
Utiliser un service avec des conteneurs
Un conteneur Linux est un terme générique pour une implémentation d’une forme de virtualisation au niveau du système d’exploitation. Il s’agit en effet d’une manière d’isoler un ou plusieurs processus qui tournent en leur créant un environnent qui sera différent, parfois à l’extrême, des autres processus tournant sur le même système d’exploitation.
Linux ne contient pas un système d’isolation unique, mais plusieurs mécanismes qui ont évolué au fil des années. Ces mécanismes sont utilisés ensemble pour générer cet effet d’isolation. Les mécanismes principaux du noyau Linux, sont les espaces de noms (namespace) et les groupes de contrôle (cgroups).
Les espaces de nom permettent au système de restreindre les ressources que voient les processus conteneurisés et garantissent qu’aucun d’entre eux ne peut interférer avec un autre.
Les groupes de contrôle quand à eux permettant de limiter la quantité des ressources utilisables par les processus conteneurisés.
Le « conteneur » peut ainsi définir par exemple; un système de fichiers qui sera différent, un nom d’hôte différent, limiter l’accès du processus à la mémoire, lui désigner une partie d’un nombre restreint des processeurs présents sur la machine.
À la différence de la virtualisation classique, une seule copie du système d’exploitation tourne sur la machine, les conteneurs utilisent ainsi moins de ressources en termes de mémoire.
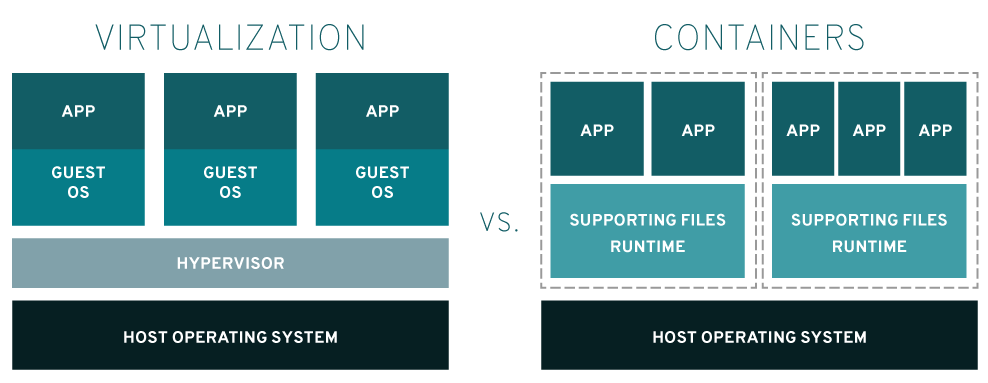
Lorsque vous exécutez de nombreux processus et applications différents sur une seule machine, il est important que chaque processus soit isolé, principalement pour la sécurité. Lorsque vous isolé un processus vous créez un conteneur. On peut donc donner la définition suivante:
Un conteneur c’est un ou plusieurs processus qui sont isolés au sein d’un même système d’exploitation
On voit la différence avec une machine virtuelle, dans l’image ci-dessus. À gauche, une machine virtuelle contient aussi l’application (APP) mais l’application fonctionne dans un système d’exploitation virtualisé (GUEST OS). Ces systèmes d’exploitations voient des composants matériels tels que des cartes réseaux, des cartes sons et tout les autres matériels virtuelles. Ils n’ont pas connaissances des vrais matériels. Toutes ces machines virtuelles fonctionnent sous les ordres d’un hyperviseur (HYPERVISOR) qui est gérer par un système d’exploitation de base, celui de l’hôte (HOST OPERATING SYSTEM).
À droite, le conteneur correspond à un des carrés pointillés. On y trouve une ou plusieurs applications (APP) avec leur fichiers nécessaires au fonctionnement de l’application (SUPPORTING FILES RUNTIME) isolé du reste du système (pointillés) et partageant le même système d’exploitation (HOST OPERATING SYSTEM). L’application, si elle doit accéder au matériel, le fait directement sur le vrai matériel. Pas de virtualisation dans ce cas.
On peut se demander pourquoi isolé un processus ? Il y a deux aspects qui entre en compte dans l’isolation.
En isolant le processus, on évite de compromettre toute l’application. Imaginez votre navigateur ayant 3 onglets ouverts sur différents site web. Si un onglet plante, on ne veut pas que toute l’application plante. On souhaite simplement pouvoir fermer l’onglet défectueux. C’est le même principe avec un hébergement web. Si vous hébergez 150 sites web et qu’un site web plante, vous ne voulez pas que les 149 autres sites web soient inaccessible.
Dans ces exemples, on va faire de l’isolation de ressources par exemple en allouant 10% du temps processeur d’un seul cœur à un processus. Si ce dernier plante, il ne plante que 10% d’un cœur. Le reste du matériel est toujours disponible pour les autres processus.
De même, imaginons le programme suivant dans lequel le programmeur a
oublié d’incrémenter la variable i. Ce faisant, il a créer
une boucle sans fin qui va instancier des objets. Si le programme n’a
pas de limite, il ira jusqu’à utiliser toute la mémoire RAM au détriment
des autres processus qui finiront par planter.
public static void Main(string[] args)
{
int i = 0;
List<MonObjet> lst = new List<MonObjet>();
while(i < 10)
{
lst.Add(new MonObjet());
}
}En utilisant les cgroups on peut écrire
la valeur 2097152 dans le fichier
memory.limit_in_bytes du processus
appConteneur.
echo $(( 2048 * 1024 )) | sudo tee /sys/fs/cgroup/memory/appConteneur/memory.limit_in_bytes #2 MB RAMet ainsi limiter la taille maximal de mémoire disponible pour le
processus appConteneur à 2MB. Si le processus tente
d’obtenir plus de mémoire, le système d’exploitation refusera et seul le
processus appConteneur en subira les conséquences.
Un autre aspect de l’isolation concerne la sécurité. En effet, si plusieurs processus partagent les mêmes ressources, et qu’un processus contient une faille de sécurité, en passant par le processus vulnérable, il sera possible d’obtenir des informations sensibles des autres processus.
Imaginons deux programmes utilisant les mêmes points de montage (les mêmes partitions de disques). L’application vulnérable n’est pas intéressante, c’est un simple jeu de morpion en ligne. Par contre, l’autre application est une site de vente en ligne contenant une base de données de clients avec leur numéros de carte de crédit. En passant par le jeu de morpion, l’attaquant aura accès aux données du site de vente en ligne puisque les deux applications partagent les mêmes points de montage et donc les mêmes emplacements de stockage.
Cette fois, en utilisant les namespace, on pourra isolé les ressources matériels des deux applications. Chaque application ne verra que ses points de montage. Si une application est vulnérable, elle n’exposera à l’attaquant que ses données personnelles.
Pour cette démonstration nous allons utiliser une machine Linux avec la distribution Ubuntu installée. Nous utiliserons également une autre distribution nommée Alpine.
Notes
Il faut bien faire la distinction entre Système d’exploitation ou OS ou encore Kernel et Distribution.
Le système d’exploitation se nomme Linux. Son travail est de rendre possible l’utilisation du matériel physique présent dans la machine. Il se matérialise par deux fichiers qui se trouvent dans le répertoire
/bootet qui se nommentvmlinuz-5.X.Y-ZZ-genericetinitrd.img-5.X.Y-ZZ-generic.La distribution, c’est l’ensemble des autres fichiers et répertoires présent dans une installation. Son but est de fournir les binaires nécessaires à l’utilisation du matériel.
Ainsi, on peut dire que Linux rend utilisable une carte réseau et que le binaire
ipfournit par la distribution dans le répertoire/usr/bin/en permet la configuration.
Nous sommes actuellement dans le répertoire personnel de
l’utilisateur ubuntu. Il s’agit du répertoire
/home/ubuntu. Dans ce répertoire on trouve un dossier nommé
alpine. Ce dossier contient toute la distribution Alpine.
ubuntu@m347:~$ ls alpine/
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr varOn peut déjà remarquer plusieurs choses:
Il n’y a pas de fichier correspondant au système d’exploitation. Il n’y a que les fichiers de la distribution.
On trouve des binaires permettant d’exécuter des tâches telles
que le binaire ls qui permet de lister le contenu d’un
dossier
Si on exécute un binaire de la distribution Alpine on obtient le résultat
escompté. Par exemple, en exécutant le binaire ls de la
distribution Alpine on obtient le
même résultat qu’avec celui de mon installation actuelle
ubuntu@m347:~$ ls # celui de ma distribution
alpine snap
ubuntu@m347:~$ alpine/bin/ls # celui d'alpine
alpine snapCe n’est pas étonnant car les deux binaires font appel au même système d’exploitation (il n’y en a qu’un) pour obtenir leur résultat
Les deux binaires sont capables de voir tout le contenu de l’arborescence disque. Seul la présentation des résultats change.
ubuntu@m347:~$ ls / # celui de ma distribution
bin dev home lib32 libx32 media opt root sbin srv sys usr
boot etc lib lib64 lost+found mnt proc run snap swap.img tmp var
ubuntu@m347:~$ alpine/bin/ls / # celui d'alpine
bin etc lib32 lost+found opt run srv tmp
boot home lib64 media proc sbin swap.img usr
dev lib libx32 mnt root snap sys varSi on fait le même travail sur les interfaces réseaux on obtient les mêmes résultats
ubuntu@m347:~$ ip link # celui de ma distribution
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:67:96:58 brd ff:ff:ff:ff:ff:ff
ubuntu@m347:~$ alpine/sbin/ip link # celui d'alpine
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel qlen 1000
link/ether 08:00:27:67:96:58 brd ff:ff:ff:ff:ff:ffIsolons maintenant le répertoire alpine et faisons en
sorte que la racine du disque / dans notre système isolé
devienne /home/ubuntu/alpine. Pour faire ce travail, nous
devrons dialoguer avec Linux grâce à l’outil unshare.
Cet outil va nous permettre de demander à Linux de changer d’espace
de nom et ainsi isolé notre dossier. On peut travailler sur plusieurs espaces de nom
en fonction de ce que l’on souhaite faire. Vous trouverez de plus amples
informations au sujet des espaces de nom sur internet et notamment sur
ce site linuxembedded.fr.
Sans entrer trop dans le détail, nous allons demander au noyau de nous isoler de tout:
--uts. Ceci nous permettra de définir un
nouveau nom d’hôte.--pid. Ceci nous permettra de
redéfinir les numéros de processus en partant du numéro 1. On ne pourra
donc plus connaître les numéros des processus actuels existant. On
repartira avec une liste vierge.--mount. Ceci nous masquera
l’existence des points de montage et en redéfinira de nouveaux.--net. Ceci nous masquera les
interfaces réseaux actuelles.--ipc. Ceci nous
empêchera de voir les échanges inter-processus autres que les
nôtres.Une fois que nous serons isolé, nous changerons la racine actuelle
/ par notre répertoire
/home/ubuntu/alpine.
Ça donne ceci :
ubuntu@m347:~$ cd alpine/
ubuntu@m347:~/alpine$ sudo unshare --mount --uts --ipc --net --pid --fork --mount-proc --root /home/ubuntu/alpine sh
/# ls
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr varComme on peut le voir, la racine actuelle est maintenant celle du
répertoire alpine. Il est impossible d’aller voir
au-dessus. En réalité, un utilisateur que l’on placerait maintenant dans
ce shell n’aurait même pas conscience de l’existence de la distribution
Ubuntu de base. Il en est de même pour le programmes que
nous pouvons lancer. Si on reprend les programmes précédent
ls et ip, nous pouvons faire un premier
constat qui est que les seuls version de programme utilisable sont ceux
de la distribution Alpine puisque
nous n’avons plus accès aux autres.
/# ls /home/ubuntu/
ls: /home/ubuntu: No such file or directorySi on regarde la version actuelle de notre distribution on obtient
/# cat /etc/os-release
NAME="Alpine Linux"
ID=alpine
VERSION_ID=3.21.3
PRETTY_NAME="Alpine Linux v3.21"
HOME_URL="https://alpinelinux.org/"
BUG_REPORT_URL="https://bugs.alpinelinux.org/"Alors qu’en dehors de notre isolation on obtient
ubuntu@m347:~$ cat /etc/os-release
PRETTY_NAME="Ubuntu 22.04.2 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.2 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammyPour ce qui est des interfaces réseaux, dans notre système isolé on
obtient uniquement l’interface de loopback qui est
nécessaire au fonctionnement d’une grande majorité de programme mais on
peut constater que ce n’est pas la même qu’en dehors puisque
actuellement cette interface est DOWN
/# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
## On la met en `UP`
/# ip link set lo up
/# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00Alors qu’en dehors nous avions une interface de loopback
up et une interface réseau externe.
ubuntu@m347:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enx908d6e23017f: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 90:8d:6e:23:01:7f brd ff:ff:ff:ff:ff:ffOn peut faire les mêmes remarques concernant les processus. Dans la
partie isolée on ne voit que deux processus, un bash dans
lequel on est entrain d’écrire nos commandes et le processus
ps qui liste les processus
/# ps
PID USER TIME COMMAND
1 root 0:00 -bash
8 root 0:00 psAlors qu’en dehors il y a beaucoup d’autres processus…
ubuntu@m347:~$ ps fa
PID TTY STAT TIME COMMAND
1 ? Ss 0:01 /sbin/init maybe-ubiquity
2 ? S 0:00 [kthreadd]
3 ? I< 0:00 \_ [rcu_gp]
4 ? I< 0:00 \_ [rcu_par_gp]
...
1649 pts/0 S 0:00 | \_ sudo unshare --mount --uts --ipc --net --pid --fork --mount-proc --root /home/debian/alpine sh
1650 pts/0 S 0:00 | \_ unshare --mount --uts --ipc --net --pid --fork --mount-proc --root /home/debian/alpine sh
1651 pts/0 S+ 0:00 | \_ shIl est intéressant de constater dans ces deux dernières commandes que
le sh est le même mais une fois vu de la partie isolée
(dans le conteneur) et donc avec comme PID le numéro
1 et une fois vu du système complet (en dehors du
conteneur). Dans le système complet on voit que ce sh est
un enfant de unshare. Dans le système complet ce
sh n’est rien d’autre qu’un processus isolé.
unshareOn peut constater que le principe de base de la conteneurisation c’est l’isolation de processus. On peut aussi constater que cette isolation est assez simple à mettre en place. Il suffit de demander au noyau Linux de créer un nouveau namespace et de créer un nouveau cgroup pour isoler les ressources. Une fois l’isolation mise en place, depuis le conteneur, on ne peut plus voir ce qui existe en dehors de celui-ci.
Toute la démonstration ci-dessus est assez compliquée et le système isolé n’est de loin pas parfais. Si on veut créer des conteneurs, on ne va pas procéder ainsi à moins d’être un spécialiste, et encore…
Pour faire ce travail de conteneurisation, on utilisera des logiciels qui sont spécialisés dans ce travail. Il en existe beaucoup, chacun avec ses avantages et ses inconvénients. Il faut cependant garder à l’esprit que tout ces logiciels font le même travail que la démonstration ci-dessus, c’est-à-dire qu’ils demandent au noyau Linux l’isolation d’un ou plusieurs processus.
