personnes | Création d’une personne |
| PUT | /personnes/:personneId | Modification d’une personne |
| DELETE | /personnes/:personneId | Suppression d’une personne |
| PATCH | /personnes/:personneId | Modification partielle d’une personne |
| GET | /filter | Filtre des personnes (recherche) |
C’est ici que les chemins peuvent prendre une direction différente en fonction de l’objectif de l’application.
Application à usage interne
Dans le cas d’une application à usage interne ou une application dont seuls quelques personnes avisées seront les utilisateurs, on peut s’arrêter là pour le graphisme et faire une application fonctionnelle.
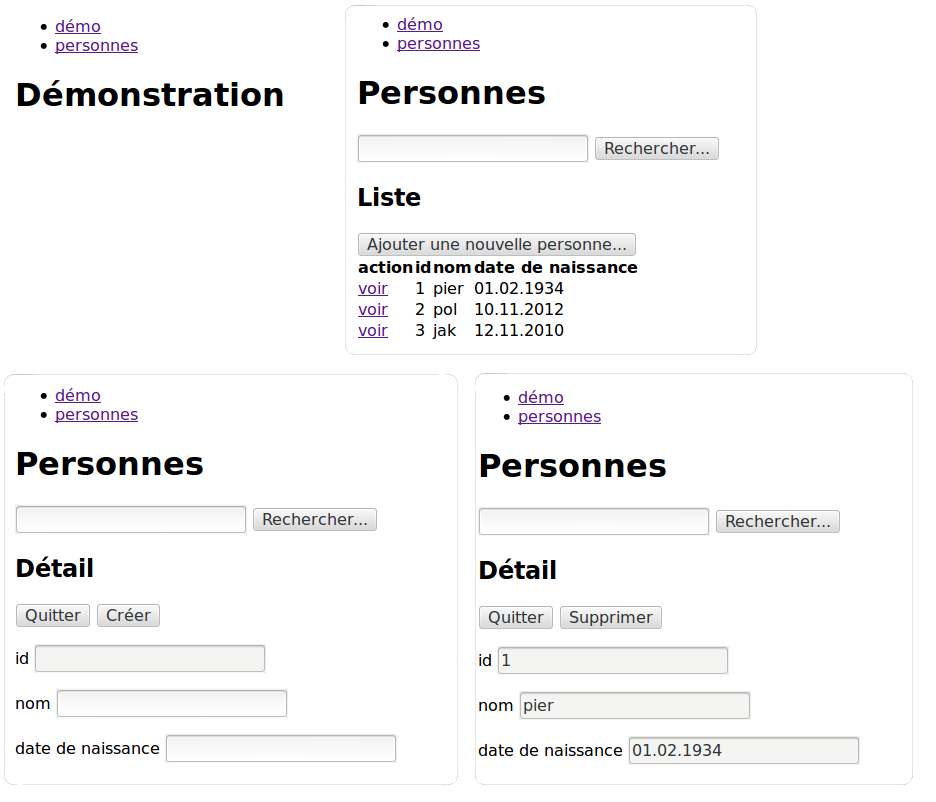
On peut également mettre un peu de design pour rendre l’application plus agréable à utiliser sans pour autant faire appel à un designer. Par exemple, à l’aide de Bootstrap, on peut faire quelque chose de très sympa.
Application pour un client
Dans le cas où l’application sera utilisée par des clients, il faut aller plus loin dans le graphisme. Pour cela, il faut faire appel à un designer qui va créer une charte graphique et un design pour l’application. Pour bien comprendre le travail du designer, vous pouvez imaginer qu’il travail dans Photoshop et qu’il crée des images jpg ou png. Il ne réalise pas de CSS ou de HTML. C’est le travail du développeur.
Dans le cas où le travail d’un designer serait trop cher, on peut également acheter des kit graphiques sur internet. Il ne seront pas spécifiquement adaptés à l’application, aux sensibilités du client ou à la charte graphique de l’entreprise mais ils permettront d’avoir un design uniformisé et qui plaira au client puisque le choix se fera avec lui.

Le responsive design est une technique de conception de sites web qui permet, grâce à des techniques de CSS, de créer des sites dont le rendu s’adapte à la taille de l’écran de l’utilisateur. Cela permet d’avoir un site qui s’affiche correctement sur un smartphone, une tablette ou un ordinateur.
On peut facilement voir l’évolution du web en utilisant la machine à remonter dans le temps.
En 2003
En 2010
float: left,
clear: left, position: relative des div vide
<div class="fix"></div> avec des class
clear: bothLe CSS évolue, l’HTML et le Javascript aussi. Chacun commence à réelement remplir son rôle.
Il y a longtemps, dans une galaxie lointaine… les sites web étaient construit à l’aide de code HTML 4.1 et de CSS 2.1. Les sites étaient donc statiques et ne s’adaptaient pas à la taille de l’écran. Pour palier à ce problème, on a commencé à utiliser des techniques de mise en page comme les tableaux ou les frames pour créer des sites qui s’adaptaient à la taille de l’écran.
Aux début de la conception web …
Pour apprendre les bases de la mise en forme moderne d’un site web, je vous propose de suivre les cours présentés sous forme de jeux suivants:
Lorsque vous devez réaliser un site web simple, vous pouvez utiliser les techniques mises en pratique dans les jeux ci-dessus. Cependant, lorsque vous devez réaliser un site web plus complexe, il est préférable d’utiliser un framework CSS. Il en existe plusieurs, comme par exemple Bulma, mais le plus connu est Bootstrap.
Un des reproches que l’on peut faire à Bootstrap est qu’il est trop utilisé et que l’on reconnait facilement un site réalisé avec Bootstrap. C’est vrai mais il existe des thèmes pour Bootstrap qui permettent de personnaliser le design de l’application. Vous pouvez par exemple utiliser Bootswatch qui propose des thèmes gratuits pour Bootstrap.
Si vous devez développer un petit site qui ne justifie pas l’emploi d’un framework CSS, vous devrez commencer par faire un reset des propriétés css. En effet, les navigateurs web ont des propriétés css par défaut qui peuvent varier d’un navigateur à l’autre même si ce comportement tend à disparaître.

Il est donc préférable de réinitialiser toutes les propriétés pour avoir un comportement identique sur tous les navigateurs.
Chaque année le site StackOverflow réalise un sondage auprès de ses utilisateurs. Les résultats sont disponibles ici. On y trouve énormément d’informations sur les développeurs et les technologies utilisées. Ce qui nous intéresse pour cet exercice, c’est la partie Most popular technologies et plus précisément encode, les langages de programmation les plus utilisés.
On vous demande d’extraire les informations ci-dessous sur les langages de programmation les plus utilisés. L’idée est de pouvoir utiliser ces données pour les afficher sur un site web.
[
{
"language":"JavaScript",
"percent":"63.61"
},
{
"language":"HTML/CSS",
"percent":"52.96999999999999"
},
{
"language":"Python",
"percent":"49.28"
},
{
"language":"SQL",
"percent":"48.66"
},
{
"language":"TypeScript",
"percent":"38.87"
},
{
"language":"Bash/Shell (all shells)",
"percent":"32.37"
},
{
"language":"Java",
"percent":"30.55"
},
{
"language":"C#",
"percent":"27.62"
},
{
"language":"C++",
"percent":"22.42"
},
{
"language":"C",
"percent":"19.34"
},
{
"language":"PHP",
"percent":"18.58"
},
{
"language":"PowerShell",
"percent":"13.59"
},
{
"language":"Go",
"percent":"13.239999999999998"
},
{
"language":"Rust",
"percent":"13.05"
},
{
"language":"Kotlin",
"percent":"9.06"
},
{
"language":"Ruby",
"percent":"6.23"
},
{
"language":"Lua",
"percent":"6.09"
},
{
"language":"Dart",
"percent":"6.02"
},
{
"language":"Assembly",
"percent":"5.43"
},
{
"language":"Swift",
"percent":"4.65"
},
{
"language":"R",
"percent":"4.2299999999999995"
},
{
"language":"Visual Basic (.Net)",
"percent":"4.07"
},
{
"language":"MATLAB",
"percent":"3.81"
},
{
"language":"VBA",
"percent":"3.55"
},
{
"language":"Groovy",
"percent":"3.4000000000000004"
},
{
"language":"Delphi",
"percent":"3.2300000000000004"
},
{
"language":"Scala",
"percent":"2.77"
},
{
"language":"Perl",
"percent":"2.46"
},
{
"language":"Elixir",
"percent":"2.32"
},
{
"language":"Objective-C",
"percent":"2.31"
},
{
"language":"Haskell",
"percent":"2.09"
},
{
"language":"GDScript",
"percent":"1.71"
},
{
"language":"Lisp",
"percent":"1.53"
},
{
"language":"Solidity",
"percent":"1.3299999999999998"
},
{
"language":"Clojure",
"percent":"1.26"
},
{
"language":"Julia",
"percent":"1.15"
},
{
"language":"Erlang",
"percent":"0.9900000000000001"
},
{
"language":"F#",
"percent":"0.97"
},
{
"language":"Fortran",
"percent":"0.95"
},
{
"language":"Prolog",
"percent":"0.89"
},
{
"language":"Zig",
"percent":"0.83"
},
{
"language":"Ada",
"percent":"0.77"
},
{
"language":"OCaml",
"percent":"0.7000000000000001"
},
{
"language":"Apex",
"percent":"0.66"
},
{
"language":"Cobol",
"percent":"0.66"
},
{
"language":"SAS",
"percent":"0.49"
},
{
"language":"Crystal",
"percent":"0.44"
},
{
"language":"Nim",
"percent":"0.38"
},
{
"language":"APL",
"percent":"0.26"
},
{
"language":"Flow",
"percent":"0.24"
},
{
"language":"Raku",
"percent":"0.18"
}
]Une fois en possession de ces données, vous devez créer une page web qui affiche ces données sous forme de graphique. Tout le graphique sera fait en pur CSS et il sera responsive.
Exemple
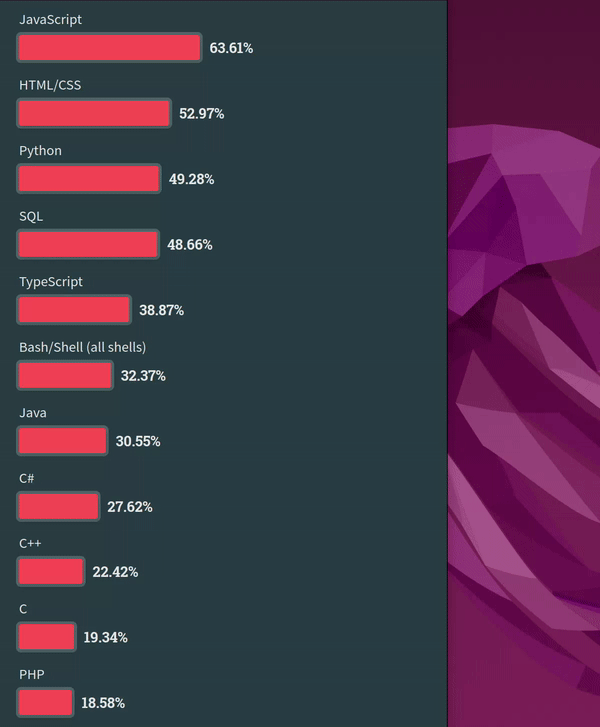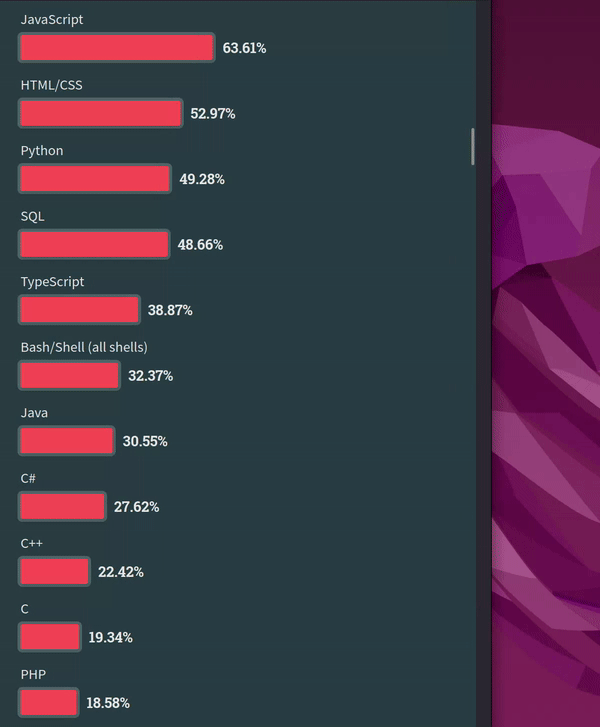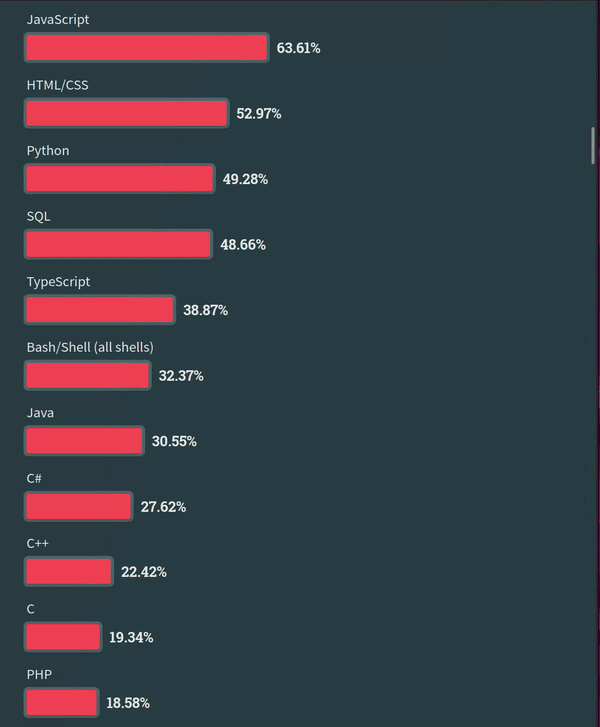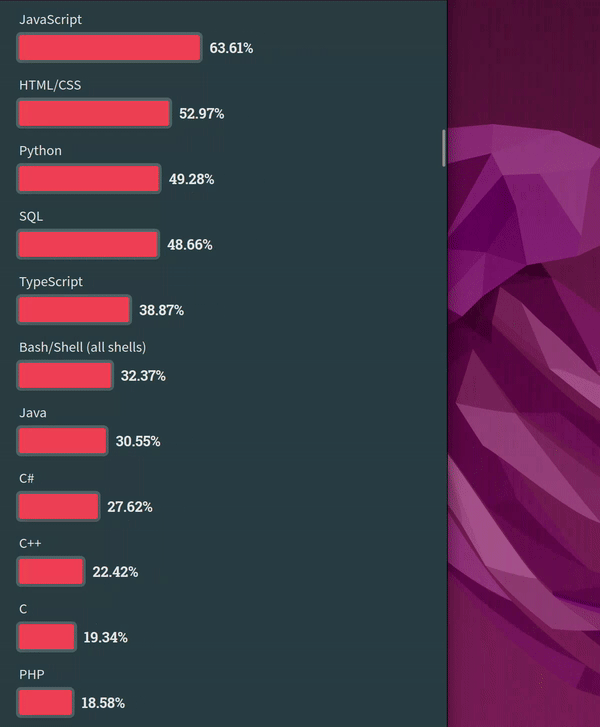
$ echo "[$(curl -s https://survey.stackoverflow.co/2023 | awk '/<figure id="most-popular-technologies-language"/,/<\/figure>/' | xmllint - --html --nowarning --xpath '//table/tr/td[@class="label lh-sm"]/text() | //table/tr/td[@class="bar"]/@data-percentage' 2>/dev/null | tr -d '"' | sed 's/data-percentage\=/:/g' | tr '\n' ';' | sed 's/; :/=/g' | sed 's/;/\n/g' | sed 's/\(.*\)=\(.*\)/{"language":"\1","percent":"\2"},/g')" | tr -d '\n' | sed 's/.$/]/'
[{"language":"JavaScript","percent":"63.61"},{"language":"HTML/CSS","percent":"52.96999999999999"}, ... ]Météosuisse fournit indirectement les données métérologiques sous forme de flux JSON. D’un autre côté, l’application météosuisse permet de visualiser ces données dans leur application (la partie rouge).
On vous demande de créer une page web qui affiche les données météo de la ville de votre choix avec la même mise en forme que l’application météosuisse.
Votre code se présentera sous la forme d’un widget que l’on pourra intégrer dans un site web.
Avant d’entrer dans le vif du sujet Javascript, on va
faire un rappel sur le DOM.
Le Document Object Model (DOM) est une interface de programmation normalisée par le W3C, qui permet à des scripts d’examiner et de modifier le contenu du navigateur web. Par le DOM, la composition d’un document HTML ou XML est représentée sous forme d’un jeu d’objets – lesquels peuvent représenter une fenêtre, une phrase ou un style, par exemple – reliés selon une structure en arbre. À l’aide du DOM, un script peut modifier le document présent dans le navigateur en ajoutant ou en supprimant des nœuds de l’arbre.
En d’autres termes, le DOM est une représentation de la page web sous la forme d’un arbre contenant les différents éléments de la page.
Exemple: le code source suivant:
<!DOCTYPE html>
<html>
<head>
<title>My title</title>
</head>
<body>
<h1>A heading</h1>
<a href="#">Link text</a>
</body>
</html>devient le DOM suivant:

Le DOM est généré automatiquement d’après le code source par le navigateur. C’est le moteur de rendu du navigateur qui détermine comment les éléments sont imbriqués.
En cas de code HTML non valide, le navigateur fait de son mieux pour rétablir la cohérence des données.
Lorsqu’on appuie sur F12 (dans la plupart des
navigateurs), une fenêtre ressemblant à celle-ci apparait:
Bien que cela ressemble au code source, il n’en est rien! Une différence majeure existe entre le code source et le DOM.
Lorsque le navigateur reçoit la page web, il reçoit un document
figé (qu’on peut habituellement afficher avec
CTRL+U).
Ce document est analysé et interprété. On en crée le DOM qui devient dynamique: il va pouvoir être modifié!
Une démonstration rapide peut-être réalisé en faisant un clic droit sur le titre ci-dessus (Différence entre le code source et le DOM) et inspectez l’élément.
Grâce à un double-clic, modifiez le contenu de la balise
<h3> pour y écrire: “Le DOM est
modifié”. Et voilà. Vous venez de modifier le DOM. Cependant,
si vous affichez le code source (CTRL + U), vous verrez
qu’il n’a pas changé.
Il n’est pas aisé de trouver le cours Javascript
adapté à nos besoins. En effet, vous n’êtes pas vraiment débutants mais
vous n’êtes pas non-plus développeurs confirmés (en Javascript). Suivre
un cours vidéo de 4h sur les bases de Javascript ou l’on vous explique
les structures if serait très ennuyeux pour vous. À
contrario, suivre un cours avancé où on vous explique des spécificités
des grands nombres en Javascript ne vous serait pas d’une grande
utilité. Je vous propose donc un cours rapide intermédiaire sur
Javascript.
Avant de démarrer, il faut absolument connaître LA RÉFÉRENCE en Javascript: MDN. C’est la bible du développeur Javascript.
Plus généralement, le site MDN est la référence pour tout ce qui touche au développement web. On y trouve par exemple, un cours javascript complet.
Le JavaScript (JS) est un langage créé en 1996 par Brendan Eich, alors développeur chez Netscape. Il a subi d’énormes modifications au fil des années pour devenir ce qu’il est actuellement.
JavaScript ne doit pas être confondu avec Java! Le JavaScript a été créé comme complément au langage Java car il permet de réaliser les opérations que Java ne sait pas faire: des modifications de page web côté client.
Confondre Java et Javascript, c’est comme confondre un chat et un château.

Le JS est un langage de programmation procédural interprété et faiblement typé, permettant la modification d’un DOM.
Explication des termes ci-dessus:
| Terme | Description | Autre exemple | Antonyme |
|---|---|---|---|
| langage de programmation | langage informatique permettant d’effectuer des opérations logiques | C♯ | langage de description (HTML) |
| procédural | effectuant des opérations séquentielles se basant sur l’utilisation de fonctions | Python | orienté objet (Java) |
| interprété | transformé en code machine au moment de l’exécution au lieu de la compilation | PHP | compilé (C♯) |
| faiblement typé | ayant des types déterminés automatiquement et non écrits dans le code | Python | fortement typé (C♯) |
La particularité du JavaScript est qu’il s’agit d’un langage
particulièrement permissif: il tentera de donner une réponse même en cas
d’erreur. Exemple: en JS, on peut effectuer une division par zéro. Le
résultat est Infinity.