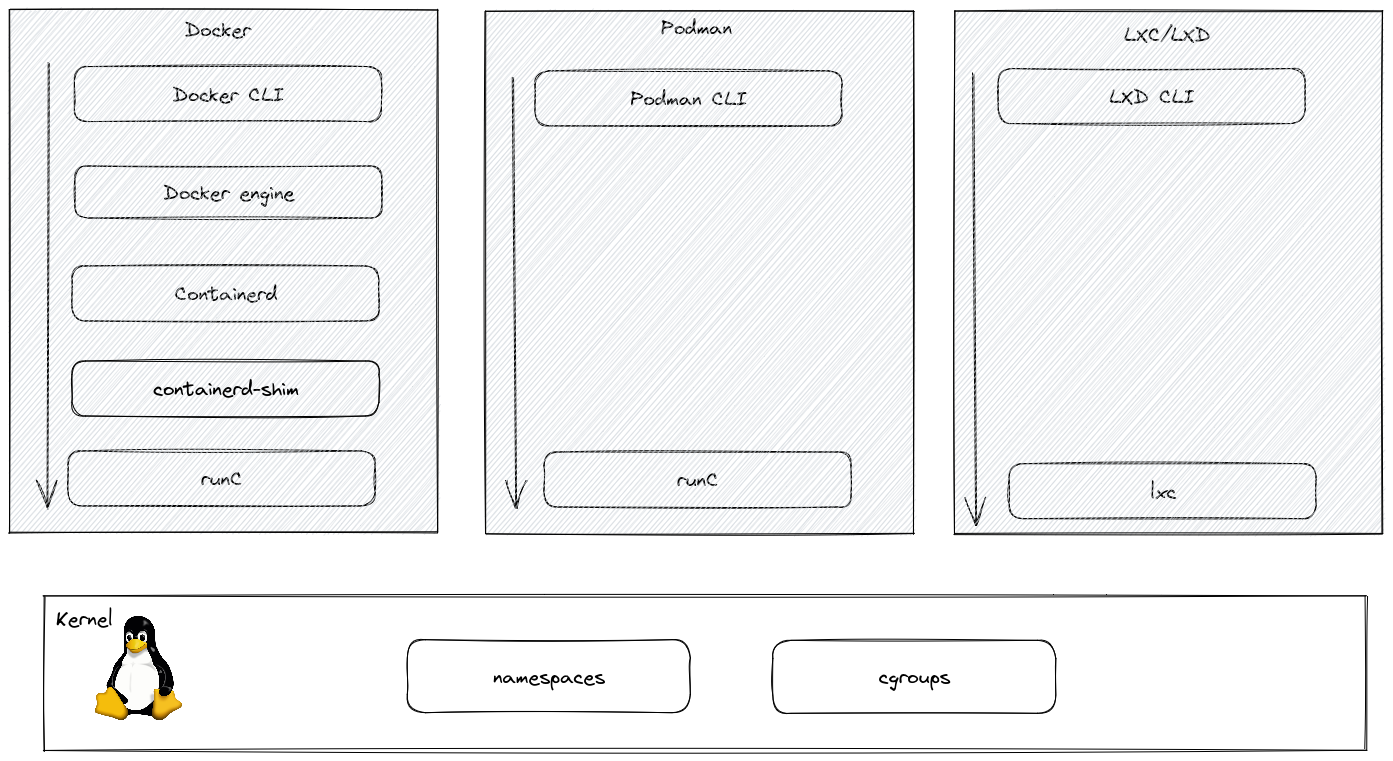
Parmi les logiciels de conteneurisation on trouve des librairies de bas niveau qui s’occupe du dialogue avec le noyau. Leur travail consiste entre autre à gérer les espaces de nom namespace et les groupes de contrôle cgroups.
Au dessus de ces librairies, on trouve les logiciels intermédiaires qui vont se charger de plusieurs tâches comme la gestion des /images, la création de ces dernières, la gestion des configurations des conteneurs, la gestion de l’état du conteneur, la sauvegarde etc.
Et encore au-dessus, on trouve des outils de gestion de ces conteneurs. Ces outils vont se charger du dialogue entre l’utilisateur et les librairies situées en-dessous.
Notes
Il existe d’autres logiciels de conteneurisation qui se situe à mi-chemin entre des vrais conteneurs et des machines virtuelles. Parmi ceux-ci on trouve:
- Filecracker qui est un projet d’Amazon
- Kata containers qui est né de la fusion des projets Clear Containers d’Intel et de RunV d’Hyper.sh
- Nabla containers qui est une initiative d’IBM
- Les conteneurs en général sur Windows…
Toutes ces technologies utilisent des micro-machines virtuelles pour permettre un isolation plus forte entre les conteneurs et le système d’exploitation. Elles nécessitent des /images de base spécifique et subissent des pertes de performances inhérentes aux machines virtuelles même si celles-ci sont optimisées au maximum et très légères.
Pour répondre à cette question nous allons prendre quelques cas de figure.
Imaginons deux développeurs PHP qui sont embarqués dans le même projet. Le premier possède une machine Apple et le second travail sur un poste Ubuntu. Le serveur de déploiement fonctionne sur une machine Linux. Il est fournit avec un serveur web apache en version 2.4.41 et une base de données mariadb 10.10. Il fonctionne avec PHP 7.4.26.
Apple
Le développeur Apple choisi de mettre en place l’environnement de travail en utilisant MAMP. MAMP est fourni avec les versions suivantes:
Ubuntu
Le développeur Ubuntu 22.04 installera les paquets officiels de la distribution, à savoir:
| Apple | Ubuntu | Serveur final |
|---|---|---|
| PHP 8.1.13 | PHP 8.1.2 | PHP 7.4.26 |
| mySQL 5.7.39 | mySQL 8.0.28 | MariaDB 10.10 |
| Apache 2.5.54 | Apache 2.5.52 | Nginx 1.27.4 |
En résumé, on peut dire qu’on se trouve avec un beau mélange de versions de logiciels et de systèmes d’exploitations qui ont chacun leur particularités. Il y aura donc inévitablement des problèmes qui surviendront et qui seront indépendant de notre développement.
Saviez-vous qu’un retour à la ligne sur :
- Linux correspond au caractère
\n- Mac correspond au caractère
\r- Windows correspond au caractère
\r\nOu encore qu’un
ésur
- Mac se code avec deux valeurs selon le standard NFD, U+0065 (e) + U+0301 (◌́), c’est-à-dire le caractère
eauquel on ajoute le aiguë◌́- Linux et Windows se code avec une seule valeur selon le standard NFC, U+00e9, c’est-à-dire le caractère
éEt encore que la racine d’un système de fichier sur :
- Linux et Mac se trouve dans
/- Windows se trouve dans
C:\Mais aussi que les chemins d’accès aux fichiers sur :
- Linux et Mac se séparent avec
/- Windows se séparent avec
\
Avec de la conteneurisation
L’idée de la conteneurisation dans ce cas, c’est de pouvoir mettre plusieurs services à disposition. Ces services seront isolés du système d’exploitation et de ses autres services. Il sera donc possible de mettre en place un environnement de développement similaire à l’environnement de production.
Ainsi, chaque développeur qui participe au projet installera localement le même conteneur qui est l’équivalent du serveur final. Ils développeront tous sur les mêmes versions.
On peut également imaginer qu’un développeur souhaite mettre à disposition son logiciel. Ce dernier à besoin de certaines librairies pour fonctionner. L’utilisateur qui souhaite utiliser ce logiciel ne souhaite pas installer toutes les librairies nécessaires. En effet, il n’a pas confiance en une des librairie et il ne veut pas l’installer dans son système. Comme il souhaite quand même utiliser le logiciel, il va installer le conteneur qui contient le logiciel et toutes les librairies nécessaires. La librairie qui ne lui inspire pas confiance ne sera pas installée dans son système. Elle sera isolée dans le conteneur.
Prenons l’exemple du logiciel funbox. Ce logiciel permet d’effectuer plusieurs animations dans son terminal. Pour pouvoir réaliser toutes ces animations, il a besoin d’une liste conséquente de logiciels annexes.
Pas sûr que l’utilisateur soit d’accord d’installer tous ces logiciels sur son système. Il préfère installer le conteneur qui contient le logiciel et toutes les librairies nécessaires.
 Des conteneurs dans mon navigateur
Des conteneurs dans mon navigateurCette information date un peu mais on comprend bien l’utilité des conteneurs pour des géants comme Google.
2 milliards de containers générés chaque semaine. (la page n’est plus disponible)
💬 Peut-on faire une différence entre une machine virtuelle et un conteneur ?
💬 Quelle est la différence entre le système d’exploitation Linux et une distribution Linux (par exemple Alpine) ?
💬 Est-il possible de faire fonctionner un conteneur avec un système d’exploitation différent de celui de la machine hôte ?
💬 Qu’est-ce qu’un conteneur ?
💬 Comment peut-on allouer 10% d’un cœur de processeur à un conteneur ?
💬 Il est écrit qu’on peut limiter la taille mémoire allouée à un
conteneur à l’aide des cgroups en utilisant, par exemple,
la directive memory.limit_in_bytes. Où trouve-t-on la
documentation officielle de cette directive ?
💬 Qu’est-ce qu’un espace de nom ?
mount), les
identifiants de processus etc.
💬 Qu’est-ce qu’un groupe de contrôle ?
💬 Quelle différence peut-on faire en le programme runc
et le programme docker ?
docker est le programme de haut niveau qui
simplifie l’utilisation de runc. runc est le
programme qui dialogue avec le SE pour isolé des processus
💬 Qu’est-ce qu’un daemon comme par exemple containerd
?
L’objectif de la pratique c’est d’être capable de mettre en place un conteneur avec un programme qui tourne dedans et ce, indépendamment de la technologie utilisée, docker, podman, LXD ou Incus.
Nous débuterons la mise en pratique des conteneurs avec le logiciel qui est le plus connu et qui se nomme docker.
Présentation du concepteur de Docker
Présentation de dockerNotes
Le logiciel de conteneurisation d’environnement qui se nomme Incus est développé par un ancien élève du CPLN qui est passé par la même formation que vous. Il se nomme Stéphane Graber. Il est le leader du projet Incus anciennement
LXD. LXD c’est, par exemple, ce qui tourne sur les Chromebook par défaut pour faire fonctionner Linux et les Chromebook c’est quelques centaines de milliers d’étudiants aux états-uni.Incus se veut être un système de virtualisation d’environnement. Attention ici au mot virtualisation car il s’agit bien de conteneur.
Docker était à la base un logiciel monolithique c’est-à-dire, un gros logiciel qui faisait tout. Avec le temps et pour des raisons de compatibilité avec d’autres logiciels, docker s’est décomposé en plusieurs morceaux comme on peut le voir sur l’image ci-dessous:
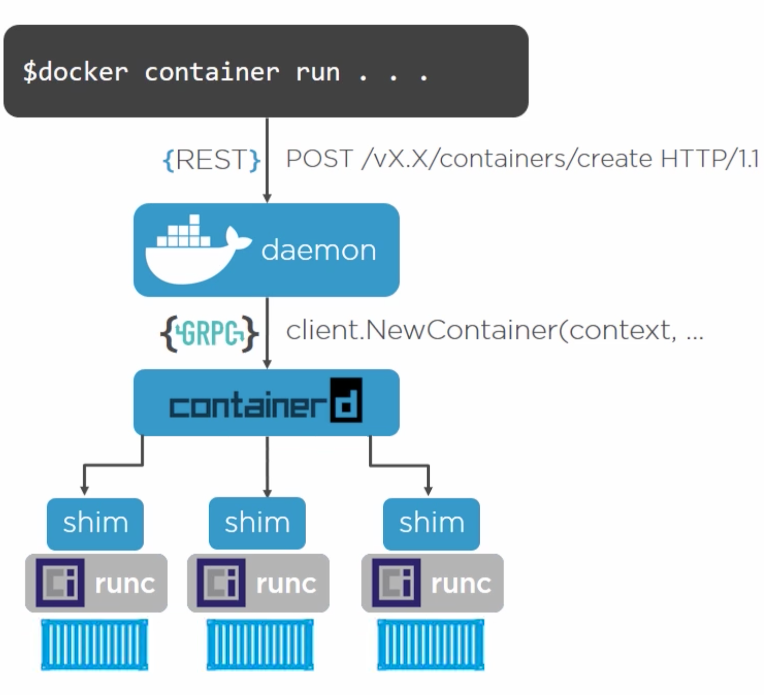
Vous travaillerez avec la couche de plus haut niveau qui est le
docker CLI. La CLI fera des requêtes au
daemon qui lui-même fera des requêtes à
containerd. containerd à son tour passera par
shim pour finalement accéder à runc. C’est
runc qui est réellement en charge de créer les
conteneurs.
Tout cela sera complètement transparent pour vous. Vous
n’aurez pas à vous soucier de tout cela. Vous utiliserez uniquement la
CLI de docker. Par contre, vous verrez par la
suite que cette couche logiciel à posé (et pose toujours) des problèmes
de sécurité.
Le travail dans la CLI suppose la manipulation aisée de l’interface de commande. Il est donc important de connaître les commandes de base de la CLI telles que la manipulation de fichier, la navigation dans les répertoires, la gestion des droits etc.
Pour vous aidez dans cette tâche, j’ai mis ci-dessous un résumé des commandes de base utilisée dans un terminal. Vous pouvez également vous référer à la documentation officielle de Ubuntu ou de Debian.
| Touche/Commande | Description |
|---|---|
cd [répertoire] |
Change de répertoire ex: cd Documents |
cd |
Répertoire personnel de l’utilisateur (home) |
cd ~ |
Répertoire personnel de l’utilisateur (home) |
cd / |
Racine du disque dur |
cd - |
Répertoire précédent |
ls |
Liste non détaillée des fichiers et dossiers du répertoire en cours |
ls -l |
Liste détaillée des fichiers et dossiers du répertoire en cours |
ls -a |
Liste incluant les fichiers cachés |
ls -lh |
Liste détaillée avec l’unité pour la taille des fichiers |
ls -R |
Liste le contenu de la totalité du répertoire en cours incluant les sous-dossiers et de manière récursive |
sudo [commande] |
Lance la commande avec les privilèges de sécurité du superuser (Super User DO) |
top |
Affiche les processus actifs. Touche q pour quitter |
nano [fichier] |
Ouvre le fichier avec l’éditeur de texte nano |
clear |
Efface tout l’écran |
reset |
Réinitialise le terminal |
| Touche/Commande | Description |
|---|---|
[commande-a]; [commande-b] |
Lance la commande A puis la commande B peu importe le succès ou non de la commande A |
[commande-a] && [commande-b] |
Lance la commande B si la commande A a réussi |
[commande-a] || [commande-b] |
Lance la commande B si la commande A a échoué |
[commande-a] & |
Lance la commande A en arrière plan |
| Touche/Commande | Description |
|---|---|
[commande-a] | [commande-b] |
Lance la commande A qui envoie son résultat à la commande B. Par
exemple : ls | grep C affiche la liste des fichiers et
dossiers qui contiennent la lettre C |
| Touche/Commande | Description |
|---|---|
history N |
Affiche l’historique des N commandes tapées précédemment |
| Ctrl + R | Recherche interactivement dans l’historique des commandes |
![valeur] |
Exécute la dernière commande tapée qui commence par ‘valeur’ |
![valeur]:p |
Affiche à l’écran la dernière commande tapée qui commence par ‘valeur’ |
!! |
Exécute la dernière commande tapée |
!!:p |
Affiche à l’écran la dernière commande tapée |
| Touche/Commande | Description |
|---|---|
touch [fichier] |
Crée un nouveau fichier |
pwd |
Affiche le chemin complet du répertoire en cours |
. |
Répertoire en cours, par exemple ls . |
.. |
Répertoire parent c’est à dire qui contient le répertoire en cours,
par exemple ls .. |
ls -l .. |
Liste détaillée du répertoire parent |
cd ../../ |
Monte de 2 niveaux |
cat |
Concatène à l’écran |
rm [fichier] |
Supprime un fichier, par exemple rm data.tmp |
rm -i [fichier] |
Supprime un fichier avec demande de confirmation |
rm -r [rép] |
Supprime le répertoire et son contenu |
rm -f [fichier] |
Force la suppression du fichier sans demande de confirmation |
cp [fichier] [nouveauFichier] |
Copie fichier vers nouveauFichier |
cp [fichier] [répertoire] |
Copie fichier dans répertoire |
mv [fichier] [nouveauFichier] |
Déplace/Renomme fichier vers nouveauFichier par exemple
mv fichier1.ad /tmp |
| Touche/Commande | Description |
|---|---|
mkdir [rép] |
Crée un nouveau répertoire |
mkdir -p [rép]/[rép] |
Crée un répertoire et un sous-répertoire dans la foulée |
rmdir [rép] |
Supprime le répertoire (uniquement si le répertoire est vide) |
rm -R [rép] |
Supprime le répertoire et son contenu |
less [fichier] |
Affiche le contenu du fichier par morceau |
[commande] > [fichier] |
Envoie le résultat de la commande vers le fichier. Attention le contenu du fichier est écrasé |
[commande] >> [fichier] |
Ajoute le résultat de la commande au contenu existant du fichier |
[commande] < [fichier] |
Indique à la commande de lire le contenu du fichier |
| Touche/Commande | Description |
|---|---|
find [rép] -name [expression] |
Recherche les fichiers dont le nom est conforme à l’expression dans
le répertoire spécifié, par exemple
find /Utilisateurs -name "fichier.txt" |
grep [expression] [fichier] |
Recherche toutes les lignes contenant l’expression, par exemple
grep "Tom" fichier.txt |
grep -r [expression] [rép] |
Recherche récursivement dans tous les fichiers du répertoire spécifié toutes les lignes qui contiennent l’expression |
grep -v [expression] [fichier] |
Recherche toutes les lignes qui ne contiennent PAS l’expression |
grep -i [expression] [fichier] |
Recherche toutes les lignes qui contiennent l’expression sans tenir compte de la casse (majuscules/minuscules) |
| Touche/Commande | Description |
|---|---|
[commande] -h |
Affiche l’aide pour la commande |
[commande] --help |
Affiche l’aide pour la commande |
info [commande] |
Affiche l’aide pour la commande |
man [commande] |
Affiche le manuel d’utilisation de la commande |
whatis [commande] |
Décris ce que fait la commande en 1 seule ligne |
apropos [expression] |
Recherche les commandes dont la description contient l’expression |
L’installation de docker peut se faire de différente manière en fonction de l’environnement dans lequel vous vous trouvez. Dans ce cours, nous utiliserons une machine virtuelle Ubuntu LTS. L’installation se fera alors ainsi.
ssh -o PubkeyAuthentication=no -o
PreferredAuthentications=password ubuntu@A.B.C.D
ubuntu@m347:~$ sudo apt update
[sudo] password for ubuntu:
ubuntu@m347:~$ sudo apt upgrade
ubuntu@m347:~$ sudo apt autoremove
ubuntu@m347:~$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
ubuntu@m347:~$ echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
ubuntu@m347:~$ sudo apt update
ubuntu@m347:~$ sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
containerd.io docker-buildx-plugin docker-ce docker-ce-cli docker-ce-rootless-extras docker-compose-plugin docker-scan-plugin
libltdl7 libslirp0 pigz slirp4netns
...Parmis les paquets installés, on retrouve des logiciels qu’on a déjà
vu précédemment tel que docker-ce-cli qui est la
CLI de docker ainsi que containerd.io qui est
un logiciel qui permet de gérer les conteneurs.
Une fois cette étape réalisée nous aurons à disposition un ensemble
de commandes accessibles via la commande de base docker
ubuntu@m347:~$ docker
Usage: docker [OPTIONS] COMMAND
A self-sufficient runtime for containers
Options:
--config string Location of client config files (default "/home/ubuntu/snap/docker/2746/.docker")
-c, --context string Name of the context to use to connect to the daemon (overrides DOCKER_HOST env var and default context set with "docker context use")
-D, --debug Enable debug mode
-H, --host list Daemon socket(s) to connect to
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
--tls Use TLS; implied by --tlsverify
--tlscacert string Trust certs signed only by this CA (default "/home/ubuntu/snap/docker/2746/.docker/ca.pem")
--tlscert string Path to TLS certificate file (default "/home/ubuntu/snap/docker/2746/.docker/cert.pem")
--tlskey string Path to TLS key file (default "/home/ubuntu/snap/docker/2746/.docker/key.pem")
--tlsverify Use TLS and verify the remote
-v, --version Print version information and quit
Management Commands:
builder Manage builds
buildx* Docker Buildx (Docker Inc., v0.8.2)
compose* Docker Compose (Docker Inc., v2.5.0)
config Manage Docker configs
container Manage containers
context Manage contexts
image Manage /images
manifest Manage Docker image manifests and manifest lists
network Manage networks
node Manage Swarm nodes
plugin Manage plugins
secret Manage Docker secrets
service Manage services
stack Manage Docker stacks
swarm Manage Swarm
system Manage Docker
trust Manage trust on Docker /images
volume Manage volumes
Commands:
attach Attach local standard input, output, and error streams to a running container
build Build an image from a Dockerfile
commit Create a new image from a container's changes
cp Copy files/folders between a container and the local filesystem
create Create a new container
diff Inspect changes to files or directories on a container's filesystem
events Get real time events from the server
exec Run a command in a running container
export Export a container''s filesystem as a tar archive
history Show the history of an image
/images List /images
import Import the contents from a tarball to create a filesystem image
info Display system-wide information
inspect Return low-level information on Docker objects
kill Kill one or more running containers
load Load an image from a tar archive or STDIN
login Log in to a Docker registry
logout Log out from a Docker registry
logs Fetch the logs of a container
pause Pause all processes within one or more containers
port List port mappings or a specific mapping for the container
ps List containers
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rename Rename a container
restart Restart one or more containers
rm Remove one or more containers
rmi Remove one or more /images
run Run a command in a new container
save Save one or more /images to a tar archive (streamed to STDOUT by default)
search Search the Docker Hub for /images
start Start one or more stopped containers
stats Display a live stream of container(s) resource usage statistics
stop Stop one or more running containers
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
top Display the running processes of a container
unpause Unpause all processes within one or more containers
update Update configuration of one or more containers
version Show the Docker version information
wait Block until one or more containers stop, then print their exit codes
Run 'docker COMMAND --help' for more information on a command.
To get more help with docker, check out our guides at https://docs.docker.com/go/guides/docker info la
configurationOn peut connaître la configuration de docker avec la commande
docker info. Cette commande nous donne des informations sur
la version de docker, le nombre de conteneurs, d’images, de volumes, de
système de fichier etc.
ubuntu@m347:~$ docker info
Client:
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc.)
Version: v0.10.2
Path: /usr/libexec/docker/cli-plugins/docker-buildx
compose: Docker Compose (Docker Inc.)
Version: v2.16.0
Path: /usr/libexec/docker/cli-plugins/docker-compose
scan: Docker Scan (Docker Inc.)
Version: v0.23.0
Path: /usr/libexec/docker/cli-plugins/docker-scan
Server:
Containers: 3
Running: 0
Paused: 0
Stopped: 3
/images: 1
Server Version: 23.0.1
Storage Driver: vfs
Logging Driver: json-file
Cgroup Driver: systemd
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 2456e983eb9e37e47538f59ea18f2043c9a73640
runc version: v1.1.4-0-g5fd4c4d
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: builtin
cgroupns
Kernel Version: 5.19.0-35-generic
Operating System: Ubuntu 22.04.2 LTS
OSType: linux
Architecture: x86_64
CPUs: 16
Total Memory: 27.1GiB
Name: m347
ID: 6703d90e-dcfe-4d89-b583-9ff341b4d919
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: falsedocker run
hello-worldC’est une tradition des cours informatiques, nous allons commencer
par un Hello
World. La commande pour démarrer un conteneur docker est
docker run <nom de l'image>. L’image que nous allons
utiliser se nomme hello-world.
Elle est fournie par docker en tant qu’image de test.
ubuntu@m347:~$ docker run hello-world
docker: Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/create": dial unix /var/run/docker.sock: connect: permission denied.
See 'docker run --help'.…et on tombe sur un problème 😟. Nous n’avons pas les droits
suffisants pour utiliser le socket docker. On peut le confirmer en
lançant la même commande mais en tant que root.
ubuntu@m347:~$ sudo docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share /images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/docker
sont des conteneurs qui fonctionne avec les droits root et
que c’est un fonctionnement qui est dangereux 😱!
Dans la documentation officielle de docker, il nous
propose de nous passer de la commande sudo en ajoutant
notre compte dans le groupe docker ainsi :
Running Docker as normal user
By default, Docker is only accessible with root privileges (
sudo). If you want to use docker as a regular user, you need to add your user to thedockergroup.
sudo usermod -a -G docker $USER
## logout and login again Warning: if you add your user to the
dockergroup, it will have similar power as therootuser. For details on how this impacts security in your system, see Surface attack
Maitenant que notre utilisateur est dans le groupe
docker, on peut lancer la commande sans
sudo ainsi docker run hello-world.
root pour le meilleur mais aussi pour le
pire 😈
Installation et commandes de baseVous connaissez certainement James Bond et Mister Q. Mister Q est le technicien qui fournit les gadgets à James Bond. Il est également un hacker hors paire capable de tout. Lorsqu’on le voit apparaître dans le film, il y a toujours un ou plusieurs écrans qui affiche des lignes de code.

C’est les écrans des hackers hollywoodiens. On va faire pareil.
Dustin Kirkland a crée une image docker qui transforme votre terminal en écran de hacker hollywoodien.
L’image ainsi que les instructions pour l’utilisé se trouve ici.
Démarrez une des animations fournies pas la funbox
hello-worldL’objectif de cette manipulation est une approche top ↦ down d’un conteneur. Pour comprendre un conteneur, nous allons utiliser le conteneur de base Hello World de docker et le décortiquer pour le comprendre.
Pré-requis
sudo timedatectl set-timezone Europe/Zurichsudo nano /etc/systemd/timesyncd.confNote
Docker n’est pas forcement configuré pour permettre des limitations dans les conteneurs. Par exemple, si on souhaite limiter la taille de la mémoire pour un conteneur. Pour connaître cette information il faut lancer la commande suivante
$ docker info | grep swap WARNING: No swap limit supportSi la réponse est identique à celle ci-dessus, il faut modifier la configuration de la machine virtuelle en éditant le fichier
/etc/default/grubet en modifiant la ligne suivante ainsiGRUB_CMDLINE_LINUX_DEFAULT="maybe-ubiquity cgroup_enable=memory swapaccount=1"Une fois le fichier modifier il faut lancer la commande de mise-à-jour de
grubet redémarrer la machine virtuelle$ sudo update-grub $ sudo reboot
docker imagePour obtenir l’image du conteneur, on utilise la commande
docker image
ubuntu@m347:~$ docker image
Usage: docker image COMMAND
Manage /images
Commands:
build Build an image from a Dockerfile
history Show the history of an image
import Import the contents from a tarball to create a filesystem image
inspect Display detailed information on one or more /images
load Load an image from a tar archive or STDIN
ls List /images
prune Remove unused /images
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rm Remove one or more /images
save Save one or more /images to a tar archive (streamed to STDOUT by default)
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
Run 'docker image COMMAND --help' for more information on a command.Comme on peut le voir, la commande permet de gérer les /images
locales. On peut donc télécharger l’image du conteneur
hello world à l’aide de la sous-commande pull.
On peut également ajouter un tag pour savoir quelle image
on souhaite parmi toutes celles disponible

Nous choisirons celle par défaut qui correspond à la dernière
latest
ubuntu@m347:~$ docker image pull hello-world:latest
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:6d60b42fdd5a0aa8a718b5f2eab139868bb4fa9a03c9fe1a59ed4946317c4318
Status: Downloaded newer image for hello-world:latest
docker.io/library/hello-world:latestOn peut vérifier qu’elle est bien présente dans notre réserve d’images locales
ubuntu@m347:~$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest feb5d9fea6a5 5 months ago 13.3kBOn peut maintenant démarrer le conteneur via la sous-commande
run. Cette commande instancie un conteneur en partant d’une
image. On peut faire un parallèle avec la programmation lorsqu’on
instancie un objet en partant d’une class. Par exemple:
Label monLabel = new Label();La commande run fait le même travail mais pour un
conteneur
ubuntu@m347:~$ docker run hello-world
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share /images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/Que c’est-il passé ? Et bien il suffit de traduire le message pour le comprendre
docker run à contacté le
daemon docker en lui demandant de créer un conteneur basé
sur l’image hello-worlddaemon est allé chercher l’image dans notre réserve.
Si elle n’aurai pas été présente, il serait allé la chercher directement
sur le Hub
Dockerdaemon a ensuite instancié un conteneur. Dans ce
conteneur, il se trouve un binaire qui affiche le message
Hello from Docker. Le daemon a reçu ce message
de la part du conteneurdaemon a fait suivre ce message à la console depuis
laquelle la demande de création de conteneur a été faiteOn a donc assisté au démarrage d’un processus isolé dont le but est
l’affichage du texte Hello from Docker.
docker inspect,
l’anatomie du hello-worldSi on veut mieux comprendre ce conteneur on peut examiner sa
configuration à l’aide de la commande docker inspect
ubuntu@m347:~$ docker inspect hello-world
[
{
"Id": "sha256:feb5d9fea6a5e9606aa995e879d862b825965ba48de054caab5ef356dc6b3412",
"RepoTags": [
"hello-world:latest"
],
...