Il est surtout utilisé en web côté client, comme nous allons le voir ensemble, mais on peut également l’utiliser en web côté serveur (Node.JS), en programmation d’application lourde (Electron) ou comme outil de communication entre applications (JSON).
Ouvrez les outils de développement avec F12 et
rendez-vous sur l’onglet Console. À cet endroit, vous pouvez
taper du JavaScript.
Pour chacune des opérations suivantes, tentez de prédire le résultat, puis tapez-le réellement dans la console et découvrez si vous aviez raison. Tentez de trouver une explication par vous-même pour les résultats que vous n’avez pas réussi à prédire.
| Entrée | Votre prédiction | Résultat réel (utilisez F12 / Console) |
|---|---|---|
1+1 |
||
"Hello," + " World!" |
||
"1" + "2" |
||
"a" + 'b' |
||
"Hello, " + ' World!' |
||
`J'ai 20 ans, l'an prochain j'aurai ${20 + 1} ans.` |
||
Math.sqrt(16) |
||
if (3 > 4) { "Plus grand" } else { "Plus petit" } |
||
9 + "1" |
Il existe trois manières d’ajouter du JavaScript à un projet:
Les raisons pour lesquelles les deux dernières manières de faire existent sont d’ordre historique. On a remplacé un processus de travail par quelque chose de mieux, au fil du temps. Afin de pouvoir comprendre du code ancien (le terme technique est legacy), nous allons survoler ces trois manières de faire.
Une inclusion de JavaScript n’est pas quelque chose d’affichable à
l’utilisateur, nous allons donc l’ajouter… dans le
<head> de la page HTML:
<!DOCTYPE html>
<html>
<head>
<title>Page avec JS</title>
<script src="js/un-script.js"></script>
</head>
<body></body>
</html>La balise <script> permet de lier le fichier JS au
document courant en précisant l’emplacement de celui-ci.
Ensuite, dans le fichier js/un-script.js, on peut écrire
le code suivant:
console.log("Hello, World!")Ce code va être exécuté au chargement de la page
Le code JavaScript va se lancer au moment où le script est appelé,
c’est-à-dire alors que le navigateur est en train d’analyser le
<head>. Si on a besoin de savoir à quoi ressemble le
reste du document avant de lancer le script, on peut le lancer de
manière différée avec
<script src="js/un-script.js" defer>. Dans ce cas, le
script sera lancé lorsque le DOM est entièrement prêt dans le
navigateur. On est obligé de faire ceci si on désire éditer le
DOM!
ATTENTION: ceci n’est enseigné que pour pouvoir lire du code legacy et ne doit plus être implémenté!
Du code JavaScript peut être interprété directement depuis le
fichier HTML. En plaçant une balise
<script></script> sans src, on
peut implémenter le code JS sur place.
Afin de pouvoir accéder aux éléments du DOM, il est obligatoire de
mettre ce code à la fin du document, juste avant la fermeture
de la balise </body>. Ainsi, on contrevient aux
normes de base voulant qu’on place dans le <head> les
éléments destinés au navigateur et dans le <body>
ceux destinés à l’utilisateur.
ATTENTION: ceci n’est enseigné que pour pouvoir lire du code legacy et ne doit plus être implémenté!
Il est possible d’ajouter directement du code JS dans une balise de
cette manière: <nom-de-la-balise onXXX="code JS">.
Ceci permettrait de gérer un évènement (onclick,
onmouseenter, etc.).
Bien évidemment, ceci est encore pire que de placer le code en fin de document car il lie fortement le code HTML au JS. Les technologies devraient toujours être séparées afin de permettre une réutilisation. Gérez les évènements dans un fichier JavaScript et non dans le fichier HTML!
En JavaScript, il n’existe que 4 types de variables (ou de constantes). Elles sont toutes déclarées de la même manière:
Les variables se déclarent grâce au mot-clé let, qui
signifie “soit” (comme en mathématiques: “soit une variable x ayant une
valeur de 5”) et se déclare avec ou sans affectation:
let a = 5
let bLes constantes se déclarent grâce au mot-clé const,
exactement de la même manière, si ce n’est qu’une constante doit avoir
une affectation:
const c = 10Sur Internet, on trouve encore du code legacy avec le mot-clé
var pour déclarer une variable. 💥 CECI EST À
ÉVITER À TOUT PRIX!!! 💥
Voici ce qui se passe avec var:
console.log(apres)
var apres = "déclaré après"
if (true) {
var dansIf = "déclaré dans un bloc"
}
console.log(dansIf)Le code ci-dessus affiche:
undefined
"déclaré dans un bloc"Deux problèmes sont visible:
Afin d’éviter ceci, le mot-clé var est à proscrire!
“Scalaire” est un mot qui signifie “une seule donnée”. Ainsi, tous
les types simples déjà vus dans d’autres langages sont des scalaires
(int, double, bool,
string, etc.).
En JavaScript, tous ces types sont compatibles. Ainsi, le code ci-dessous est parfaitement valide:
let age = 20
let taille = 1.75
let description = "J'ai " + age + " ans et je mesure " + taille + " m."Un tableau est un élément qui contient plusieurs variables. Les tableaux sont dynamiques (peuvent changer de taille) et peuvent contenir des données de types différents.
La syntaxe se fait grâce à des crochets et des virgules
([] et ,).
Exemples de tableaux valides:
let notes = [4.5, 3.5, 6.0, 5.0, 5.0, 5.5]
let eleves = [
"Sarah Fraichi",
"Bill Boquet",
"Anna Gramme",
"Tamara Quête",
"Gilles Eparbal",
]
let donnees = [12, "maison", false, 4.2, [5, 10, 15, 20, "beaucoup"]]Pour lire ou éditer un tableau, on peut effectuer des opérations
grâce à l’opérateur [], à push() et à
length:
let notes = [4.5, 6.0, 5.0] // [4.5, 6.0, 5.0]
notes[0] = 5.5 // [5.5, 6.0, 5.0]
notes.push(6.0) // [5.5, 6.0, 5.0, 6.0]
for (let i = 0; i < notes.length; i++) {
console.log(notes[i]) // parcours avec un for, chaque note sera affichée
}JSON signifie “JavaScript Object Notation” ou “notation pour les object JavaScript”. Un objet est un élément qui contient plusieurs données, chacune de ces données est nommée et peut être de n’importe quel type.
La syntaxe comprend des accolades ({}), des deux-points
(:) et des virgules (,).
Exemple de JSON valide:
let eleve = {
prenom: "Axel",
nom: "Erateur",
age: 17,
classe: "4IND-3TPx1",
notes: [5.5, 4.0, 6.0, 3.5, 4.0, 4.5, 5.0],
adresse: {
rue: "Rue du Chemin",
numero: 2,
localite: "Gravier-sur-Mer",
npa: 9312,
},
amis: [
{
prenom: "Alain",
nom: "Proviste",
},
{
prenom: "John",
nom: "Deuf",
},
{
prenom: "Maude",
nom: "Zarella",
},
],
}On peut remarquer des JSON à trois endroits:
eleve est de type JSONOn peut accéder en lecture/écriture à un JSON avec l’opérateur
. comme ceci:
console.log(eleve.prenom) // Affiche "Axel"
eleve.age++ // Change age à 18
eleve.adresse = {
rue: "Avenue de la Place",
numero: "3b",
localite: "Fontalmont",
npa: 9400,
} // Modifie toute l'adresse
eleve.amis.push({ prenom: "Sasha", nom: "Touille" }) // Ajoute un nouvel ami
eleve.salaire = 780 // Rajoute un attribut dans l'objet
console.log(eleve) // Affiche ce qui suit:
/*
{
prenom: "Axel",
nom: "Erateur",
age: 18,
classe: "4IND-3TPx1",
notes: [5.5, 4.0, 6.0, 3.5, 4.0, 4.5, 5.0],
adresse: {
rue: "Avenue de la Place",
numero: "3b",
localite: "Fontalmont",
npa: 9400
},
amis: [
{
prenom: "Alain",
nom:"Proviste",
},
{
prenom: "John",
nom: "Deuf"
},
{
prenom: "Maude",
nom: "Zarella"
},
{
prenom: "Sasha",
nom: "Touille"
}
],
salaire: 780
}
*/En JS, on peut considérer les fonctions comme des variables. Dingue, non?
Les fonctions effectuent des opérations mais peuvent également
apparaitre dans des variables (scalaires, tableaux ou JSON) et peuvent
être appelées sans problème avec l’opérateur ().
Pour déclarer une fonction, on peut utiliser la même syntaxe qu’avec
les autres variables ou utiliser le mot-clé function.
Voici des exemples de fonctions valides:
let doubler = function (nombre) {
return nombre * 2
}
function additionner(n1, n2) {
return n1 + n2
}
console.log(doubler(10)) // Affiche 20
console.log(additionner(12, 30)) // Affiche 42Il existe également une syntaxe raccourcie sans le mot-clé
function. La syntaxe est la suivante:
(paramètres) => { code }.
Exemples avec les deux fonctions précédentes:
let doubler = (nombre) => {
return nombre * 2
}
let additionner = (n1, n2) => {
return n1 + n2
}
console.log(doubler(10)) // Affiche 20
console.log(additionner(12, 30)) // Affiche 42Subtilités:
return sont facultatifs.Exemples:
let categorieDAge = (age) => {
if (age < 18) {
return "enfant"
} else if (age < 65) {
return "adulte"
} else {
return "retraité(e)"
}
}
let nomComplet = (prenom, nom) => prenom + " " + nom
let compterAmis = (personne) => personne.amis.length
let saluer = () => {
console.log("Bonjour tout le monde!")
}
let prenomNom = nomComplet("James", "Kié") // prenomNom == 'James Kié'
let nombreAmis = compterAmis(eleve) // nombreAmis = 4
saluer() // Affiche "Bonjour tout le monde!"On peut définir une fonction dans un tableau (rare) ou dans un JSON (plus fréquent), par exemple comme ceci:
let bouton = {
texte: "Cliquez-moi!",
couleur: "vert",
action: function () {
console.log("Vous avez cliqué!")