"ContainerConfig": {
"Cmd": [
"/bin/sh",
"-c",
"#(nop) ",
"CMD [\"/hello\"]"
],
...On peut voir que la configuration informe le daemon
qu’il devra lancer la commande /bin/sh -c /hello. Autrement
dit, il devra lancer l’exécution du binaire qui se nomme
hello et qui se trouve à la racine du conteneur.
Essayons de voir ce binaire. Pour cela, on va demander à la
commande de gestion des images de nous extraire l’image
hello-world dans une archive.
ubuntu@m347:~$ docker image save hello-world > hello-world.tar
ubuntu@m347:~$ ls -l
total 28
-rw-rw-r-- 1 ubuntu ubuntu 24064 mars 22 12:14 hello-world.tarEt si on regarde à l’intérieur de l’archive on trouve 3 fichiers et un dossier. Les noms ci-dessous sont volontairement raccourci pour une question de lisibilité
ubuntu@m347:~$ mkdir hello
ubuntu@m347:~$ tar xf hello-world.tar --directory hello
ubuntu@m347:~$ ls -l hello
total 16
drwxr-xr-x 2 ubuntu ubuntu 4096 sept. 24 01:47 c28b9 ... 912d5c
-rw-r--r-- 1 ubuntu ubuntu 1469 sept. 24 01:47 feb5d ... 6b3412.json
-rw-r--r-- 1 ubuntu ubuntu 207 janv. 1 1970 manifest.json
-rw-r--r-- 1 ubuntu ubuntu 94 janv. 1 1970 repositoriesLe fichier repositories nous indique le nom du
répertoire dans lequel se trouve le nécessaire au fonctionnement du
conteneur
ubuntu@m347:~/hello$ cat repositories | jq .
{
"hello-world": {
"latest": "c28b9c2faac407005d4d657e49f372fb3579a47dd4e4d87d13e29edd1c912d5c"
}
}Le fichier manifest nous donne plus d’informations. On y
trouve l’emplacement et le nom du fichier de configuration, les tags du
dépôt de provenance et le Layers qui est l’endroit où se
trouve notre binaire.
ubuntu@m347:~/hello$ cat manifest.json | jq .
[
{
"Config": "feb5d9fea6a5e9606aa995e879d862b825965ba48de054caab5ef356dc6b3412.json",
"RepoTags": [
"hello-world:latest"
],
"Layers": [
"c28b9c2faac407005d4d657e49f372fb3579a47dd4e4d87d13e29edd1c912d5c/layer.tar"
]
}
]Le fichier de configuration feb5d ... 6b3412.json
correspond à la configuration du conteneur. C’est la même que celle
qu’on obtient avec la commande docker inspect hello-world
un peu plus haut dans ce document.
Si on analyse le contenu du layer qui est également une
archive, on y trouve le fichier binaire hello
ubuntu@m347:~/hello/c28b9 ... 912d5c$ mkdir tar_content
ubuntu@m347:~/hello/c28b9 ... 912d5c$ tar xf layer.tar --directory tar_content/
ubuntu@m347:~/hello/c28b9 ... 912d5c$ ls -l tar_content/
total 16
-rwxrwxr-x 1 ubuntu ubuntu 13256 sept. 24 01:47 helloEt si on exécute ce fichier binaire ?
ubuntu@m347:~/hello/c28b9 ... 912d5c$ ls -l tar_content/hello
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share /images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/L’image docker hello-world contient des
fichiers de configurations ainsi qu’une archive empaquetant le binaire.
Le fichier binaire est un programme ELF 64-bit dont les dépendances ont
étés placées directement dans le fichier binaire
(statically linked). Il est donc complètement autonome et
ne dépend d’aucune librairies externes.
ubuntu@m347:~$ file tar_content/hello
tar_content/hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, strippedQuand on lance la commande docker run hello-world on
démarre le binaire hello de manière isolée. Si le binaire
hello cherchait, par exemple, à accéder au réseau ou à un
fichier sur le disque, il ne pourrait pas le faire car il est isolé.
Exactement de la même manière que notre programme bash dans
le conteneur alpine que nous avons vu dans le cours
précédent.
On peut trouver le code source du programme hello-world
sur le site github
#include <sys/syscall.h>
#include <unistd.h>
#ifndef DOCKER_IMAGE
#define DOCKER_IMAGE "hello-world"
#endif
#ifndef DOCKER_GREETING
#define DOCKER_GREETING "Hello from Docker!"
#endif
#ifndef DOCKER_ARCH
#define DOCKER_ARCH "amd64"
#endif
const char message[] =
"\n"
DOCKER_GREETING "\n"
"This message shows that your installation appears to be working correctly.\n"
"\n"
"To generate this message, Docker took the following steps:\n"
" 1. The Docker client contacted the Docker daemon.\n"
" 2. The Docker daemon pulled the \"" DOCKER_IMAGE "\" image from the Docker Hub.\n"
" (" DOCKER_ARCH ")\n"
" 3. The Docker daemon created a new container from that image which runs the\n"
" executable that produces the output you are currently reading.\n"
" 4. The Docker daemon streamed that output to the Docker client, which sent it\n"
" to your terminal.\n"
"\n"
"To try something more ambitious, you can run an Ubuntu container with:\n"
" $ docker run -it ubuntu bash\n"
"\n"
"Share /images, automate workflows, and more with a free Docker ID:\n"
" https://hub.docker.com/\n"
"\n"
"For more examples and ideas, visit:\n"
" https://docs.docker.com/get-started/\n"
"\n";
int main() {
//write(1, message, sizeof(message) - 1);
syscall(SYS_write, STDOUT_FILENO, message, sizeof(message) - 1);
//_exit(0);
//syscall(SYS_exit, 0);
return 0;
}On peut en générer un programme identique tel qu’ils le font ainsi
ubuntu@m347:~$ musl-gcc -Wl,--gc-sections -static source_code.c -o hello
ubuntu@m347:~$ strip --strip-all --remove-section=.comment hello
ubuntu@m347:~$ file hello
hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, stripped
ubuntu@m347:~$ ls -l
-rwxrwxr-x 1 ubuntu ubuntu 13256 sept. 24 01:47 helloOn vous demande de réaliser l’exercice suivant :
hello-cpne depuis le hub dockerhello-cpne💬 Que fait le conteneur hello-cpne ?
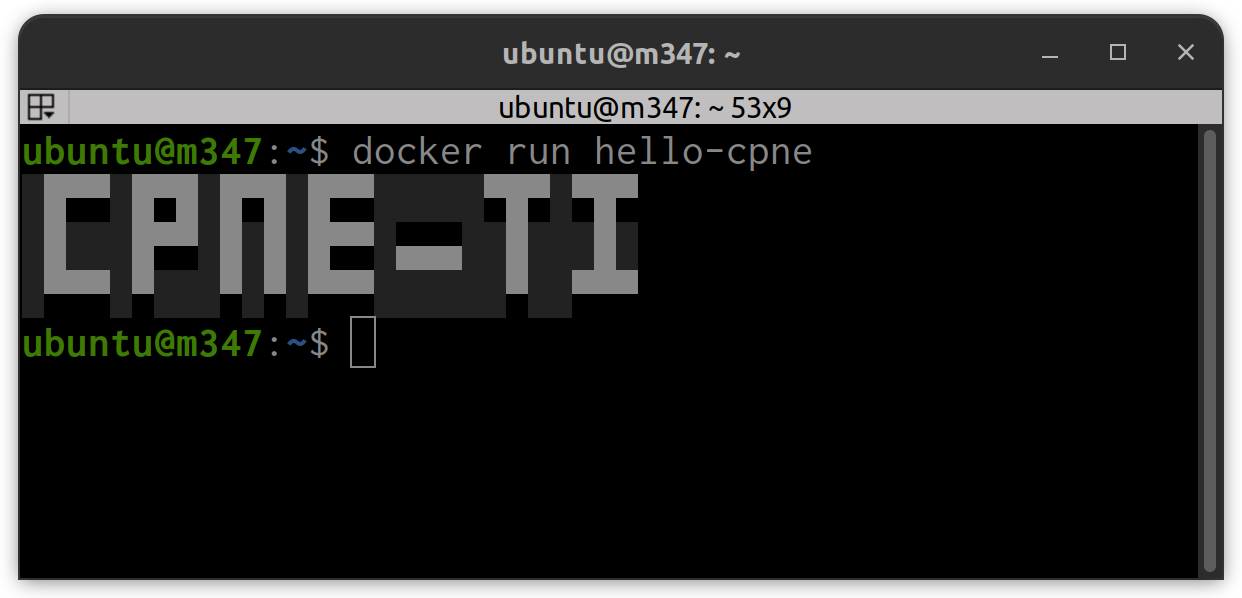
💬 Quelle est la commande qui permet de voir le contenu de
l’image hello-cpne ?
docker inspect hello-cpne
💬 Quelle est le point d’entrée du conteneur hello-cpne
?
"Cmd": [
"/bin/sh",
"-c",
"/bin/sh -c \"figlet -f /root/toilet/fonts/pagga CPNE-TI\""
]
💬 Sur quelle base le conteneur a-t-il été construit ?
cat etc/apk/world alpine-baselayout
ExerciceVous pouvez commencer par visualisé la vidéo de Xavki ci-dessous.
Puis, répondez aux questions suivantes :
💬 Quel différence y a-t-il entre une image et un conteneur ?
💬 Qu’est-ce que c’est qu’un registry ?

💬 Comment se nomme le registry de Microsoft ?
💬 Est-ce une bonne idée que de placer notre utilisateur dans le
groupe docker ?
sudo
devant la commande docker nous le rappel à chaque fois
💬 Dans la vidéo, Xavki utilise la commande suivante
$ sudo usermod -aG docker $USER et parle de variables
d’environnement. C’est quoi une variable d’environnement ?
💬 Dans la vidéo, Xavki utilise la commande suivante
$ sudo usermod -aG docker $USER pour ajouter notre
utilisateur au groupe docker. Où sont défini les groupes
existants, comment puis-je les trouver ?
$ cat
/etc/group
💬 Pourquoi Xavki doit quitter et revenir dans sa machine virtuelle
après avoir ajouté son utilisateur au groupe docker ?
$ groups ubuntu adm dialout cdrom floppy audio dip video plugdev users netdev
$ groups ubuntu adm dialout cdrom floppy audio dip video plugdev users netdev docker
💬 Quelle est l’adresse exacte permettant de rapatrier l’image docker
pour le .NET Runtime version 7.0 du registry
de Microsoft ?
mcr.microsoft.com/dotnet/runtime:7.0
💬 Qu’est-ce qui n’est pas cohérant dans cette commande
docker run -it -d --name BOSS --hostname the_boss hello-world
?
hello-world contient un binaire qui démarre,
affiche hello world et s’arrête. On ne peut pas obtenir une
invite de commande sur un processus qui est arrêté (-it) et ce
programme n’est pas prévu pour fonctionner comme un démon
(-d)
docker buildDans la manipulation précédente, nous avons utilisé l’image
hello world fournie par docker. Maintenant,
nous allons créer notre propre image hello world à l’aide
du langage enseigné dans l’école, le C#.
Pour réaliser cette tâche, nous aurons besoin de l’environnement .NET.
L’installation se réalise grâce à un script bash fournit
par Microsoft qui télécharge et installe les dépendances
nécessaires.
On commence par télécharger le script
d’installation Linux en version bash. On lui donne
ensuite les droits d’exécution.
ubuntu@m347:~$ wget https://dotnet.microsoft.com/download/dotnet/scripts/v1/dotnet-install.sh
...
2023-03-23 11:06:08 (379 KB/s) - ‘dotnet-install.sh’ saved [58293/58293]
ubuntu@m347:~$ chmod u+x dotnet-install.shSelon l’aide de la commande ./dotnet-install.sh --help,
on peut installer la version de notre choix, par exemple la version
8.0.201.
ubuntu@m347:~$ ./dotnet-install.sh –dry-run -c
8.0.2xx
ubuntu@m347:~$ ./dotnet-install.sh -c 8.0.2xx
...
dotnet-install: Installed version is 8.0.201
dotnet-install: Adding to current process PATH: `/home/ubuntu/.dotnet`. Note: This change will be visible only when sourcing script.
...
dotnet-install: Installation finished successfully.On doit ajouter le chemin d’accès à l’exécutable dotnet
dans la variable d’environnement PATH.
ubuntu@m347:~$ export PATH="$PATH:$HOME/.dotnet"
ubuntu@m347:~$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/home/ubuntu/.dotnet
ubuntu@m347:~$ dotnet --version
8.0.201Pour éviter toute confusion, nous travaillerons dans un répertoire particulier qu’il faudra créer. Ensuite, nous nous déplaçons dans ce répertoire pour créer un projet C# Console.
ubuntu@m347:~$ mkdir docker-hellocs
ubuntu@m347:~$ cd docker-hellocs/
ubuntu@m347:~/docker-hellocs$ dotnet new console -o App -n HelloCS
Le modèle « Console Application » a bien été créé.
Traitement des actions postérieures à la création en cours... Merci de patienter.
Exécution de « dotnet restore » sur App/HelloCS.csproj...
Identification des projets à restaurer...
Restauration effectuée de /home/ubuntu/docker-hellocs/App/HelloCS.csproj (en 66 ms).
Restauration réussie.
ubuntu@m347:~/docker-hellocs$ tree App/
App/
├── HelloCS.csproj
├── obj
│ ├── HelloCS.csproj.nuget.dgspec.json
│ ├── HelloCS.csproj.nuget.g.props
│ ├── HelloCS.csproj.nuget.g.targets
│ ├── project.assets.json
│ └── project.nuget.cache
└── Program.csOn peut voir le contenu actuel du fichier Program.cs et
se rendre compte qu’il contient déjà un Hello, World.
Nous allons simplement le modifier pour être sûr que c’est bien notre
programme qui sera démarré plus tard dans notre docker. Nous allons
afficher Hello, Docker! au lieu de
Hello, World!
// See https://aka.ms/new-console-template for more information
Console.WriteLine("Hello, Docker!");On peut déjà tester notre programme en le compilant et en l’exécutant
ubuntu@m347:~/docker-hellocs$ cd App/
ubuntu@m347:~/docker-hellocs/App$ dotnet run
Hello, Docker!Pour avoir une application qui est créée en version finale nous allons utiliser l’outil de publication en mode Release. Comme nous souhaitons obtenir un binaire Linux dans un seul fichier, nous allons également modifier notre fichier projet.
Les RuntimeIdentifier sont décrits sur cette page: RID
et le fait d’obtenir un seul fichier en sortie est décrit ici
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net8.0</TargetFramework>
<PublishSingleFile>true</PublishSingleFile>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
<RuntimeIdentifier>linux-x64</RuntimeIdentifier>
</PropertyGroup>
</Project>ubuntu@m347:~/docker-hellocs/App$ dotnet publish -c Release
MSBuild version 17.8.3+195e7f5a3 for .NET
Determining projects to restore...
All projects are up-to-date for restore.
HelloCS -> /home/ubuntu/docker-hellocs/App/bin/Release/net8.0/linux-x64/HelloCS.dll
HelloCS -> /home/ubuntu/docker-hellocs/App/bin/Release/net8.0/linux-x64/publish/
ubuntu@m347:~/docker-hellocs/App$ ls bin/Release/net8.0/linux-x64/publish/
HelloCS HelloCS.pdb
ubuntu@m347:~/docker-hellocs/App$ bin/Release/net8.0/linux-x64/publish/HelloCS
Hello, Docker!Pour créer sa propre image docker on doit indiquer les
étapes de fabrication de celle-ci dans un fichier nommé
Dockerfile. Pour construire notre image, nous allons nous
baser sur celles fournient par Microsoft
qui contiennent le framework déjà installé. Nous placerons les
directives suivantes dans notre fichier Dockerfile.
FROM permet de téléchargé chez Microsoft l’image
de base contant le framework .NET ainsi que celle contenant le
framework Core qui est prévu pour être portable. Dans le
conteneur instancié avec la première image, on créera l’exécutable
final. Comme cette étape génère beaucoup de fichiers intermédiaires qui
ne sont pas utiles au fonctionnement, on utilisera le conteneur
instancié avec la seconde
image comme image de base pour le conteneur final. Le deuxième
conteneur ne contiendra que le runtime et l’exécutableWORKDIR indique le répertoire de travailCOPY demande à docker de copier tout notre répertoire
courant . dans le conteneurRUN sont des commandes qui vont être exécutées dans le
conteneur. En l’occurence, il y aura une restauration du projet et une
génération d’exécutable dans un dossier nommé out_dir en
mode ReleaseCOPY du résultat out_dir depuis le premier
conteneur portant l’alias build-env, dans le second
conteneur, celui contenant l’image CoreENTRYPOINT définit la commande à exécuter lorsqu’on
démarre le conteneur# build image avec SDK
FROM mcr.microsoft.com/dotnet/sdk:latest AS build-env
# définit le répertoire de travail
WORKDIR /app
# Copie tout le répertoire courant dans le conteneur
COPY . ./
# Restore nécessaire pour générer le fichier de dépendances
RUN dotnet restore
# build et publish en version release dans le répertoire out_dir
RUN dotnet publish -c Release -o out_dir
# build runtime image
FROM mcr.microsoft.com/dotnet/runtime:latest
# définit le répertoire de travail
WORKDIR /app
# Met à jour le PATH pour inclure le répertoire de l'exécutable
ENV PATH="/app:${PATH}"
# Copie le contenu du répertoire out_dir du conteneur build-env dans le conteneur runtime
COPY --from=build-env /app/out_dir .
# définit la commande à exécuter lors du démarrage du conteneur
ENTRYPOINT ["HelloCS"]Une fois le fichier créer, on peut demander à docker de
construire l’image (ATTENTION au caractère . à la fin de
cette ligne!)
ubuntu@m347:~/docker-hellocs/App$ docker build -t docker-hellocs -f Dockerfile .
[+] Building 84.1s (14/14) FINISHED
=> [internal] load .dockerignore 0.4s
=> => transferring context: 2B 0.0s
=> [internal] load build definition from Dockerfile 0.3s
=> => transferring dockerfile: 390B 0.0s
=> [internal] load metadata for mcr.microsoft.com/dotnet/runtime:8.0 0.9s
=> [internal] load metadata for mcr.microsoft.com/dotnet/sdk:8.0 1.0s
=> [build-env 1/5] FROM mcr.microsoft.com/dotnet/sdk:8.0@sha256:f712881bafadf0e56250ece1da28ba2baedd03fb3dd49a67f209f9d0cf928e81 58.5s
=> => resolve mcr.microsoft.com/dotnet/sdk:8.0@sha256:f712881bafadf0e56250ece1da28ba2baedd03fb3dd49a67f209f9d0cf928e81 0.3s
...
=> [internal] load build context 0.8s
=> => transferring context: 164.24MB 0.6s
=> [stage-1 1/3] FROM mcr.microsoft.com/dotnet/runtime:8.0@sha256:db181c925678b0c193c6bdeaf9d04759051aa0a4ab12f91c267f32acc765f35f 22.3s
=> => resolve mcr.microsoft.com/dotnet/runtime:8.0@sha256:db181c925678b0c193c6bdeaf9d04759051aa0a4ab12f91c267f32acc765f35f 0.3s
...
=> => extracting sha256:c0e5d70de3d5ebb221b0f61c574f9f497fd5e4e190c5bbffc281ef5dc6f10e2c 61.8s
=> [stage-1 2/3] WORKDIR /app 0.9s
=> [build-env 2/5] WORKDIR /app 1.9s
=> [build-env 3/5] COPY . ./ 2.2s
=> [build-env 4/5] RUN dotnet restore 13.1s
=> [build-env 5/5] RUN dotnet publish -c Release -o out_dir 5.4s
=> [stage-1 3/3] COPY --from=build-env /app/out_dir . 0.9s
=> exporting to image 0.6s
=> => exporting layers 0.5s
=> => writing image sha256:edd912d838879559c5a675ea460ef1a3d77ff2605989f87c5f4db6a73f5a330c 0.0s
=> => naming to docker.io/library/docker-hellocs On trouve maintenant une nouvelle image portant notre nom
docker-hellocs dans notre poll d’images.
ubuntu@m347:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker-hellocs latest 8070eff0a81d 2 minutes ago 278MBEt on peut démarrer une instance de conteneur avec cette image. Au
démarrage du conteneur c’est le binaire HelloCS qui sera
lancée depuis le répertoire /app
ubuntu@m347:~$ docker run docker-hellocs
Hello, Docker!On peut également faire le même travail en redéfinissant le point
d’entrée avec la commande “bash” au lieu du HelloCS, ça va
nous placer dans le conteneur et plus précisément dans une
invite de commande bash
ubuntu@m347:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker-hellocs latest 8070eff0a81d 32 minutes ago 208MB
ubuntu@m347:~$ docker run -it --entrypoint "bash" docker-hellocsOn peut alors constater :
/app.PATH est correctement définieOn peut alors manuellement lancer le programme
HelloCS
root@f5171bc227ca:/app# ls -l
total 1
-rwxr-xr-x 1 root root 66743194 Mar 21 13:59 HelloCS
-rw-rw-r-- 1 root root 10476 Mar 21 13:59 HelloCS.pdb
root@f5171bc227ca:/app# echo $PATH
/app:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root@f5171bc227ca:/app# HelloCS
Hello Docker!Lorem IpsumLe lorem ipsum (également appelé faux-texte, lipsum, ou bolo bolo1) est, en imprimerie, une suite de mots sans signification utilisée à titre provisoire pour calibrer une mise en page, le texte définitif venant remplacer le faux-texte dès qu’il est prêt ou que la mise en page est achevée.
Généralement, on utilise un texte en faux latin (le texte ne veut rien dire, il a été modifié), le Lorem ipsum ou Lipsum. L’avantage du latin est que l’opérateur sait au premier coup d’œil que la page contenant ces lignes n’est pas valide et que l’attention du lecteur n’est pas dérangée par le contenu, lui permettant de demeurer concentré sur le seul aspect graphique.
Il circule des centaines de versions différentes du lorem ipsum, mais ce texte aurait originellement été tiré de l’ouvrage écrit par Cicéron en 45 av. J.-C., De finibus bonorum et malorum (Liber Primus, 32), texte populaire à cette époque, dont l’une des premières phrases est : « Neque porro quisquam est qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit… » (« Il n’existe personne qui aime la souffrance pour elle-même, ni qui la recherche ni qui la veuille pour ce qu’elle est… »).
Il est fréquent en programmation de devoir réaliser des tâches que d’autres ont réalisés avant nous. Ainsi, le Lorem Ipsum existant depuis plusieurs années, il est fort probable qu’il existe déjà un code source permettant de le générer.
C’est le cas avec ce paquet nommé NLipsum que l’on peut installer grâce au gestionnaire de paquets NuGet. Il nous reste à savoir comment l’utiliser et comment l’installer.
Après avoir crée un projet C# tel que cela a été vu lors de la manipulation précédente, il suffit de lancer la commande fournie sur le site pour ajouter cette librairie à notre projet
ubuntu@m347:~/lorem/App$ dotnet add package NLipsum --version 1.1.0Cette partie est plus compliquée car la documentation est plutôt pauvre sur le site… On trouve cependant un tout petit exemple sur leur wiki.
// Génère un tableau de 1 phrase et prend la première phrase du tableau
NLipsum.Core.LipsumGenerator.GenerateSentences(1)[0]On peut traduire cette exemple ainsi:
const int NUM_PHRASES = 3; // On veut 3 phrases
string[] lorem = NLipsum.Core.LipsumGenerator.GenerateSentences(NUM_PHRASES); // On génère un tableau de 3 phrasesOn peut également utiliser des paragraphes ainsi:
const int NUM_PARAGRAPHS = 3; // On veut 3 paragraphes
string[] lorem = NLipsum.Core.LipsumGenerator.GenerateParagraphs(NUM_PARAGRAPHS); // On génère un tableau de 3 paragraphesEn vous basant sur cette librairie, on vous demande de réalisez un conteneur capable de vous fournir un texte de type Lorem Ipsum de 3 paragraphes. Ci-dessous, vous trouvez le résultat final que vous devez obtenir. Le texte est chaque fois différent.
ubuntu@m347:~$ docker run lorem
Ullamcorper ipsum vero takimata elitr dolore laoreet sed rebum no rebum takimata ut voluptua. Wisi rebum tempor commodo takimata eos tempor lorem eos diam eirmod. Dolore amet dolor gubergren ut sed magna no et lorem clita sit assum. Dolore nulla adipiscing erat sed sit qui dolore duis voluptua clita sea elitr duis magna. Aliquip sea sea sanctus kasd dolore elitr et kasd stet eum te dolor ipsum dolor sea eros. Justo lorem dolore eos commodo eirmod duo no justo feugait accusam sea sit lorem suscipit est ipsum et consequat. Lorem nonumy eos tempor aliquyam illum.
Et nostrud labore dolor dignissim amet ipsum diam gubergren dolor ut. Ipsum ad mazim clita et sit sea consetetur. Gubergren sadipscing ut ipsum rebum ipsum esse lorem. Takimata velit eirmod tempor takimata. Dolore stet velit gubergren vero sanctus labore sed ut nulla facilisi diam. Diam liber consetetur. Invidunt aliquip invidunt enim vero illum est aliquyam ut at et. Liber ipsum rebum vel dolor ipsum dolore sanctus consequat aliquyam ex magna dolor ea enim aliquip eros gubergren. Dolore consetetur kasd sit at assum no commodo vero magna lorem. Option ea est. Aliquyam elitr feugait. Consetetur kasd ipsum luptatum. Iriure stet mazim dolore tincidunt lorem. Suscipit aliquip tempor nonumy. Liber et et kasd quis ea diam clita ut velit velit aliquyam magna lorem. Sit suscipit duo lorem est possim amet tation invidunt in vero. Diam clita gubergren ut takimata invidunt. Accumsan consectetuer diam amet justo.
Amet labore tation amet eirmod et dolore magna vel dolores diam dolor tincidunt. Elit illum ea ut tempor ipsum est molestie elitr labore eleifend. Sanctus duis sit ut ullamcorper doming voluptua justo option clita dolor luptatum justo diam. Justo sanctus labore ipsum zzril rebum magna takimata option duo ex ut labore et elitr. Wisi liber doming sed dolor. Sed clita duo eleifend eos et amet gubergren ut dolor nonumy lorem tempor duo lorem sanctus ea vero sed. Et sit nam vel nobis sed. Magna feugiat justo amet tempor diam diam. Vero diam kasd consequat ex velit sed magna nonumy dignissim elitr no ipsum dolore dolores labore voluptua consetetur. Erat ea ut commodo sadipscing sit et justo accumsan congue aliquyam dolor nisl esse aliquip praesent est lorem tempor. Consequat invidunt vel. Sed at doming sadipscing commodo kasd kasd ipsum ea. Voluptua liber invidunt. Sed soluta lorem rebum stet feugiat zzril voluptua dolore amet. Blandit amet sit ut diam justo augue takimata lorem feugiat vel accusam. Dolore diam magna kasd enim dolor velit sanctus sanctus ut eros ut. Takimata sed rebum elitr amet iriure sea.
ubuntu@m347:~$ docker run lorem
Ipsum diam diam ad ut tempor sea ea gubergren diam ipsum vero enim gubergren nulla tempor. Et nobis et feugait. Iriure in exerci et et eirmod duo. Accusam
...Dans cette manipulation, nous allons mettre en pratique un des
aspects de la sécurité lié à l’emploi de conteneur docker.
Par manque de temps, nous ne traiterons pas de tous les autres aspects
listés ci-dessous:
Cela nous vous dispense pas de vous documentez et de
les mettre en pratique si vous devez utiliser docker dans
un monde professionnel.
Dans tous les systèmes d’exploitation, les processus sont lancés avec
une identité. Avec Linux, l’identité correspond le plus souvent au login
de l’utilisateur mais cette identité peut-être une autre parmi celles
présente dans le fichier /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/var/run/ircd:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
systemd-network:x:100:102:systemd Network Management,,,:/run/systemd:/usr/sbin/nologin
systemd-resolve:x:101:103:systemd Resolver,,,:/run/systemd:/usr/sbin/nologin
systemd-timesync:x:102:104:systemd Time Synchronization,,,:/run/systemd:/usr/sbin/nologin
messagebus:x:103:106::/nonexistent:/usr/sbin/nologin
syslog:x:104:110::/home/syslog:/usr/sbin/nologin
_apt:x:105:65534::/nonexistent:/usr/sbin/nologin
tss:x:106:111:TPM software stack,,,:/var/lib/tpm:/bin/false
uuidd:x:107:112::/run/uuidd:/usr/sbin/nologin
tcpdump:x:108:113::/nonexistent:/usr/sbin/nologin
landscape:x:109:115::/var/lib/landscape:/usr/sbin/nologin
pollinate:x:110:1::/var/cache/pollinate:/bin/false
usbmux:x:111:46:usbmux daemon,,,:/var/lib/usbmux:/usr/sbin/nologin
sshd:x:112:65534::/run/sshd:/usr/sbin/nologin
systemd-coredump:x:999:999:systemd Core Dumper:/:/usr/sbin/nologin
ubuntu:x:1000:1000:Module 347:/home/ubuntu:/bin/bashDans cette liste, on reconnaît des utilisateurs présents sur la machine tels que:
root, c’est Dieu tout puissant sur la machine. Il a
tous les droits et ⚡☠ c’est très dangereux ☠⚡!nobody, c’est le négatif de Dieu tout
puissant. Il est personne et n’a aucuns
droits!ubuntu, c’est un utilisateur standard avec des
droits spécifiques. Il est limité à ses propres fichiers présent dans
son répertoire /home/ubuntuIl y a d’autres utilisateurs qui sont des utilisateurs
systèmes. C’est-à-dire des utilisateurs qui ne peuvent pas se loguer sur
le système mais qui sont utilisés par le système pour réaliser certaines
tâches. Par exemple, l’utilisateur système www-data
correspond à l’utilisateur système utilisé pour réaliser des tâches liée
au serveur web.