},
}Cette action peut ensuite être appelée avec:
bouton.action()On peut également passer une fonction en paramètre à une autre
fonction! Oui, c’est quelque chose de fréquent, surtout avec des
fonctions comme filter() (une fonction de tableau), qui ne
gardent que les éléments d’un tableau correspondant au critère.
Exemple:
let notes = [4.5, 3.5, 5.5, 4.0, 3.5, 3.0, 6.0, 5.5, 4.5]
function plusPetitQue4(note) {
return note < 4.0
}
let notesInsuffisantes = notes.filter(plusPetitQue4)
console.log(notesInsuffisantes) // Affiche [3.5, 3.5, 3.0]Notez qu’on donne le nom de la fonction en
paramètre. Si on ajoutais les parenthèses, alors on appellerait
la fonction et on passerait le résultat de celle-ci. C’est bien
la fonction qui doit être passée car filter() va ensuite
l’appeler en interne.
Si on n’utilise cette fonction qu’à cet endroit du code, on peut utiliser une fonction annonyme comme ceci:
let notes = [4.5, 3.5, 5.5, 4.0, 3.5, 3.0, 6.0, 5.5, 4.5]
let notesInsuffisantes = notes.filter(function (note) {
return note < 4.0
})
console.log(notesInsuffisantes) // Affiche [3.5, 3.5, 3.0]Une fonction annonmye raccourcie peut également être utilisée en paramètres. Même exemple:
let notes = [4.5, 3.5, 5.5, 4.0, 3.5, 3.0, 6.0, 5.5, 4.5]
let notesInsuffisantes = notes.filter((note) => note < 4.0)
console.log(notesInsuffisantes) // Affiche [3.5, 3.5, 3.0]Tout ceci fonctionne car la fonction filter() prend en
paramètre une fonction bien précise:
D’autres fonctions requièrent d’autres formats.
Le JavaScript est tristement connu pour avoir un comportement inattendu lorsqu’on le pousse dans ses retranchements. Voici quelques exemples:
Assurez-vous de toujours savoir avec quel type de variable vous travaillez, car le résultat peut être incohérent dans le cas contraire.
Comme le JS est faiblement typé, on peut redéfinir une variable avec une valeur de type différent. Voici des exemples fonctionnels:
let a = 1 // a est un entier
a = 2 // a est toujours un entier
a = 4.2 // a est un nombre à virgule
a = "bonjour" // a est une chaine de caractères
a = () => "Hello, World!" // a est une fonction
a = {
cle1: "valeur 1",
cle2: "valeur 2",
} // a est un JSONLe fait que le JavaScript soit interprété implique que les erreurs dans le code ne sont pas détectées à la compilation (il n’y a d’ailleurs pas de compilation).
Prenons cet exemple:
let message = "Bonjour"
let rien
console.log(2 * message) // Affiche NaN
console.log(rien) // Affiche undefined
console.log("Hello, World!") // Affiche "Hello, World!"On ne peut pas effectuer de multiplication avec une chaine de
caractères et on ne peut pas afficher une variable non déclarée. Les
deux console.log ne se comportent pas comme on pourrait s’y
attendre, mais aucune erreur n’apparait et le programme continue de
s’exécuter comme si tout s’était bien déroulé.
En revanche, si une erreur de syntaxe est présente, alors le script en entier sera corrompu et rien ne se lancera.
Exemple:
console.log("Est-ce que ça fonctionne?")
let probleme =
let ok = trueAffichera dans la console:
SyntaxError: unexpected token: identifier
at script.js:3Dès lors, c’est comme si le fichier n’existait pas. Aucune partie de celui-ci ne sera exécuté. Le message “Est-ce que ça fonctionne?” ne sera pas affiché dans la console.
Si une variable n’est pas redéfinie plus tard dans le code, alors on préfère la considérer comme une constante.
Opérations interdites sur des constantes:
= (redéfinition)++, --
(incrémentation/décrémentation)+=, -=, *=, /=,
|=, &=, ^=, etc.
(modifications)Opérations autorisées sur les constantes:
. (accès aux attributs internes, pour un JSON)[] (accès aux données, pour un tableau). (accès aux fonctions)Dans la pratique, on a tendance à utiliser const au lieu
de let presque à chaque fois. Exemple:
const personne = {
prenom: "Klaus",
nom: "Trophobe",
age: 23,
}
personne.age++ // Possible car personne est constante, mais pas personne.age
for (let i = 0; i < personne.age; i++) {
// i change, donc let est obligatoire
console.log("J'ai eu " + i + " ans")
}
// ---
const notesICT = [4.5, 6.0, 5.5, 5.5, 5.0, 3.5, 4.5, 4.0, 5.5]
function moyenne(notes) {
// par défaut, un paramètre est modifiable
let somme = 0 // somme va changer, donc let est obligatoire
notes.forEach((note) => {
// parcourir un tableau avec une fonction anonyme ;-)
somme += note
})
return somme / notes.length
}
console.log("La moyenne est de " + moyenne(notesICT) + ".")Depuis quelques années, JavaScript possède un mode “strict”. Il améliore considérablement la rapidité du code, transforme quelques erreurs silencieuses en erreur explicites (exceptions) et prépare le code aux prochaines versions de JavaScript.
Pour définir qu’on utilise le mode strict, il suffit d’ajouter une chaine de caractères comme première ligne du fichier:
"use strict"
// codeLe mode strict devrait toujours être utilisé.
En JavaScript, il existe un mot-clé qui représente toutes sortes de
choses, selon le contexte. Ce mot-clé est this.

Voici les contextes dans lesquels this a une valeur:
console.log(this)Affiche le contenu de la variable globale window,
variable qui contient toutes les variables du programme.
function f() {
console.log(this)
}
f()Affiche le contenu de la variable globale window.
"use strict"
function f() {
console.log(this)
}
f()Affiche undefined.
const objet = {
donnee: 42,
f: function () {
console.log(this)
},
}
objet.f()Affiche l’objet. Ici:
{ donnee: 42, f: "function() { console.log(this) }" }.
NE MODIFIE PAS LA VALEUR DE THIS!
Exemples:
"use strict"
// this == window
const objet = {
f1: function () {
// this == objet
},
f2: () => {
// this == window
},
}
function fonction1() {
// this == undefined
const objet1 = {
f1: function () {
// this == objet1
},
f2: () => {
// this == undefined
},
}
}
const fonction2 = () => {
// this == window
const objet2 = {
f1: function () {
// this == objet2
},
f2: () => {
// this == window
},
}
}Il existe donc une différence entre function() {} et
() => {}: this est modifié dans une
fonction avec mot-clé et reste tel quel avec une fonction-flèche.
On peut savoir ce que représente this en trois règles
simples:
this vaut
window.function, on redéfinit
this à l’élément englobant la fonction.function à la racine du code redéfinit this à
undefined.Lorsqu’on programme en C♯, il est facile d’analyser le contenu des variables grâce au mode pas-à-pas (mettre un point d’arrêt et lancer le programme). Il serait intéressant d’avoir la même chose en JavaScript!
Et bien devinez quoi: on peut!
Voici comment réaliser cet exploit:
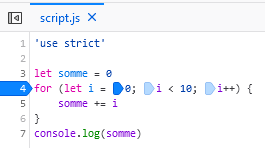
Les actions possibles, à ce moment-là, sont:
Les valeurs des différentes variables sont disponibles dans le menu:
On peut également voir leur valeur en survolant la variable.
La page d’accueil de jQuery.com indique ceci:
jQuery est une bibliothèque JavaScript rapide, compacte et riche. Elle réalise des choses comme le parcours et la manipulation de documents HTML, la gestion d’évènements, l’animation ou encore les requêtes AJAX, d’une manière très simple et avec une API fonctionnant sur une multitude de navigateurs. Avec une combinaison de versatilité et d’extensibilité, jQuery a changé la façon d’écrire du JavaScript pour des millions de personnes.
jQuery est donc une bibliothèque JavaScript qui simplifie le code, le rend plus lisible, plus facile à utiliser et plus efficace.
Lorsqu’on crée une page web, on peut utiliser jQuery, on peut ne pas utiliser jQuery, mais il est dangereux de mélanger jQuery avec du JavaScript natif!

Lorsqu’on souhaite atteindre l’élément
<div id="app"></div> par son identifiant
id
Pure javascript
const element = document.querySelector('#app')
console.log(element)Retourne
<div id="app">jQuery
const element = $('#app')
console.log(element)Retourne
Object { 0: div#app, length: 1 }jQuery ne fournit pas grand chose. En fait, il ne fournit qu’une
seule chose: une fonction appelée jQuery.
Cette fonction possède un alias bien pratique: $. Ainsi,
lorsqu’on désire utiliser jQuery(), on peut à la place
utilise $(), qui rend le code encore plus simple.
Nous l’avons vu avec les bases de JavaScript, on peut définir qu’un
script doit se lancer lorsque le DOM est prêt et non au moment où
l’inclusion du fichier JS est faite. jQuery propose d’utiliser sa propre
mise en place de ceci. Ainsi, au lieu d’ajouter le mot-clé
defer, on peut aussi placer le code JS dans la fonction
suivante:
$(function () {
// Votre code ici
})Vous reconnaitrez ici une fonction ($) qui prend une
fonction anonyme en paramètre.
Bien sûr, les variantes suivantes sont possibles:
function init() {
// Votre code ici
}
$(init)
// ---
const init = () => {
// Votre code ici
}
$(init)
// ---
$(() => {
// Votre code ici
})
// ---
jQuery(document).ready(function () {
// Votre code ici
})Cette dernière version est une ancienne manière de faire que vous trouverez peut-être dans la littérature. Elle est encore utilisable, mais sa syntaxe est lourde.
NOTE: si vous avez plusieurs occurrences de
$(function(){}) dans votre code, elles seront toutes
appelées lorsque le DOM est prêt.
Bien qu’il soit possible d’installer jQuery, ceci n’est pas nécessaire. Nous pouvons pour cela utiliser un CDN, c’est-à-dire utiliser un dépôt distant sur lequel jQuery se trouve.
Rendez-vous sur code.jquery.com
et cliquez sur “minified” à côté de la version jQuery Core
3.X.X. Ceci vous ouvre une fenêtre popup pour vous indiquer le code
à ajouter à votre <head>.
Par exemple:
<script
src="https://code.jquery.com/jquery-3.0.1.min.js"
integrity="sha256-2Pmvv0kuTBOenSwLm6bvfBSSHruJ+3A7x6P5Edb07/g="
crossorigin="anonymous"
></script>ATTENTION: afin de rester à jour avec la dernière version de la technologie, le code ci-dessus ne fonctionne pas! Rendez-vous de toute façon sur le site officiel pour prendre la dernière version!
Si vous désirez néanmoins télécharger jQuery, il vous suffit de le
charger depuis le fichier local que vous aurez téléchargé quelque part
dans le répertoire de votre application plutôt que depuis le CDN. Pour
ce faire, utilisez la ligne
<script src="chemin/local/vers/jquery-3.0.0.min.js"></script>.
Faites attention de bien télécharger la version minifiée (allégée) de
jQuery. La version minifiée est celle qui se termine par .min.js, c’est
exactement le même code que la version non-minifiée, mais tous les
caractères inutiles ont été supprimés (espaces, retours à la ligne,
etc.)
| CDN | Téléchargement | |
|---|---|---|
| Avantage | Éventuellement mis en cache par d’autres sites | Peut être utilisé offline |
| Inconvénient | Nécessite une connexion Internet | Augmente la taille du projet |
Avec du JavaScript natif, si on désire sélectionner un élément du DOM, la fonction est assez complexe, même si elle se base sur les sélecteurs CSS déjà connus:
const menu = document.querySelector("#menu")
const titres = document.querySelectorAll("h1")
const liensExternes = document.querySelectorAll("a.externe")Avec jQuery, on peut passer le sélecteur directement à la fonction
$ ainsi:
const menu = $("#menu")
const titres = $("h1")
const liensExternes = $("a.externe")On peut également utiliser la syntaxe complexe du CSS:
$("div .titre") // Les éléments de classe "titre" contenus dans un div
$("div > p") // Les éléments p enfants directs d'un div
$("span, #zone, .content") // Les éléments span,
// ou l'élément avec l'ID "zone"
// ou les éléments de la classe "content"
$("input:checked") // Les inputs qui sont cochésNous avons vu, jusqu’à présent, deux utilisations de la fonction
$: elle peut prendre en paramètre une fonction ou une
chaine de caractère représentant un sélecteur.
Voyons directement trois fonctions simples avec jQuery:
.text, .html et .val.
Ces fonctions s’appliquent à un sélecteur et permettent d’accéder au contenu de celui-ci en lecture ou en écriture.
<body>
<p id="texte">Ceci est un <strong>texte</strong>.</p>
<input id="champ" type="text" />
</body>// En lecture
const texteText = $("#texte").text() // "Ceci est un texte."
const texteHtml = $("#texte").html() // "Ceci est un <strong>texte</strong>."
const champVal = $("#champ").val() // Ce que l'utilisateur a tapé dans le champ
// En écriture
$("#texte").text("Voici un <em>autre</em> texte") // "Voici un <em>autre</em> texte"
$("#texte").html("Voici un <em>autre</em> texte") // "Voici un <em>autre</em>; texte"
$("#champ").val("contenu") // Le contenu du champ est changé et éditableC’est un standard avec jQuery:
.text() s’utilise sur un élément ayant un contenu,
quand on n’aimerait obtenir que le texte:
<balise>LE CONTENU SE TROUVE ICI</balise>..html() s’utilise de la même manière, mais permet de
récupérer également les balises internes et non uniquement le
texte..val() s’utilise sur les champs d’un formulaire
(<input>, <textarea> et
<select>) quand on désire obtenir le contenu placé
par l’utilisateur:
<input value="LE CONTENU SE TROUVE ICI">,
<textarea>LE CONTENU SE TROUVE ICI</textarea>
ou
<select><option value="LE CONTENU SE TROUVE ICI">texte</option></select>.Nous avons vu comment lire et modifier le contenu des balises, nous allons maintenant voir comment modifier le DOM en lui-même: ajouter, déplacer, modifier ou supprimer des éléments.
Pour créer un nouvel élément, deux méthodes sont possibles. Premièrement, on peut écrire le code HTML du nouvel élément et ajouter ce texte à un élément existant.
Dans les exemples ci-dessous, l’élément
<div id="elem"> existe déjà et on aimerait y ajouter
un élément:
$("#elem").append("<p>nouveau</p>") // Ajout après les éléments existants
$("#elem").prepend("<p>nouveau</p>") // Ajout avant les éléments existants
$("#elem").html("<p>nouveau</p>") // Remplace les éléments enfants existants
$("#elem").replaceWith("<p>nouveau</p>") // Remplace #elem par le <p>
$("#elem").wrap("<p>nouveau</p>") // Encapsule #elem dans le <p>jQuery permet de détecter très aisément des évènements et de lancer
le code adéquat lorsque ceux-ci se produisent. Tout ceci avec une seule
fonction: .on.
Pour lier un évènement à une fonction, la fonction .on
est utilisée. Celle-ci prend deux paramètres:
string)function)Par exemple, si j’aimerais afficher un message dans la console lorsque je clique sur le titre de la page, je pourrais placer le code suivant dans le JavaScript:
$("h1#titre-principal").on("click", function () {
console.log("Le titre a été cliqué")
})jQuery permet également de déclencher un évènement, c’est-à-dire de
réaliser l’évènement depuis le code. Ceci se fait avec la fonction
.trigger.
Par exemple, si j’aimerais afficher le message précédemment défini dans la console, au lieu de rappeler la fonction anonyme (ce qui n’est pas possible), je peux cliquer sur le titre depuis le code:
$("h1#titre-principal").trigger("click")Voici la liste exhaustive des évènements existants dans la version actuelle au moment de la rédaction du cours (jQuery-3.7.0):
| Évènement | Explication sommaire |
|---|---|
blur |
l’élément sélectionné ne l’est plus |
change |
Le champ voit son contenu changer |
click |
Un clic est effectué sur l’élément |
contextmenu |
Un clic droit est effectué sur l’élément |
dblclick |
Un double-clic est effectué sur l’élément |
error |
L’élément (typiquement une image) n’a pas été chargé correctement |
focus |
L’élément est sélectionné |
focusin |
L’élément ou l’un de ses enfants est sélectionné |
focusout |
L’élément ou l’un de ses enfants sélectionné ne l’est plus |
keydown |
Une touche du clavier est appuyée alors que l’élément est sélectionné |
keypress |
Une touche du clavier est pressée alors que l’élément est sélectionné |
keyup |
Une touche du clavier est relâchée alors que l’élément est sélectionné |
load |
L’utilisateur arrive sur la page |
mousedown |
Un bouton de la souris est appuyé sur l’élément |
mouseenter |
Le curseur arrive sur l’élément |
mouseleave |
Le curseur quitte l’élément |
mousemove |
Le curseur se déplace sur l’élément |
mouseout |
Le curseur quitte l’élément |
mouseover |
Le curseur arrive sur l’élément |
mouseup |
Un bouton de la souris est relâché sur l’élément |
resize |
L’élément est redimensionné |
scroll |
L’ascenceur de l’élément bouge |
select |
Le champ a une partie de son contenu sélectionné |
submit |
Le formulaire est envoyé |
unload |
L’utilisateur quitte la page |
Si on veut utiliser l’élément courant dans un évènement (par exemple
obtenir le texte d’un bouton lorsqu’on clique sur celui-ci), on peut
accéder à cet élément avec this, dans le contexte de
l’évènement (this représente la chose qui contient la
fonction, donc l’élément).
Cependant, this représente l’élément du DOM en lui-même
et non un objet jQuery possédant les fonctions de la bibliothèque.
Pour transformer un élément du DOM en objet jQuery, il suffit de le
passer à $().
Exemples:
$("#elem").on("click", function () {
this.text() // Erreur: .text() ne s'applique pas à un élément du DOM
$(this).text() // Fonctionne correctement
})
$("#elem").on("click", () => {
$(this).text() // Comportement inattendu! "this" n'a pas été réécrit par la fonction-flèche.
})AJAX est une méthode utilisant différentes technologies ajoutées aux navigateurs web entre 1995 et 2005, et dont la particularité est de permettre d’effectuer des requêtes au serveur web et, en conséquence, de modifier partiellement la page web affichée sur le poste client sans avoir à afficher une nouvelle page complète. Cette architecture informatique permet de construire des applications web et des sites web dynamiques interactifs. AJAX est l’acronyme d’asynchronous JavaScript and XML : JavaScript et XML asynchrones.
source: Wikipedia
Une explication complète du fonctionnement d’Ajax se trouve sur le site MDN Ajax.
La technologie Ajax est au coeur des sites web modernes puisqu’elle permet de charger des données sans recharger la page. On obtient donc des sites web dynamiques et réactifs.
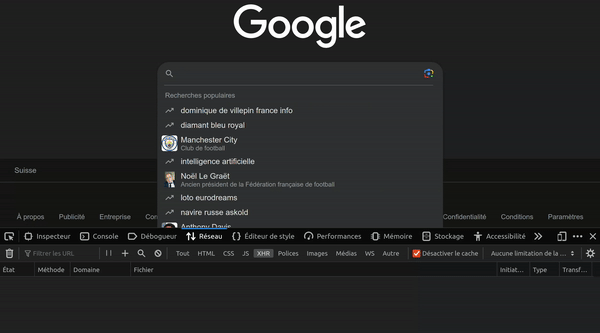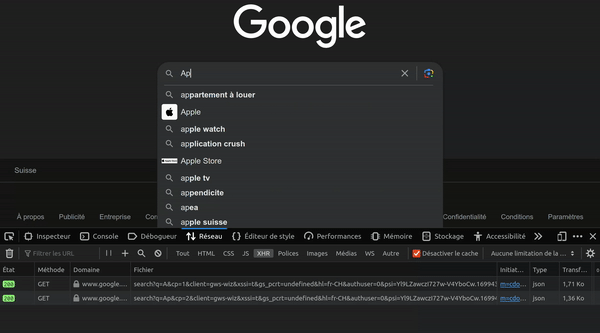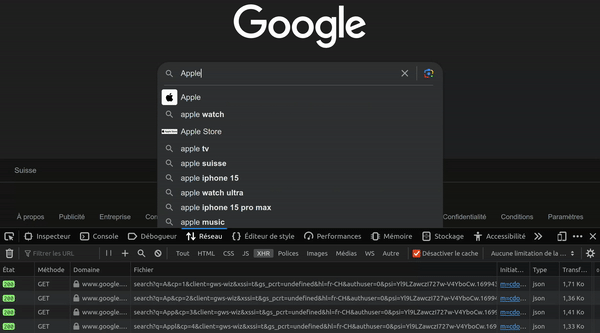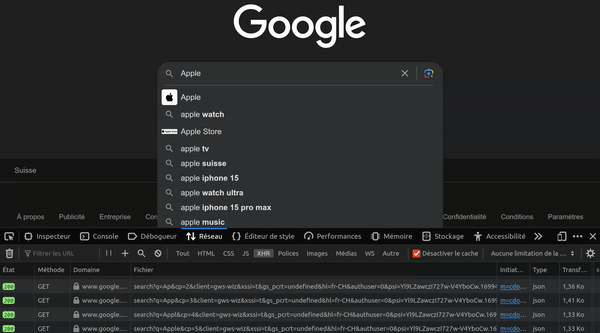
Dans l’exemple ci-dessus que vous connaissez bien, on peut voir qu’à chaque touche pressée au clavier, une requête Ajax est faite par le navigateur pour obtenir des suggestions de recherche. Ces suggestions sont affichées dans une liste déroulante dynamique en partant du flux JSON reçu en retour.
jQuery propose plusieurs fonctions pour effectuer des requêtes AJAX.