Explication
Lorsque vous naviguez sur Internet et que vous visitez le site www.example.com, quel nom d’utilisateur le système d’exploitation qui fait fonctionner ce site va-t-il vous attribuer ? Il ne vous connais pas… pourtant vous devez exister en tant que quelqu’un chez lui vu que chaque processus est lié à un utilisateur.
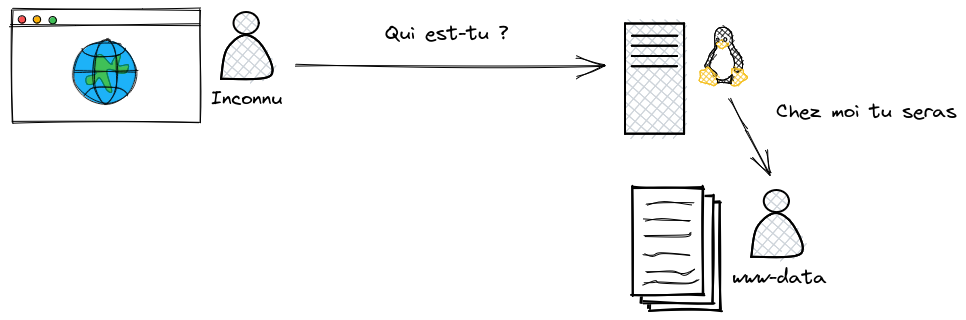
Et bien vous allez devenir www-data et obtenir les
droits correspondants. Ainsi le système d’exploitation pourra vous
donnez accès à certains dossiers et certains fichiers. Dans l’exemple
ci-dessous, vous aurez le droit de lire le contenu du fichier
index.html
-r--r----- 1 www-data www-data 10918 jun 30 2021 index.htmlPour comprendre les droits affichés ci-dessus faites un tour sur la page wikipedia traitant des permissions UNIX.
Lorsque l’utilisateur lance un processus, le système d’exploitation
va le plus souvent utiliser l’identité de l’utilisateur pour démarrer ce
processus. Dès lors, ce processus aura les droits associés à
l’utilisateur. Par exemple, si l’utilisateur ubuntu lance
le processus hello, le processus hello aura
les droits de l’utilisateur ubuntu.
ubuntu@m347:~$ ./hello
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
22410 ubuntu 20 0 1068 4 0 R 0.0 0.0 0:00.00 ./helloDans l’example ci-dessus, on peut voir dans la colonne
USER que l’utilisateur ubuntu à lancé le
processus hello. Dès lors, le processus hello
a les droits de l’utilisateur ubuntu. Par exemple, si le
processus hello essaye de créer un nouvel utilisateur dans
le fichier /etc/passwd, il ne pourra pas le faire car
l’utilisateur ubuntu n’a pas les droits d’écriture sur ce
fichier.
ubuntu@m347:~$ ls -l /etc/passwd
-rw-r--r-- 1 root root 1766 Mar 23 10:18 /etc/passwdLe processus hello est donc limité dans ses actions. Si
un pirate informatique parvient à détourner le fonctionnement du
processus hello, il ne pourra pas faire grand chose.
Comme on l’a déjà vu précédemment, on conteneur va isolé un
processus. Le processus isolé ne verra pas les interfaces réseaux, les
points de montage, les autres processus etc. Malgrès tout, par défaut,
docker démarrera le processus en tant que root
et c’est potentiellement dangereux.
Démonstration root
Dans un terminal, on démarre un conteneur en mode interactif. En
réalité, ce qui est démarré ici c’est un processus bash
isolé dans une arborescence Ubuntu. On peut voir que
l’identifiant du conteneur est 2b66b6cd7d5d et apparemment,
l’utilisateur qui a démarré ce processus est root
ubuntu@m347:~$ sudo docker run -it ubuntu:latest
root@88b4b5bb20e7:/# id
uid=0(root) gid=0(root) groups=0(root)
root@88b4b5bb20e7:/# whoami
rootDans un autre terminal sur l’hôte, on cherche ce processus et on regarde qui l’a lancé
ubuntu@m347:~$ ps faux
...
root 762 0.0 0.0 720436 5832 ? Sl 07:19 0:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 88b4b5bb20e7
root 784 0.0 0.0 4624 2248 pts/0 Ss+ 07:19 0:00 \_ /bin/bashOn voit le processus bash démarré par
docker par le biais de containerd,
shim et runc et on voit également que
l’utilisateur associé au processus est bien root. Donc le
root du conteneur est le root de l’hôte.
Autrement dit, depuis le conteneur j’ai un contrôle total sur l’hôte
!
Si on est développeur, ça peut-être très gênant de démarrer un
processus en tant que root alors qu’on est entrain de le
développer et qu’il est, par conséquent, un processus qui n’est pas
abouti. Cela peut ouvrir la porte à de sérieux problèmes de
sécurités.
Avec les mêmes conséquence, on peut également imaginer qu’un pirate informatique cherchera à déclencher des attaques connus sur le système d’exploitation de l’hôte. Par exemple, il peut chercher à déclencher une attaque de type Shellshock. Pour cela, il va utiliser un processus qui va exploiter une faille de sécurité dans le shell
bashde l’hôte. Comme le processus est lancé en tant queroot, il aura tous les droits sur l’hôte.
Il existe un espace de nom qui permet de palier à ce problème. C’est le namespace user. Son objectif est de créer un mappage entre les utilisateurs de l’hôte et les utilisateurs du conteneur.
Faisons un exemple tout simple. Prenons deux terminaux
bash. Dans les deux terminaux, on se place à la racine de
l’utilisateur ubuntu.
ubuntu@m347:~$ cd ~
ubuntu@m347:~$ pwd
/home/ubuntuDans le premier terminal, on lance le processus bash en
passant par la commande unshare. On demande à cette
commande de projeter notre utilisateur ubuntu en
tant que root dans un nouveau bash
conteneurisé.
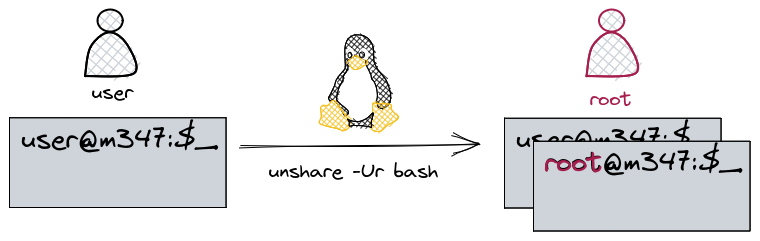
Ainsi, bash démarre un nouveau bash en tant
que root. Mais ce root n’est pas le
root de l’hôte. Il est le root du processus
bash qui est isolé dans un nouvel espace
de nom.
bash, seul l’espace de nom est isolé. On peut
donc accéder au reste de la machine qui n’a pas été isolé. Dans un
vrai conteneur, le reste de la machine est également isolé
Créons maintenant un fichier en placant un texte quelconque dedans et vérifions que le fichier a bien été créé avec les bons droits.
## Point de départ, on est dans le premier terminal
## Qui suis-je ?
ubuntu@m347:~$ whoami
ubuntu
## Projette moi en tant que root dans un nouveau espace de nom et démarre un nouveau processus bash
ubuntu@m347:~$ unshare -Ur bash
## Qui suis-je maintenant ?
root@m347:~# whoami
root
## Créons un fichier
root@m347:~# echo "Un texte quelconque" > /tmp/test.txt
## Vérifions les droits du fichier
root@m347:~# ls -l /tmp/test.txt
-rw-rw-r-- 1 root root 20 mar 24 10:40 /tmp/test.txt
# Il appartient bien à root. Vérifions son contenu
root@m347:~# cat /tmp/test.txt
Un texte quelconqueDans le second terminal qui est resté dans l’espace de nom d’origine:
## Qui suis-je ?
ubuntu@m347:~$ whoami
ubuntu
## Vérifions que le fichier existe ainsi que son contenu
ubuntu@m347:~$ cat /tmp/test.txt
Un texte quelconque
## Qui est le propriétaire du fichier ?
ubuntu@m347:~$ ls -l /tmp/test.txt
-rw-rw-r-- 1 ubuntu ubuntu 20 mar 24 11:00 /tmp/test.txtOn voit que le fichier appartient bien à root dans le
bash dont l’espace de nom est isolé mais qu’il
appartient à ubuntu dans l’espace de nom d’origine. C’est
le mappage qui a été fait par unshare qui a permis de faire
cela. On a donc créer une isolation de l’utilisateur entre le
bash démarré par unshare et le
bash de l’hôte. Le root dans l’espace de nom
isolé n’est qu’un simple utilisateur dans l’espace de nom standard.
Dans les conteneurs docker, le mappage n’est pas présent
avec une configuration de base comme on a pu le constater précédemment.
On peut configurer docker pour faire du mappage
d’utilisateur et faire en sorte que dans le conteneur, l’utilisateur
root soit un root du conteneur. Ce ne sera pas
le même root que celui de l’hôte. Dès lors, le
root du conteneur aura tous les droits dans le conteneur
mais en dehors du conteneur, ce même root aura les droits
de l’utilisateur nobody, c’est-à-dire, aucuns
droits.
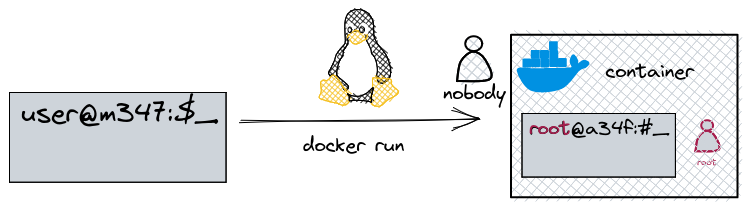
Le mappage est définit dans les fichiers /etc/subuid et
/etc/subgid. Par exemple, dans le fichier
/etc/subuid on trouve les informations suivantes:
ubuntu@m347:~$ cat /etc/subuid
ubuntu:100000:65536Elles signifient que l’utilisateur ubuntu à le droit de
faire de l’impersonation. Il a le droits de créer 65536
mappages. Les identifiants du conteneur seront augmentés de
100000 par rapport aux identifiant de l’hôte. Ainsi,
l’utilisateur root du conteneur qui à l’identifiant
0 dans ce dernier, aura l’identifiant 100000
dans l’hôte. Il ne sera donc personne dans le système hôte car
il n’y a rien dans le système hôte qui a l’identifiant
100000.
En informatique, l’impersonation consiste à Subroger l’identité d’un utilisateur dans un système informatique, notamment dans le cas où cette opération est conduite de façon légitime par un opérateur accédant au compte d’un client dans le cadre d’une assistance utilisateur.
Pour réaliser ce travail, on va devoir démarrer docker
en lui demandant d’utiliser le namespace user.
On peut faire ce travail de différente
manière. Celle proposée ici consiste à modifier le fichier de
configuration du démon docker. Dans ce fichier, on va
ajouter la ligne userns.
ubuntu@m347:~$ sudo nano /etc/docker/daemon.json
[sudo] password for ubuntu:
{
"userns-remap": "ubuntu:ubuntu"
}Une fois que c’est fait, il faut redémarrer le démon
docker
ubuntu@m347:~$ sudo systemctl restart dockerSi on relance le même conteneur que précédemment, du point de vue du
conteneur, on est toujours root avec l’identifiant
0
ubuntu@m347:~$ docker run -it ubuntu:latest
root@82a2343d3597:/# id
uid=0(root) gid=0(root) groups=0(root)
root@82a2343d3597:/# whoami
rootMais cette fois, du point de vue de l’hôte, le processus
bash est démarré en tant qu’utilisateur
100000.
ubuntu@m347:~$ ps faux | grep -A2 82a2343d3597
root 2378 0.0 0.0 712212 6572 ? Sl 09:03 0:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 82a2343d3597
100000 2399 0.0 0.0 4492 2276 pts/0 Ss+ 09:03 0:00 \_ /bin/bashSi on va un peu plus loin, on peut créer un utilisateur dans le
conteneur, par exemple, l’utilisateur ubuntu.
oot@82a2343d3597:/# useradd ubuntu
root@82a2343d3597:/# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
...
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
_apt:x:100:65534::/nonexistent:/usr/sbin/nologin
ubuntu:x:1000:1000::/home/ubuntu:/bin/shIl obtiendra l’identifiant 1000 dans le conteneur. Par
défaut, lorsqu’on switch sur l’utilisateur
ubuntu avec la commande su, c’est un terminal
sh qui sera lancé. On peut voir cette particularité dans la
dernière colonne de la ligne concernant l’utilisateur
ubuntu (ci-dessus). C’est pour cette raison que le
prompt est maintenant $
root@82a2343d3597:/# su ubuntu
$ id
uid=1000(ubuntu) gid=1000(ubuntu) groups=1000(ubuntu)
$ whoami
ubuntuDu point de vue de l’hôte, le processus sh à du être
lancé par l’utilisateur
La preuve
ubuntu@m347:~$ ps faux | grep -A4 82a2343d3597
root 25180 0.0 0.4 711708 8264 ? Sl 11:02 0:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 82a2343d3597
100000 25200 0.0 0.1 4108 3332 pts/0 Ss 11:02 0:00 \_ /bin/bash
100000 25262 0.0 0.1 4492 2768 pts/0 S 11:13 0:00 \_ su ubuntu
101000 25264 0.0 0.0 2608 532 pts/0 S+ 11:13 0:00 \_ shla grande force de docker est aussi sa plus grande
faiblesse. docker démarre ses conteneurs en mode
root par défaut. C’est une manière de procéder qui a été
choisie pour des raisons de simplicité. En effet, en tant que
root, on peut faire tout ce que l’on veut dans le
conteneur. Malheureusement, cette simplicité à un coût. Si un attaquant
parvient à s’évader du conteneur, il se trouvera sur la machine hôte
avec les mêmes droits que root.
Le fait d’être le même root que l’hôte pose également un
problème lié aux failles de sécurité du noyau. Si le noyau est
vulnérable, l’attaquant peut exploiter cette vulnérabilité pour prendre
le contrôle de la machine hôte. C’est ce qu’on appelle une vulnérabilité
de l’escalade de privilèges. C’est le cas par exemple de la
vulnérabilité DirtyCow
qui a été découverte en 2016. Cette vulnérabilité permet à un
utilisateur lambda de prendre le contrôle de la machine hôte en
exploitant une faille de sécurité du noyau. Cette vulnérabilité a été
exploitée par des attaquants pour prendre le contrôle de serveurs
Azure.