La principale est jQuery.ajax(), mais il existe des
raccourcis et des options supplémentaires.
La fonction passe-partout jQuery.ajax() s’utilise avec
deux paramètres: l’URL (string) et la configuration
(JSON).
Voici un exemple de requête AJAX dans son contexte:
$.ajax("https://jsonplaceholder.typicode.com/users/1", {
method: "GET",
success: function (response) {
console.log(`Nom: ${response.name}`)
console.log(`Email: ${response.email}`)
},
fail: function () {
console.error("Il y a eu un problème lors de la récupération des données")
},
})Le code ci-dessus nécessite quelques explications:
https://jsonplaceholder.typicode.com/users/1.$.ajax prend, comme second paramètre, un
JSON contenant 4 attributs: method, data,
success, fail. Il y a en tout 34 attributs
possibles, détaillés sur la page de documentation jQuery.ajax. Sachez que
tous ces attributs sont facultatifs car ils possèdent tous une valeur
par défaut.
method indique que la méthode HTTP à utiliser pour la
requête est GET.data contient, sous la forme d’un JSON, les données
nécessaires au server afin de réaliser l’action demandée.success est la fonction qui sera appelée lorsque le
serveur aura répondu avec un code “200 OK” (tout s’est bien passé). Le
paramètre response est la réponse de celui-ci.fail est la fonction qui sera appelée lorsque le
serveur aura répondu avec un code “4xx” ou “5xx” (erreur côté client ou
côté serveur).jQuery propose deux méthodes raccourcies pour l’utilisation d’AJAX en
GET et en POST: $.get et $.post.
Voici le code ci-dessus, traduit avec ce raccourci:
$.get(
"https://jsonplaceholder.typicode.com/users/1",
function (response) {
console.log(`Nom: ${response.name}`)
console.log(`Email: ${response.email}`)
}
).fail(function () {
console.error("Il y a eu un problème lors de la récupération des données")
})La fonction prend trois paramètres:
La fonction à appeler lors d’erreur n’est pas incluse dans cet alias
raccourci et doit être ajoutée ainsi:
$.get(...).fail(...).
fetch est une fonction native de JavaScript qui permet
de faire des requêtes AJAX. Elle est plus récente que
jQuery.ajax et est plus simple à utiliser.
try {
const response = await fetch(`https://jsonplaceholder.typicode.com/users/1`)
const json = await response.json()
} catch (error) {
console.error("Il y a eu un problème lors de la récupération des données")
}fetch est une
fonction asynchronefetch ne peut pas être utilisé directement à la racine
d’un script sauf si ce dernier est intégré en tant que
module.
<!-- index.html -->
<script src="script.js"></script>// script.js
const response = await fetch(`https://jsonplaceholder.typicode.com/users/1`)
const json = await response.json()On doit donc:
// script.js
const getData = async () => {
const response = await fetch(`https://jsonplaceholder.typicode.com/users/1`)
const json = await response.json()
}
// wait until dom is loaded
document.addEventListener('DOMContentLoaded', async () => {
await getData()
})<!-- index.html -->
<script type="module" src="script.js"></script>Pour pouvoir effectuer la requête
https://jsonplaceholder.typicode.com/users/1, le site
jsonplaceholder.typicode.com doit accepter les requêtes
multiorigines et heureusement, c’est le cas. Mais essayez de faire une
requête fetch sur le site de meteosuisse
alors que votre navigateur est sur votre site personnel
meteo.local ! La requête sera bloquée par le navigateur.
C’est une mesure de sécurité pour éviter les attaques de type CORS.
// script.js depuis meteo.local
const meteosuisse = await fetch('https://www.meteosuisse.admin.ch/product/output/versions.json')
Blocage d’une requête multiorigines (Cross-Origin Request) : la politique « Same Origin » ne permet pas de consulter la ressource distante située sur https://www.meteosuisse.admin.ch/product/output/versions.json. Raison : l’en-tête CORS « Access-Control-Allow-Origin » est manquant. Code d’état : 200.
Uncaught (in promise) TypeError: NetworkError when attempting to fetch resource. RecettesLe projet consiste à développer une application web interactive (donc en JavaScript) en utilisant une API permettant de gérer un livre de recettes partagé.
On vous fourni le code source permettant de mettre en place le serveur web. Celui-ci est écrit en PHP et utilise une base de données MySQL. Le code est accessible à cette adresse.
Prérequis:
L’installation est documentée sur le dépôt Git.
public. Par exemple
/var/www/recettes/public ou
C:\Laragon\www\recettes\public.Pour Apache, ça donnerait quelque chose comme ceci:
<VirtualHost _default_:443> (ou <VirtualHost *:80> si vous n'avez pas de certificat SSL)
ServerName recettes.local
DocumentRoot /var/www/recettes/public
...
<Directory /var/www/recettes/>
Require all granted
AllowOverride All
</Directory>
...
ErrorLog ${APACHE_LOG_DIR}/recettes.error.log
CustomLog ${APACHE_LOG_DIR}/recettes.access.log combined
</VirtualHost>/var/www/html ou
C:\Laragon\www\recette.app,
public, et writable ainsi que les fichiers
env et composer.*.recettes avec un utilisateur
recette_u@localhost ayant comme mot de passe
recette_p. Octroyez lui tout les droits mais uniquement sur
la base recettes. Utilisez le jeu de caractères
utf8mb4 et le collation
utf8mb4_general_ci.env situé à la racine du projet et
nommer cette copie .env..env en précisant:
app.baseURL: l’URL de la racine du site, avec le
protocole (http:// ou https://)database.*: les données de connexion à la base de
données, avec le nom de la base de données, l’utilisateur, le mot de
passe etc.rwx pour le répertoire
writable de manière récursive
(chmod -R 775 writable 775 pour les dossiers
664 pour les fichies et
chown -R root:www-data writable)composer.json forcer la version de
codeigniter à 4.4.3 pour éviter les erreurs de
compatibilité "codeigniter4/framework": "4.4.3" .$ composer install ou
$ composer updatePOST /reset/var/www/recettes# tree -L 2
.
├── app
│ ├── Common.php
│ ├── Config
│ ├── Controllers
│ ├── Database
│ ├── Filters
│ ├── Helpers
│ ├── Language
│ ├── Libraries
│ ├── Models
│ ├── ThirdParty
│ ├── Views
│ └── index.html
├── composer.json
├── composer.lock
├── public
│ ├── favicon.ico
│ ├── index.php
│ ├── logo.svg
│ ├── robots.txt
│ └── web.config
├── vendor
│ ├── autoload.php
│ ├── bin
│ ├── codeigniter4
│ ├── composer
│ ├── laminas
│ ├── myclabs
│ ├── nikic
│ ├── phar-io
│ ├── phpunit
│ ├── psr
│ ├── sebastian
│ ├── steevedroz
│ └── theseer
└── writable
├── cache
├── debugbar
├── logs
├── session
└── uploadsCette API a sa source à l’adresse que vous aurez défini, par exemple
https://recettes.local et sa description au même endroit.
Voici une description sommaire de tous les points de terminaison:
Vous devez développer une application web interactive (en JavaScript) capable d’intéragir avec l’API fournie. Votre application doit être capable de gérer les recettes.
Plus concrétement, le navigateur reçoit une page html contenant une
balise main ou div vide et c’est le code
javascript qui va se charger de la remplir.
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Recettes</title>
<link rel="stylesheet" href="css/style.css">
</head>
<body>
<header>
<h1>Recettes</h1>
</header>
<main id="ctn_recettes"></main>
<script src="js/script.js" type="module"></script>
</body>
</html>L’application peut faire des choses au-delà de la gestion de recettes, mais cet aspect doit rester le point central.
Au fur et à mesure que vous avancez dans votre travail, vous commencez à vous rendre compte qu’il y a la possibilité d’organiser votre code selon le travail qu’il doit accomplir. On y trouve:
REST Client
const getRecettes = async () => { ... }
const getRecette = async (slug) => { ... }
const createRecette = async (formData) => { ... }
const updateRecette = async (slug, formData) => { ... }
const deleteRecette = async (slug) => { ... }Card
const addCard = (card, containerId) => { ... }
const createCard = (recette) => { ... }
const deleteCard = (id) => { ... }
const updateCard = (id, recette) => { ... }Formulaire
const toggleForm = (form_name) => { ... }
const flushForm = (form_name) => { ... }
const validateForm = (form_name) => { ... }
const getFormData = (form_name) => { ... }
const setFormData = (form_name, recette) => { ... }Gestion des événements
const actionCancel = (event) => { ... }
const actionShowForm = (event) => { ... }
const actionCreate = async (event) => { ... }
const actionUpdate = async (event) => { ... }
const actionDelete = async (event) => { ... }
const actionShowRecette = async (event) => { ... }
const actionShowRecettes = async (event) => { ... }Une fois le code organisé ainsi, pour permettre par exemple, à l’utilisateur de créer une nouvelle recette, il suffit de passer par les actions suivantes:
Pré-requis:
Étapes au chargement du formulaire:
On binde l’événement click du bouton “Créer” avec la
fonction actionCreate. Dans cette fonction, on va:
validateForm.getFormData.createRecette.createCard.addCard.flushForm.toggleForm.Ce qui donne le code suivant:
const actionCreate = async (event) => {
toggleForm('form')
const isValid = validateForm('form')
if (!isValid) return
const formData = getFormData('form')
const recette = await createRecette(formData)
const card = createCard(recette)
addCard(card, 'ctn_recettes')
flushForm(form)
toggleForm(form)
}
document.getElementById('btn_create').addEventListener('click', actionCreate)Cette organisation de code nous aménera naturellement à l’utilisation
des classess et des modules. En effet, on peut imaginer que chaque
partie de l’application soit un module qui contient des classes. Par
exemple, le module Recette contient une classe qui va gérer
tout ce qui concerne les requêtes REST à l’API recettes, le module
Card va gérer tout ce qui concerne les cartes, le module
Form va gérer tout ce qui concerne les formulaires. Le
module App va gérer tout ce qui concerne l’application.