Il reste encore le fait de pouvoir générer nous même nos images et les mettre à disposition de tous sur le site Docker Hub. C’est une pratique qui peut être dangereuse. En effet, si l’image que vous avez créée contient une faille de sécurité, tous les utilisateurs de cette image seront vulnérables. De même, si vous ne maintenez pas votre image à jour en la regénérant régulièrement, les utilisateurs de cette image seront vulnérables aux failles de sécurité découvertes dans les versions précédentes de l’image.
Si on combine ses 3 éléments, on obtient un cocktail explosif.
Il reste encore les problèmes inhérents à docker
lui-même.

ChaosDB: How We Hacked Databases of Thousands of Azure Customers
D’autres systèmes de conteneurs tel que incus démarre
automatiquement leur conteneurs en mode unprivileged,
c’est-à-dire, en utilisant automatiquement le namespace
user.
ubuntu@m347:~$ incus launch ubuntu:24.04 c1
Creating c1
Starting c1
ubuntu@m347:~$ incus exec c1 bash
root@c1:~# id -u
0
root@c1:~# whoami
rootVu de l’hôte
root 31475 0.0 0.2 46924 5420 ? S 11:32 0:00 \_ /snap/incus/current/bin/incus forkexec c1
1000000 31479 0.0 0.1 8960 2668 pts/1 Ss+ 11:32 0:00 \_ bashQuand on sait que le développeur des conteneurs Incus Stéphane Graber est également un des
auteurs du code source du namespace user du
noyau Linux, on comprend que ce système utilise ça par défaut 😉.
invente-un-muSteeve Droz a crée un programme en Java permettant de créer une machine à inventer des mots. Le fonctionnement du programme est décrit sur son dépôt git.
Votre travail consiste à créer deux recettes
Dockerfile permettant la création d’une image
docker capable de faire fonctionner ce programme.
Dans un premier temps, vous devez déjà être en mesure de faire fonctionner le programme sur votre machine. Soyez précis et notez toutes les étapes nécessaires pour faire fonctionner le programme dans votre machine hôte.
Choisissez ensuite une image de base qui convient à la réalisation du
travail. Vous pouvez utiliser une image ubuntu,
alpine ou une autre image qui vous semble pertinante.
Le programme invente-un-mu doit être démarré
automatiquement lors du démarrage du conteneur. Le programme générera
toujours le même nombre de mots, par exemple 20 mots.
ubuntu@m347:~$ docker run invente-un-mu
abille
abrimpluna
assinas
X20
...Dans une seconde étape, vous devrez donner la possibilité à
l’utilisateur du conteneur de paramétrer le nombre de mots à générer.
Par exemple, si l’utilisateur lance la commande
docker run invente-un-mu --count 10, le programme générera
10 mots. L’utilisation des arguments peut être réalisée autrement que
celle proposée ici.
ubuntu@m347:~$ docker run invente-un-mu --count 10
abille
abrimpluna
assinas
X10
...Le programme figlet est un programme qui permet de créer
des bannières de texte. Il est très
utilisé dans le monde de l’administration système pour créer des
bannières de texte pour les scripts shell.
On vous demande de réaliser une image docker permettant
la réalisation de la banière suivante
Vous avez déjà vu cette image dans ce cours mais cette fois, c’est à vous de réaliser le travail.
Lorsqu’on démarre un conteneur, docker crée
automatiquement des points de
montage.
On peut les visualiser à l’aide de la commande mount
root@aa898b7f3cab:/# mount
overlay on / type overlay (rw,relatime,lowerdir=/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/l/ASXXAW2547JEJWSOAZOI7UFZCA:/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/l/HPAS7BR2367OIJ6UUXP6HENA4Q,upperdir=/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/fb886671867b90cfe2bfb40744d7e0d2b747a908f444f0b509d9058ea5635eb5/diff,workdir=/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/fb886671867b90cfe2bfb40744d7e0d2b747a908f444f0b509d9058ea5635eb5/work,xino=off)
...On y trouve notamment la racine / qui pointe sur un
système de fichier de type OverlayFS. Le
principe du système de fichiers overlay est décrit sur la page docker
overlayfs.
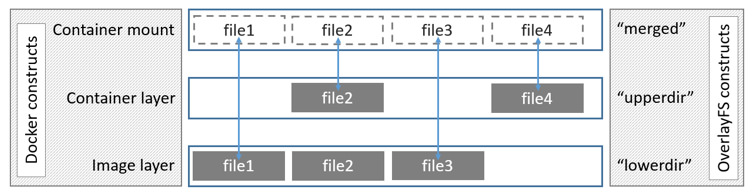
Il existe d’autre système de fichier (overlay2, aufs, btrfs, zfs, devicemapper, …) mais l’overlay est le plus utilisé par
docker(etpodman). Pour connaître le système de fichier utilisé pardocker, on peut utiliser la commandedocker info
ubuntu@m347:~$ docker info | grep -i "Storage Driver"
Storage Driver: zfsOn peut facilement retrouver ces informations pour notre conteneur
grâce à la commande docker inspect nom_de_l_image
jq est un utilitaire de mise en forme des flux JSON.
Il permet de filtrer les données JSON et de les formater. Il est
disponible dans les dépôts officiels de la plupart des distributions
Linux.
ubuntu@m347:~$ docker image inspect ubuntu --format '{{json .GraphDriver.Data}}' | jq .
{
"MergedDir": "/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/9d15649fd988...ebb/merged",
"UpperDir": "/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/9d15649fd988...ebb/diff",
"WorkDir": "/var/snap/docker/common/var-lib-docker/100000.100000/overlay2/9d15649fd988...ebb/work"
}Ce qui nous intéresse vraiment dans ce principe et qui sera la cause
de certains problèmes, c’est qu’on conteneur docker est
éphémère. Ce qui signifie que si je crée un fichier dans un conteneur,
au moment ou je détruis ce conteneur, tout ce qui aura été fait dans ce
conteneur sera perdu.
Démonstration
Dans la démonstration ci-dessous on peut voir le démarrage d’un
conteneur ubuntu. Une fois dans le conteneur, on crée un
fichier nouveau_fichier dans lequel on place le texte
"Hello". On quitte le conteneur et on le détruit. Lorsqu’on
relance un conteneur ubuntu, le fichier à disparut. On peut
aussi facilement comprendre ça en voyant que le nom d’hôte du conteneur
est chaque fois différent. C’est comme si on était chaque fois sur une
autre machine…
ubuntu@m347:~$ docker run -it ubuntu
root@e1f008654921:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
root@e1f008654921:/# echo "Hello" > nouveau_fichier
root@e1f008654921:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt nouveau_fichier opt proc root run sbin srv sys tmp usr var
root@e1f008654921:/# exit
exit
ubuntu@m347:~$ docker rm -f e1f008654921
ubuntu@m347:~$ docker run -it ubuntu
root@7d9773708a2a:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr varOn peut choisir de rester dans le même conteneur sans le détruire. Dans ce cas, on peut voir que le fichier est toujours présent.
Si on redémarre le même conteneur alors les données seront toujours présentes.
ubuntu@m347:~$ docker run -it -d --name c1 ubuntu
cdb41f74b886b7ef46fda1758fd1ae6b71493d70c2ea1b7c1b11ba41a0724837
ubuntu@m347:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cdb41f74b886 ubuntu "/bin/bash" 5 seconds ago Up 3 seconds c1
ubuntu@m347:~$ docker exec -it c1 /bin/bash
root@cdb41f74b886:/# echo test > /home/ubuntu/fichier.txt
root@cdb41f74b886:/# ls -l /home/ubuntu
total 1
-rw-r--r-- 1 root root 5 May 27 06:22 fichier.txt
root@cdb41f74b886:/# exit
exit
ubuntu@m347:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cdb41f74b886 ubuntu "/bin/bash" 59 seconds ago Up 57 seconds c1
ubuntu@m347:~$ docker stop c1
c1
ubuntu@m347:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cdb41f74b886 ubuntu "/bin/bash" About a minute ago Exited (137) 4 seconds ago c1
ubuntu@m347:~$ docker start c1
c1
ubuntu@m347:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cdb41f74b886 ubuntu "/bin/bash" About a minute ago Up 3 seconds c1
ubuntu@m347:~$ docker exec -it c1 /bin/bash
root@cdb41f74b886:/# ls -l /home/ubuntu
total 1
-rw-r--r-- 1 root root 5 May 27 06:22 fichier.txtDocker propose différente solution pour persister des données. L’idée étant de conserver les données même après la destruction d’un conteneur. Pour comprendre où les données seront déposées, il faut se placer du point de vue de l’hôte. Vu de l’hôte, les données peuvent être sauvegardées dans:
root du conteneur être le vrai root de l’hôte.
Dès lors, on sera confronté à des problèmes de droits pour réaliser ce
genre de montage.
docker volumeLes volumes sont crées et gérés par docker. Il existe
une commande spécifique pour ça, elle se nomme sans surprise
docker volume
ubuntu@m347:~$ docker volume
Usage: docker volume COMMAND
Manage volumes
Commands:
create Create a volume
inspect Display detailed information on one or more volumes
ls List volumes
prune Remove all unused local volumes
rm Remove one or more volumes
Run 'docker volume COMMAND --help' for more information on a command.Lorsqu’on demande à docker de nous créer un volume, il
va crée un emplacement sur le disque accessible aux conteneurs qui en
feront la demande.
ubuntu@m347:~$ docker volume create sharedvol
sharedvol
ubuntu@m347:~$ docker volume ls
DRIVER VOLUME NAME
local sharedvol
ubuntu@m347:~$ docker volume inspect sharedvol
[
{
"CreatedAt": "2023-03-22T09:56:12Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/100000.100000/volumes/sharedvol/_data",
"Name": "sharedvol",
"Options": {},
"Scope": "local"
}
]Mountpoint nous indique où se situe réellement les
informations que l’on persistera. On peut se rendre compte que le chemin
d’accès comporte un double numéro 100000.100000. Cette
valeur est en lien avec le namespace user expliqué plus
haut. On peut également se rendre compte que les droits sur ce
répertoire sont attribués ainsi:
ubuntu@m347:~$ sudo ls -l /var/lib/docker/100000.100000/volumes/sharedvol/
total 4
drwxr-xr-x 2 100000 100000 4096 mars 22 13:48 _dataL’utilisateur ayant pour uid 100000 aura
les droits d’écritures dans ce répertoire. Autrement dit, chaque
conteneur démarrer ayant un mappage utilisateur
| Conteneur | Hôte |
|---|---|
root |
- |
uid 0 |
uid 100000 |
permettra au root du conteneur d’écrire des informations
dans ce répertoire sur l’hôte.
Il ne reste plus qu’à indiquer au conteneur l’endroit dans lequel il va devoir monter ce volume. Ça se fait ainsi:
ubuntu@m347:~$ docker run -it --volume sharedvol:/vol:rw ubuntu
root@af589abbd7ec:/# Le paramètre --volume est composé de trois valeurs
séparées par :
| Nom du volume | Point de montage | Droits |
|---|---|---|
sharedvol |
/vol |
rw (read / write) |
On peut voir maintenant dans le conteneur un nouveau dossier qui se
nomme /vol. Si on place des informations dans ce dossier,
elles iront se placer dans le répertoire de
/var/lib/docker/100000.100000/volumes/sharedvol/_data
l’hôte.
Démonstration
Depuis le conteneur
root@70a9671bebb3:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var vol
root@70a9671bebb3:/# echo "Test" > /vol/nouveau_fichier
root@70a9671bebb3:/# ls -l /vol
total 1
-rw-r--r-- 1 root root 5 Mar 22 10:00 nouveau_fichierDepuis l’hôte
ubuntu@m347:~$ sudo ls -l /var/lib/docker/100000.100000/volumes/sharedvol/_data
total 1
-rw-r--r-- 1 100000 100000 5 Mar 22 10:00 nouveau_fichier
ubuntu@m347:~$ sudo cat /var/lib/docker/100000.100000/volumes/sharedvol/_data/nouveau_fichier
TestSi on arrête le conteneur et qu’on le détruit, puis qu’on démarre un nouveau conteneur faisant référence au même point de montage, on pourra retrouver les mêmes informations.
On pourra même partager des informations entre les conteneurs. En effet, chaque conteneur qui demandera un point de montage sur le dossier de l’hôte y aura accès.
Démonstration
On démarre un conteneur debian en demandant l’accès au
volume. On retrouve le répertoire /vol dans lequel se
trouve le fichier nouveau_fichier. On peut ajouter du texte
dans le fichier.
ubuntu@m347:~$ docker run -it --volume sharedvol:/vol:rw debian
root@68529ce0b064:/# ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var vol
root@68529ce0b064:/# ls /vol
nouveau_fichier
root@68529ce0b064:/# echo "Ajout d'une ligne" >> /vol/nouveau_fichier Dans un autre conteneur ubuntu qui tourne en parallèle,
on trouve le même dossier avec le même fichier dedans et on peut voir le
nouveau texte qui a été ajouté depuis l’autre conteneur
ubuntu@m347:~$ docker run -it --volume sharedvol:/vol:rw ubuntu
root@70a9671bebb3:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var vol
root@70a9671bebb3:/# echo "Test" > /vol/nouveau_fichier
root@70a9671bebb3:/# ls /vol
nouveau_fichierPour supprimer un volume, il faut qu’il ne soit pas utilisé. Lors de mon essai de suppression, j’ai obtenu un message d’erreur car des conteneurs étaient liés à ce volume (même s’ils sont à l’arrêt).
ubuntu@m347:~$ docker volume rm sharedvol
Error response from daemon: remove sharedvol: volume is in use - [70a9671bebb33375c0bf4af23b1debda49d75d0688044c984e88d618fe8ae652, 68529ce0b0648dc6f4af83384e5c4aaaeb81513009bbe720295c79195059fb42, 7a013025fb621e71612758db1992910a62cdde493ee727d1d0c0c1bacb2d01b3, d1957186d2fa99f1a7e2537220bee1dd58d050adb15836c7381af411b63153ba, b0b61d4709fcb3c7c2990b94e12c9a81f35bd703dad9c8210d88fcc1f0c1cbc0]
ubuntu@m347:~$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b0b61d4709fc ubuntu "bash" 41 seconds ago Exited (0) 39 seconds ago condescending_kilby
d1957186d2fa ubuntu "bash" 45 seconds ago Exited (0) 43 seconds ago sweet_chandrasekhar
7a013025fb62 ubuntu "bash" 48 seconds ago Exited (0) 46 seconds ago lucid_hermann
68529ce0b064 debian "bash" 28 minutes ago Exited (0) 13 minutes ago vibrant_hypatia
70a9671bebb3 ubuntu "bash" 52 minutes ago Exited (0) 13 minutes ago hopeful_nashPour supprimer ce volume, il faut supprimer les conteneurs qui lui sont associés. On peut faire cela ligne par ligne ou utiliser un assemblage de commande. En effet, s’il y a plusieurs dizaines de conteneurs ça commence à devenir pénible de faire cela ligne par ligne. À vous d’essayer de comprendre cet assemblage 🥴
ubuntu@m347:~$ docker rm $(docker ps -aq)
b0b61d4709fc
d1957186d2fa
7a013025fb62
68529ce0b064
70a9671bebb3
ubuntu@m347:~$ docker volume rm sharedvol
sharedvol
ubuntu@m347:~$ docker volume ls
DRIVER VOLUME NAMELa documentation officielle nous propose un autre assemblage de commandes
ubuntu@m347:~$ docker rm $(docker ps --filter status=exited -q)volumeOn vous demande de mettre en place un conteneur capable de compiler
un programme écrit en C#. L’utilisateur prépare son code source
Program.cs sur son hôte et le place dans un répertoire
nommé works qui est partagé avec le conteneur. Il démarre
ensuite le conteneur worker qui se charge de compiler le
programme et qui place le résultat de son travail dans le répertoire,
également partagé, deliverable.