Lorsque vous écrivez du code Javascript, il est important de le rendre le plus générique possible. Par exemple, lorsque vous souhaitez valider un formulaire, vous pouvez le faire de manière NON générique
const validateForm = (formId) => {
let isValid = true
const form = document.getElementById(formId)
const nom = form.querySelector('input[name="nom"]').value
const description = form.querySelector('input[name="description"]').value
const preparation = form.querySelector('input[name="preparation"]').value
const nombrePersonnes = form.querySelector('input[name="nombrePersonnes"]').value
if(!nom || !description || !preparation || !nombrePersonnes) {
isValid = false
alert('Veuillez remplir tous les champs')
return
}
if(nom.length < 3) {
alert('Le nom doit faire au moins 3 caractères')
isValid = false
return
}
if(description.length < 10) {
isValid = false
alert('La description doit faire au moins 10 caractères')
return
}
if(preparation.length < 10) {
isValid = false
alert('La préparation doit faire au moins 10 caractères')
return
}
if(nombrePersonnes < 1) {
isValid = false
alert('Le nombre de personnes doit être supérieur à 0')
return
}
return isValid
}Dans cette version, le code est écrit pour un formulaire spécifique. Il ne peut pas être réutilisé pour d’autres formulaires. De plus, si le formulaire change, par exemple, si on ajoute ou on supprime un champ, il faut changer le code.
Ou alors le faire de manière GÉNÉRIQUE. Dans cette version, le code est écrit pour n’importe quel formulaire. Il peut être réutilisé pour d’autres formulaires. De plus, si le formulaire change, il n’est pas nécessaire de changer le code.
Pour pouvoir le rendre générique, on utilise une fonctionnalité
Javascript qui s’appelle validity. Cette fonctionnalité
permet de savoir si un champ est valide ou non. Par exemple, si on a un
champ de type nom, que ce champ est required
et que la taille minimale du texte est de minlength="3" et
bien validity.valid sera true si tout est
respecté et false dans le cas contraire.
<div id="form">
<input type="text" name="nom" required minlength="3" placeholder="Nom de la recette">
<input type="text" name="description" required minlength="10" placeholder="Description de la recette">
<input type="text" name="preparation" required minlength="10" placeholder="Préparation de la recette">
<input type="number" name="nombrePersonnes" required min="1" placeholder="Nombre de personnes">
<button type="submit">Créer</button>
</div>const validateForm = (formId) => {
const form = document.getElementById(formId)
let valid = true
const inputs = form.getElementsByTagName('input')
for (let input of inputs) {
if(!input.validity.valid) {
console.error(`${input.name} ${input.validationMessage}`)
valid = false
}
}
return valid
}Dans la même veine, on peut rendre générique la récupération des données d’un formulaire. En effet, si on a un formulaire avec plusieurs champs, il est possible de récupérer les données de tous les champs en une seule fois.
const getFormData = (formId) => {
const form = document.getElementById(formId)
const inputs = form.getElementsByTagName('input')
const formData = {}
for (let input of inputs) {
formData[input.name] = input.value
}
return formData
}L’inverse fonctionne aussi
const pushData = (formId, formData) => {
const form = document.getElementById(formId)
const inputs = form.getElementsByTagName('input')
for (let input of inputs) {
input.value = formData[input.name]
}
}Pour finir ces TIPS, il faut vous rappelez qu’un objet
Javascript n’est pas imuable bien au contraire. Il est possible de lui
ajouter des propriétés et de les modifier à tout moment. Par exemple, si
on a un objet formData qui contient les valeurs présentes
dans le forumulaire, on peut lui ajouter des propriétés à tout
moment.
AVANT
const formData = {
"description": "Des oeufs pochés dans une sauce au vin rouge",
"nom": "Oeufs en meurette",
"nombrePersonnes": 4,
"preparation": "1. Faire bouillir 1 l d'eau...",
"slug": "oeufs-en-meurette",
}
formData.action = actionUpdateRecette
formData.title = "Modifier Oeufs en meurette"APRES
Maintenant, formData contient:
{
"action": async function actionUpdateRecette(event)
"title": "Modifier Oeufs en meurette"
"description": "Des oeufs pochés dans une sauce au vin rouge"
"nom": "Oeufs en meurette"
"nombrePersonnes": 4
"preparation": "1. Faire bouillir 1 l d'eau..."
"slug": "oeufs-en-meurette"
}Javascript est un langage Mono-Thread. Pourtant, on peut utiliser des codes asynchrones! Comment est-ce possible ?
La réponse se trouve dans la Loop. La Loop est une boucle qui permet de gérer les événements et les tâches asynchrones. Elle est composée de plusieurs parties décrites plus bas ainsi que dans la vidéo. L’asynchronisme est rendu possible grâce à la délégation des tâches au navigateur. En effet, c’est lui qui est mutli-thread et qui permet de gérer des tâches asynchrones.
setTimeout ou fetch.Promise tel que la
fonction fetch. Elle passe avant la
Task Queue.Task tel que
setTimerout, setInterval.Comment savoir si une fonction est une Task ou si elle retourne une Promise ?
Soit on a l’habitude du langage et on le sait, soit on va voir la documentation de la fonction en question. Par exemple, pour la fonction fetch(), on peut voir sur MDN que cette fonction retourne une Promise.
Return value
A Promise that resolves to a Response object.
J’ai le code suivant:
const getUser = async (id) => {
const response = await fetch(`https://jsonplaceholder.typicode.com/users/${id}`)
const json = await response.json()
return json
}
const main = document.getElementById('app')
const user = getUser(1)
const card = document.createElement('div')
card.classList.add('card')
card.innerHTML = `
<h1>${user.name}</h1>
<p>${user.email}</p>
<p>${user.phone}</p>
`
main.appendChild(card)Malheureusement, je n’obtiens pas l’affichage escompté. Pourquoi ?
Dans quel ordre se déroule le code suivant ?
const request = async () => {
// moins de 100ms pour obtenir la réponse
const response = await fetch('https://jsonplaceholder.typicode.com/users/1')
const json = await response.json()
console.log(1)
return json
}
const getBody = () => {
const body = document.getElementsByTagName('body')
console.log(2)
return body
}
setTimeout(() => console.log(3), 10)
queueMicrotask(() => {
console.log(4)
queueMicrotask(() => console.log(5))
})
getBody()
console.log(6)
await request()Javascript est un langage d’héritage par prototype. C’est-à-dire que
chaque objet possède un lien <prototype> qui
définit une liaison à un objet duquel il hérite. Ce lien peut également
être null si l’objet n’hérite de rien.
Référence: Object prototypes
Par exemple, si on déclare un Number:
» let n = new Number(1)On obtient la structure suivante:
» n
🢓 Number { 1 }
🢓 <prototype>: Number { 0 }
constructor: function Number()
toExponential: function toExponential()
toFixed: function toFixed()
toLocaleString: function toLocaleString()
toPrecision: function toPrecision()
toString: function toString()
valueOf: function valueOf()
🢓 <prototype>: Object { … }
__defineGetter__: function __defineGetter__()
__defineSetter__: function __defineSetter__()
__lookupGetter__: function __lookupGetter__()
__lookupSetter__: function __lookupSetter__()
__proto__:
constructor: function Object()
hasOwnProperty: function hasOwnProperty()
isPrototypeOf: function isPrototypeOf()
propertyIsEnumerable: function propertyIsEnumerable()
toLocaleString: function toLocaleString()
toString: function toString()
valueOf: function valueOf()
<get __proto__()>: function __proto__()
<set __proto__()>: function __proto__()On voit dans cette structure que n est un
Number qui hérite de Object. On peut donc
faire appel aux méthodes contenues dans Number et dans
Object:
» n.toString()
"1"
» n.valueOf()
1
» n.toFixed(2)
"1.00"
» n.my_property = "Hello"
"Hello"
» n.hasOwnProperty('my_property')
true On commence par faire un Array contenant des lettres
let tab = [ 'a', 'b', 'c' ]
» tab
🢓 Array(3) [ "a", "b", "c" ]
0: "a"
1: "b"
2: "c"
length: 3
🢓 <prototype>: Array []On peut directement voir le lien <prototype> qui
nous lie à Array. Notre tab est donc un
Array. C’est ce qui nous permet de faire:
tab.map(i => String.fromCodePoint((i.charCodeAt() + 1)))
Array(3) [ "b", "c", "d" ]Dans la même idée, disons que nous créeons un objet vide :
let obj = {}
alert(obj) // "[object Object]" ?Où est le code qui génère la chaîne “[object Object]” ? C’est une méthode toString intégrée, mais où est-elle ? L’objet obj est vide !
» obj
🢓 Object { }
🢓 <prototype>: Object { … }
__defineGetter__: function __defineGetter__()
__defineSetter__: function __defineSetter__()
__lookupGetter__: function __lookupGetter__()
__lookupSetter__: function __lookupSetter__()
__proto__:
constructor: function Object()
hasOwnProperty: function hasOwnProperty()
isPrototypeOf: function isPrototypeOf()
propertyIsEnumerable: function propertyIsEnumerable()
toLocaleString: function toLocaleString()
toString: function toString()
valueOf: function valueOf()
<get __proto__()>: function __proto__()
<set __proto__()>: function __proto__()On peut la voir dans le prototype Object..