Le programme compiler sera autonome, c’est-à-dire qu’il pourra fonctionner sans dépendance particulière.
Option
L’utilisateur peut placer un fichier de configuration pour déterminer
comment le programme doit être compilé. Par exemple, il peut placer un
fichier config.json dans le répertoire works
qui contiendra les informations suivantes
{
"target": "exe",
"architecture": "x64",
"name": "mon_programme"
}docker networkLa partie réseau de docker est très riche. On peut créer
des réseaux, les lister, les inspecter, les supprimer, les connecter à
des conteneurs, les connecter à des réseaux externes, … Comme nous
sommes dans le domaine de l’informatique de développement, on se
contentera de comprendre les bases et notamment l’installation de base
qui nous crée un bridge ainsi que le publication de
port.
Comme la vidéo l’explique, lorsqu’on crée une image docker, on peut
préciser une metadonnée qui indiquera à docker qu’il doit
publier un port. C’est le travail des développeurs de l’image nginx. Ils
ont précisé dans le fichier Dockerfile que le port
80 devait être publié. On peut voir cela dans le fichier
Dockerfile de l’image nginx sur le site Docker Hub
En cliquant sur le lien en dessous du titre Supported tags
and respective Dockerfile links, on peut voir le fichier
Dockerfile de l’image nginx. On y trouve la
ligne suivante:
EXPOSE 80nginxOn aimerait conteneuriser un site web statique. Le site se trouve sur
github. Bien entendu,
on ne placera dans le conteneur que les parties utiles au site web et
pas le fichier .gitignore par exemple.
Le site sera personnalisé avec votre nom et prénom (y.c. dans le
titre). On utilisera l’image nginx:alpine pour servir le
site. Le conteneur exposera le port 80. Au démarrage, on
publiera le port 80 du conteneur sur le port
8080 de l’hôte.
Il faudra encore rendre accessible le site en utilisant le nom de
domaine prénom-nom.local depuis l’hôte.
docker composedocker compose est un outil qui permet de définir et de
lancer des applications multi-conteneurs. Il permet de
définir les services qui composent une application dans un fichier
yaml et de les lancer en une seule commande.
Prenons comme exemple un site web que vous connaissez déjà:
Le site est composé de trois parties:
apache ou nginxmysql ou
mariadbphpSelon le principe de conteneurisation, chaque partie de l’application
sera isolée dans un conteneur différent mais chaque conteneur devra être
capable de communiquer avec les autres. En effet, le serveur web devra
pouvoir passer les requêtes php au conteneur
php et le conteneur php devra pouvoir se
connecter à la base de données.
apache ← partage fichier → phpphp ← requête réseau → mysqlOn peut partir de zéro et tout construire à la main. Mais on peut
également partir d’image de base déjà préparée et
officielles. C’est le cas de l’image php
par exemple. On peut trouver une image php sur le site Docker Hub. Cette image
peut-être utilisée seule, c’est-à-dire uniquement avec php
ou alors en combinaison avec apache.
php:<version>-cli : pour utiliser
php en ligne de commandephp:<version>-apache : pour utiliser
php avec apacheNous utiliserons l’image php:<version>-apache pour
notre site web. Comme il est indiqué dans la documentation de
l’image
This image contains Debian’s Apache httpd in conjunction with PHP (as
mod_php) and usesmpm_preforkby default.
La documentation nous indique également comment construire un fichier
Dockerfile et comment placer notre site web à l’intérieur
de l’image.
Si on veut aller encore plus loin, on peut trouver le fichier
Dockerfile utilisé pour créer cette image. Il suffit de se
rendre sur le lien docs
repo’s php/ directory. On y trouve un fichier
Dockerfile pour chaque version de php et pour
chaque type d’installation (cli, apache,
fpm, …).
Avec le même raisonnement, on trouve une image mysql sur
le site Docker Hub.
apacheLe site recettes demande une configuration particulière.
Ceci est du au fait qu’il utilise le framework codeigniter.
Parmis les spécificités, on peut citer:
README.md.git, le fichier README.md, …apache pour qu’il serve les
pages depuis le dossier public au lieu du dossier
html de l’image
php:<version>-apachecomposer pour installer les
dépendances y.c. codeigniter lui-mêmephp nécessaires pour que codeigniter
fonctionne, par exemple php-json,
php-mbstring, php-xml, …writable qui, comme son le nom l’indique, doit être
accessible en écriture.env
CI_ENVIRONMENT = production
app.baseURL = 'http://recettes.local'
database.default.hostname = mysql-container
database.default.database = recettes
database.default.username = u_recette
database.default.password = u_recette
database.default.DBDriver = MySQLi
database.default.DBPrefix =
database.default.port = 3306Dockerfile
# Use an official PHP Apache runtime
FROM php:8.2-apache
# Set the working directory to /var/www/html
ENV APACHE_DOCUMENT_ROOT=/var/www/html
# Set the hostname
ENV APACHE_HOST_NAME=recettes.local
# Prepare the new apache 000-default.conf file
ENV VIRTUAL_HOST="<VirtualHost *:80>\n \
ServerName ${APACHE_HOST_NAME}\n \
DocumentRoot ${APACHE_DOCUMENT_ROOT}/public\n \
<Directory ${APACHE_DOCUMENT_ROOT}/public>\n \
AllowOverride All\n \
Require all granted\n \
</Directory>\n \
ErrorLog \${APACHE_LOG_DIR}/error.log\n \
CustomLog \${APACHE_LOG_DIR}/access.log combined\n \
</VirtualHost>"
# Set the new apache 000-default.conf file
RUN echo "${VIRTUAL_HOST}" > /etc/apache2/sites-available/000-default.conf
# Update package lists
RUN apt-get update
# Install any needed packages
RUN apt-get install -y curl git zip unzip libicu-dev iputils-ping iproute2 nmap
# Install some optional packages for debugging
RUN apt-get install -y iputils-ping iproute2 nmap
# Install Composer
RUN curl -sS https://getcomposer.org/installer | php -- --install-dir=/usr/local/bin --filename=composer
# Allow root to run composer
ENV COMPOSER_ALLOW_SUPERUSER=1
# Make composer runnable and update-it
RUN chmod +x /usr/local/bin/composer
RUN /usr/local/bin/composer self-update
# Enable Apache modules
RUN a2enmod rewrite
# Install any extensions you need
RUN docker-php-ext-install mysqli intl
# Set the working directory to /var/www/html
WORKDIR ${APACHE_DOCUMENT_ROOT}
# Copy the source code in the local /recettes directory into the container at /var/www/html
COPY recettes ${APACHE_DOCUMENT_ROOT}
# Install the composer dependencies
RUN /usr/local/bin/composer install
# Set the rights on the writable directory
RUN chmod -R 775 "${APACHE_DOCUMENT_ROOT}/writable"
RUN chown -R www-data:www-data "${APACHE_DOCUMENT_ROOT}/writable"On peut, dès lors, construire l’image avec la commande
docker build et démarrer le conteneur
ubuntu@m347:~$ docker build -t apache-container -f Dockerfile .
ubuntu@m347:~$ docker run -d --name apache-container apache-containermysqlPour le conteneur mysql tout se fera directement dans le
fichier docker-compose.yml. On peut y préciser le nom de la
base de données, le nom d’utilisateur et le mot de passe. Il faudra bien
sûr veiller à ce que ces informations coincident avec celles qui se
trouvent dans le fichier .env du site
recettes.
docker-compose.ymlIl reste à écrire la recette qui permettra de démarrer les deux
conteneurs en même temps. C’est le rôle du fichier
docker-compose.yml. Ce fichier est écrit en
yaml. On y trouve la référence au fichier
Dockerfile pour le conteneur apache et la
configuration du conteneur mysql.
version: "3.9"
services:
web:
container_name: apache-container
build:
context: .
dockerfile: Dockerfile
ports:
- 80:80
mysql:
container_name: mysql-container
image: mysql:8.3
environment:
MYSQL_ROOT_PASSWORD: my-sup3r-p4ssw0rd
MYSQL_DATABASE: recettes
MYSQL_USER: u_recette
MYSQL_PASSWORD: u_recette
ports:
- 3306:3306
docker composeOn peut imaginer que le développeur de l’application
recettes ait fourni les fichiers Dockefile et
docker-compose.yml avec le code source de l’application. Il
ne resterait plus qu’à lancer la commande docker-compose up
pour démarrer l’application. Cependant, les connaissances requises pour
écrire le fichier Dockerfile et le fichier
docker-compose.yml sont plus proches de l’administration
système que du développement. Pas sûr qu’un dévloppeur soit en mesure de
réaliser les deux tâches.
On remarque également que le conteneur apache est très
similiaire à un conteneur système. Là où docker se présente
comme un conteneur d’application, dans certaines situations, il est plus
proche d’un conteneur système. Du coup, plutôt que de gérer tout ces
fichiers avec docker, on pourrait utiliser des conteneurs
système tel qu’incus, multipass ou d’autres. Pour réaliser
le même travail, on peut choisir d’utiliser cloud-init. Dès
lors la configuration complète du conteneur système se trouve dans un
seul fichier yaml.
Pour peut qu’on connaisse l’utilisation d’une distribution tel qu’Ubuntu, on peut aisaiment comprendre le contenu du fichier.
cloud-init.yaml
## template: jinja
#cloud-config
package_update: true
package_upgrade: true
timezone: Europe/Zurich
locale: fr_CH.UTF-8
packages:
- git
- apache2
- php
- mysql-server
- php-mysql
- php-intl
- php-mbstring
- php-xml
- php-json
write_files:
- path: "/etc/apache2/sites-available/{{ds.meta_data.local_hostname}}.conf"
owner: root:root
permissions: '0644'
content: |
<VirtualHost _default_:443>
ServerAdmin {{ds.meta_data.local_hostname}}@localhost
ServerName {{ds.meta_data.local_hostname}}.local
DocumentRoot /var/www/html/public
ErrorLog ${APACHE_LOG_DIR}/{{ds.meta_data.local_hostname}}.error.log
CustomLog ${APACHE_LOG_DIR}/{{ds.meta_data.local_hostname}}.access.log combined
SSLEngine on
SSLCertificateFile /etc/ssl/certs/ssl-cert-snakeoil.pem
SSLCertificateKeyFile /etc/ssl/private/ssl-cert-snakeoil.key
<Directory /var/www/html>
AllowOverride FileInfo
Require all granted
</Directory>
</VirtualHost>
runcmd:
- a2enmod rewrite
- a2enmod ssl
- a2dissite 000-default
- a2dissite default-ssl
- sed -i 's/\(Listen.*80\)/#\1/g' /etc/apache2/ports.conf
- sed -i 's/\(NameVirtualHost.*\*:\)80/\1443/g' /etc/apache2/ports.conf
- git clone https://git.s2.rpn.ch/SteeveDroz/recettes
- rm -rf recettes/LICENSE recettes/spark recettes/phpunit.xml.dist recettes/README.md recettes/tests/ recettes/.gitignore recettes/.git recettes/env
- echo -e "CI_ENVIRONMENT = production\napp.baseURL = 'http://recettes.local'\ndatabase.default.hostname = localhost\ndatabase.default.database = {{ds.meta_data.local_hostname}}\ndatabase.default.username = {{ds.meta_data.local_hostname}}\ndatabase.default.password = {{ds.meta_data.local_hostname}}" > recettes/.env
- mv -f recettes/{.,}* /var/www/html
- a2ensite "{{ds.meta_data.local_hostname}}"
- systemctl restart apache2
- mysql -u root -e "CREATE DATABASE IF NOT EXISTS {{ds.meta_data.local_hostname}};"
- mysql -u root -e "CREATE USER IF NOT EXISTS '{{ds.meta_data.local_hostname}}'@'localhost' IDENTIFIED BY '{{ds.meta_data.local_hostname}}';"
- mysql -u root -e "GRANT ALL PRIVILEGES ON *.* TO '{{ds.meta_data.local_hostname}}'@'localhost';"
- mysql -u root -e "FLUSH PRIVILEGES;"
users:
- name: "{{ds.meta_data.local_hostname}}"
gecos: Local User
sudo: ALL=(ALL) NOPASSWD:ALL
groups: users, admin
shell: /bin/bash
lock_passwd: trueOn crée le conteneur avec la commande:
ubuntu@m347:~$ lxc launch ubuntu:22.04/cloud recettes --config user.user-data="$(cat cloud-init.yaml)"Là encore, on est proche de la configration système et un peu trop loins du développement.
Vous avez créer une image qui vous semble utile et que vous aimeriez
partager avec d’autres personnes. Vous pouvez le faire en la publiant
sur Docker Hub. Pour cela, il faut
créer un compte sur le site en suivant les instructions. Une fois votre
compte créé, cliquez sur le lien Create Repository. Vous
arrivez alors sur une page où vous devez saisir le nom de votre dépôt,
ainsi qu’une courte description. Vous aurez également la possibilité de
régler la visibilité de votre dépôt.
Sur la droite de la page, vous trouverez directement les commandes à réaliser pour publier votre image.
$ docker tag local-image:tagname new-repo:tagname
$ docker push new-repo:tagnameAvant de pouvoir faire ces commandes, vous devrez vous connecter à
votre compte depuis la ligne de commande avec la commande
docker login. Vous devrez saisir votre nom d’utilisateur et
votre mot de passe.
Reprenez l’image HelloCS que vous avez créée dans le
chapitre docker build et publiez-la sur Docker Hub.
Le mélange de docker et d’incus sur une même machine peut induire des problèmes, notament à cause des règles de firewall. Si docker démarre après incus, il réécrit des règles qui empêche les conteneurs incus d’accéder à internet. Pour éviter cela, on peut démarrer incus après docker ou alors définir des règles de firewall qui permettent à incus d’accéder à internet.
$ sudo iptables -I DOCKER-USER -i incusbr0 -j ACCEPT
$ sudo iptables -I DOCKER-USER -o incusbr0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT{kind=link}