Javascript est très maléable. Ainsi, on peut facilement modifier le prototype. Par exemple:
Array.prototype.caesar = function(n) {
return this.map(i => 'string' === typeof i ? String.fromCodePoint((i.charCodeAt() + n)) : i)
}
tab = [ 1, 'a', 'b' ]
tab.caesar(3)
Array(3) [ 1, "d", "e" ]Travailler seul dans une application telle que recette
est facile à gérer. On développe ses pages Javascript comme on veut, on
utilise des $.get et $.post quand on le
souhaite et on peut même imbriquer tout ça.
$.ajax({
type: 'GET',
url: `${baseUrl}/recettes/${slug}`,
dataType: 'json',
success: (response) => {
showRecette(recette = response.data)
const recetteInfo = explodeInfos(response.data)
$.ajax({
type: 'GET',
url: `${baseUrl}/recettes/${slug}/ingredients`,
dataType: 'json',
success: (response) => {Le problème devient bien plus complexe si on travail à plusieurs sur le même projet. Il faut alors se mettre d’accord sur une manière de travailler, sur une manière de nommer les variables, sur une manière de structurer le code etc. Il faut également éviter de se marcher sur les pieds et de modifier le code de l’autre au risque de devoir gérer des conflits lors des merge requests.
Dans l’exemple ci-dessus, on voit que le code gère aussi bien les accès REST que les recettes ou encore les ingrédients. Il serait intéressant de séparer ces aspects afin de pouvoir travailler dessus indépendamment. Une personne s’occuperait des recettes, une autre des ingrédients et une troisième se chargerai de l’API REST.
C’est ici qu’interviennent les modules.
Inutile d’expliquer ici ce qui est déjà expliqué ailleurs:
À l’aide des modules, on peut réaliser l’arborescence suivante:
.
├── js
│ ├── main.js
│ ├── recette.js
│ ├── ingredient.js
│ └── http.js
├── images
├── css
└── index.htmlChaque module s’occupe d’une partie du site web et chaque personne s’occupe d’un module.
main.js est le point d’entrée de
l’application. Il s’occupe de charger les autres modules, de faire la
configuration et de lancer l’application.http.js s’occupe de gérer les requêtes AJAX.
Il est utilisé par les autres modules.recette.js et ingredient.js
s’occupent de gérer les recettes et les ingrédients respectivement.import { Recette } from "./recette.js"
import { Ingredient } from "./ingredient.js"import { http } from "./http.js"import { http } from "./http.js"export const http = {
get: async (url) => {
const response = await fetch(url)
return await response.json()
},
post: async (url, data) => {
...
return await response.json()
},
}En utilisant un backend tel que mockapi.io, on vous demande la réalisation d’une application Javascript SPA (Single Page Application) permettant de gérer des cartes de visites.
L’application sera scindée en plusieurs modules. Chaque module sera dédié à une partie de l’application. Par exemple:
Component permettant de générer la partie
HTML / CSS d’une carteAPI permettant de gérer les requêtes REST
(CRUD)App permettant de gérer l’application dans
son ensemblePlutôt que de travailler avec des formulaires, on utilisera la propriété universel contenteditable des éléments HTML pour permettre la modification des cartes et les événements tel que input pour gérer les modifications au travers du service REST.
La mise en page sera réalisée avec des flexbox et/ou des grid. Cela assurera un minimum de responsivité.
L’emploi d’une librairie tel que Bootstrap ou TailwindCSS est autorisé et même recommandée.
source: bootdey.com
Imaginez une application nommée screen. Cette
application fait office de borne d’affichage telle qu’on
pourrait en trouver à l’entrée de l’école. Elle affiche différentes
informations qui sont toutes issues de différentes API REST.
Divisez l’écran en autant de partie qu’il y a de participants au
projet. Dans chacune des parties de l’écran, vous devez développer une
partie de l’application screen sous forme de module.
Par exemple, avec 9 participants, l’écran pourrait être divisé en 9 parties ainsi :

On pourrait imaginer que l’application affiche par exemple :
.
├── js
│ ├── main.js
│ ├── meteo.js
│ ├── tn.js
│ ├── actual_meteo_ne.js
│ ├── git_users.js
│ └── http.js
├── images
├── css
└── index.htmlPour la gestion du dépôt gitlab, vous devez travailler selon la
méthode gitflow. Vous devez donc créer une branche
feature_mon_nom et travailler dessus. Une fois le travail
terminé, vous devez créer une merge request vers la branche
main. Une autre personne du groupe doit valider votre merge
request. Une fois la merge request acceptée, vous pouvez supprimer votre
branche.
On peut trouver des graphiques explicant le fonctionnement de gitflow sur internet. En voici un:
Spacetraders.io est un jeu en ligne multijoueur. Le but est de gérer une flotte de vaisseaux spatiaux afin de commercer entre les différentes planètes du jeu.
Le jeu est basé sur une API REST. Celle-ci est documentée à cette adresse. Il est possible de tester l’API directement depuis la documentation.
Vous devez développer une application web interactive (en JavaScript) capable d’intéragir avec l’API fournie. Votre application doit être capable de gérer les agents, les vaisseaux spatiaux, les systèmes stellaires etc. Un quickstart est disponible pour vous aider à démarrer.
L’API est décrite avec OpenAPI. Vous pouvez télécharger le fichier json et l’ouvrir avec Swagger Editor afin de visualiser l’API.
Une spécification complète peut également être consultée à cette adresse.
Installation de Node.js
Installation de java sudo apt install default-jre
Téléchargement de la spécification sinon ça ne fonctionne pas wget -O spacetraders “https://stoplight.io/api/v1/projects/spacetraders/spacetraders/nodes/reference/SpaceTraders.json?fromExportButton=true&snapshotType=http_service&deref=optimizedBundle”
Génération du client openapi-generator-cli generate -g javascript -i spacetraders -o spacetraders-sdk –additional-properties=npmName=“spacetraders-sdk” –additional-properties=npmVersion=“2.0.0” –additional-properties=supportsES6=true –additional-properties=withSeparateModelsAndApi=true –additional-properties=modelPackage=“models” –additional-properties=apiPackage=“api” –skip-validate-spec
MVC (Model-View-Controller ou Modèle-Vue-Contrôleur) est un modèle dans la conception de logiciels. Il met l’accent sur la séparation entre la logique métier et l’affichage du logiciel. Cette «séparation des préoccupations» permet une meilleure répartition du travail et une maintenance améliorée. Certains autres modèles de conception sont basés sur MVC, tels que MVVM (Model-View-Viewmodel), MTP (Model-View-Presenter) et MVW (Model-View-Whatever).
Les 3 parties du modèle de conception de logiciel MVC peuvent être décrites comme suit :
Plutôt qu’une longue théorie, je vous propose de réaliser l’exercice suivant Tania Rascia - MVC in JavaScript mais en adaptant l’exercice selon les points ci-dessous:
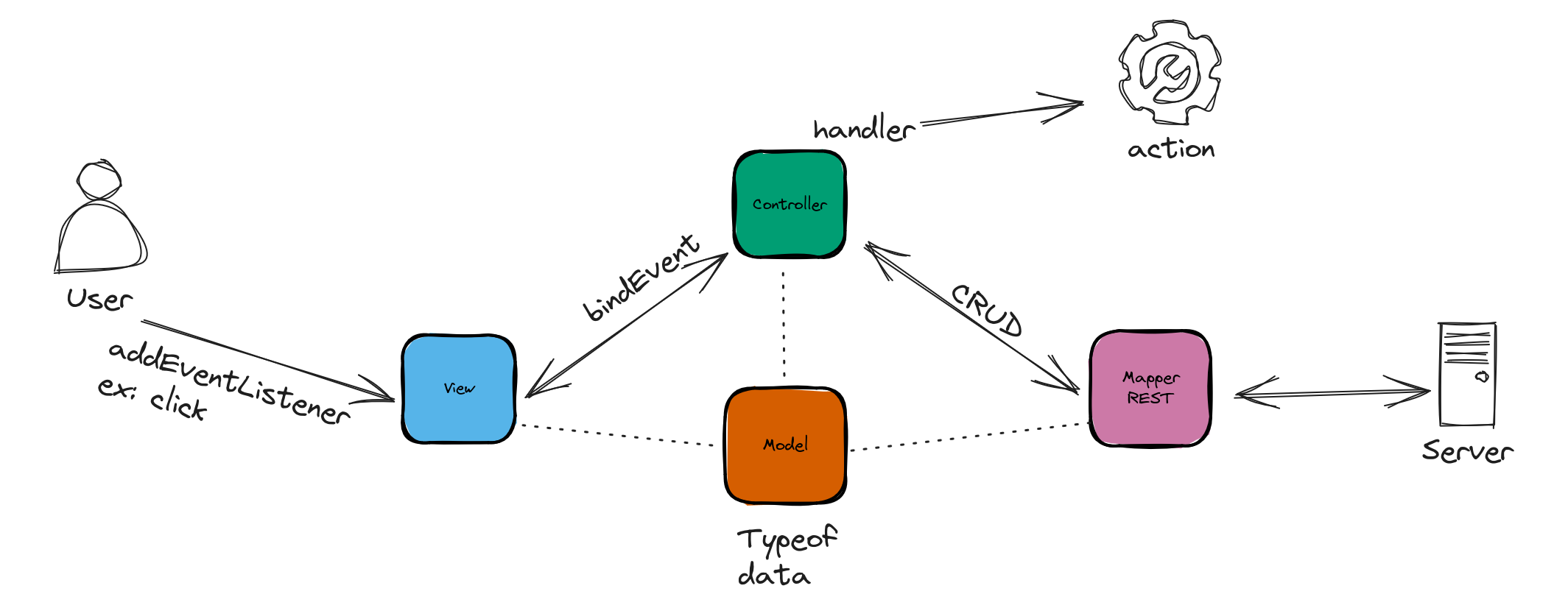
En résumé, le Model est là pour présenter les données
mais pas pour accéder aux données distantes. L’accès aux données
distantes se fait via le Mapper. L’idée est de découpler le
Model de l’accès aux données distantes. Le
Controller est là pour gérer les actions de l’utilisateur
en provenance de la View. Le contrôleur agit comme un chef
d’orchestre. Il est notifié par la vue des actions de l’utilisateur, il
interagit avec le Mapper afin de récupérer ou mettre à jour
les données et il demande à la View de les afficher. Le
Model est la pour décrire les données.
Ainsi, si on souhaite persister les données en base de données locals
SQLite par exemple, il suffit de changer le fonctionnement
du Mapper sans toucher au autres éléments.