Le terme DevOps est un mot-valise anglais formé à partir de “development” (développement) et “operations” (exploitation). Il désigne un ensemble de pratiques visant à automatiser et à industrialiser l’ensemble des processus de production des applications logicielles, depuis la phase de développement jusqu’à la phase de mise en production.
Au début des années 2000, l’industrie du logiciel connaissait une révolution rapide avec l’adoption généralisée de l’internet et l’évolution des technologies. Cependant, malgré les avancées technologiques, les entreprises étaient confrontées à des défis majeurs dans la livraison de logiciels.
Silotage des équipes : Les équipes de développement (dev) et les équipes des opérations (ops) travaillaient souvent en silos séparés, avec des objectifs et des priorités différents. Les développeurs se concentraient sur la création de nouvelles fonctionnalités, tandis que les opérations se focalisaient sur la stabilité et la maintenance des systèmes.
Longs cycles de développement : Les méthodologies traditionnelles de développement logiciel, comme le modèle en cascade (waterfall), impliquaient des cycles de développement longs. Les changements étaient rarement déployés en production, et chaque déploiement était une opération risquée et complexe.
Problèmes de communication : Le manque de communication et de collaboration entre les équipes de développement et des opérations entraînait souvent des problèmes de déploiement, des erreurs de configuration, et des délais dans la résolution des problèmes.
Environnements incohérents : Les environnements de développement, de test et de production étaient souvent différents, ce qui causait des problèmes de compatibilité et de performance lors du déploiement des applications.
Au milieu des années 2000, plusieurs entreprises ont commencé à adopter des pratiques agiles pour améliorer la flexibilité et la réactivité du développement logiciel. Cependant, les défis liés à la livraison et au déploiement des logiciels persistaient. Il était nécessaire de trouver des moyens pour aligner les objectifs des équipes de développement et des opérations.
Agile et Lean : Les méthodologies agiles ont mis l’accent sur des cycles de développement plus courts, des livraisons continues et une collaboration accrue. Les principes Lean, quant à eux, ont introduit des concepts de réduction des gaspillages et d’optimisation des processus.
Culture de collaboration : Les entreprises ont réalisé l’importance de briser les silos organisationnels et de promouvoir une culture de collaboration et de communication entre les équipes. L’idée était de faire en sorte que les développeurs et les opérations travaillent ensemble tout au long du cycle de vie du développement logiciel.
Automatisation et outillage : L’émergence d’outils d’automatisation et de gestion des configurations a permis d’automatiser de nombreuses tâches répétitives et d’améliorer la cohérence des environnements de développement et de production. Des outils comme Puppet, Chef, Ansible, et plus tard Docker et Kubernetes, ont joué un rôle crucial dans cette automatisation.
Livraison continue (CD) : Les pratiques de livraison continue ont permis de déployer des changements de manière plus fréquente et plus fiable, en intégrant des tests automatisés et en facilitant le déploiement en production. Cela a permis de réduire les délais de mise en production et d’améliorer la qualité du logiciel.
Le terme “DevOps” a été popularisé lors de la conférence “Velocity” en 2009, où John Allspaw et Paul Hammond de Flickr ont présenté un discours intitulé 10+ Deploys per Day: Dev and Ops Cooperation at Flickr. Leur présentation a illustré comment la collaboration entre les équipes de développement et des opérations permettait d’améliorer considérablement la fréquence et la fiabilité des déploiements.
Depuis lors, DevOps est devenu un mouvement global adopté par de nombreuses entreprises à travers le monde. Il a évolué pour inclure des pratiques telles que l’infrastructure en tant que code (IaC), le monitoring en continu, et l’intégration de la sécurité dès le début du cycle de développement (DevSecOps).
DevOps est né de la nécessité de surmonter les défis traditionnels du développement et des opérations. En promouvant une culture de collaboration, en automatisant les processus et en adoptant des pratiques de livraison continue, DevOps a transformé la manière dont les logiciels sont développés, déployés et gérés. Aujourd’hui, il est un élément clé pour les entreprises cherchant à innover rapidement et à maintenir une haute qualité de service.
Ces deux thermes sont souvent associés à DevOps. Ils sont des pratiques clés du mouvement DevOps. C’est pourquoi il est important de les comprendre.
La CI (Continuous Integration) est une pratique de développement logiciel qui consiste à intégrer fréquemment les modifications de code dans un dépôt partagé. Chaque modification est automatiquement testée et validée, ce qui permet de détecter et de corriger les erreurs plus rapidement.
La CD (Continuous Delivery) est une pratique de développement logiciel qui consiste à automatiser le processus de déploiement des applications. Les modifications de code sont automatiquement construites, testées et déployées en production, ce qui permet de réduire les délais de mise en production et d’améliorer la qualité du logiciel.
Il existe de nombreux outils qui peuvent être utilisés pour mettre en œuvre les pratiques DevOps. Voici quelques-uns des outils les plus populaires :
Vous ne devrez pas tous les connaître et je ne pense pas qu’il existe une personne qui les maîtrise tous. Nous pratiquerons quelqu’uns de ces outils et vous vous adapterez à ceux de votre futur entreprise.
Connaître des possibilités d’utilisation des outils d’automatisation dans l’environnement de développement (p. ex. linting, build, exécuter, tester, versionner, dépendances/paquets).
Le linting est une pratique de développement logiciel qui consiste à analyser le code source pour détecter les erreurs de syntaxe, les problèmes de style et les mauvaises pratiques de programmation. Les outils de linting permettent de garantir la cohérence du code, d’améliorer sa lisibilité et de réduire les erreurs.
ESLint est un outil de linting pour JavaScript qui permet de détecter et de corriger les erreurs de syntaxe, les problèmes de style et les mauvaises pratiques de programmation. Il est largement utilisé dans l’industrie du logiciel pour améliorer la qualité du code JavaScript.
Un fichier de configuration standard de linting ressemble à ceci :
{
"rules": {
"no-unused-vars": "error",
"no-undef": "error"
}
}Dans cet exemple, nous avons défini deux règles de linting :
no-unused-vars et no-undef. La règle
no-unused-vars signale une erreur si une variable est
déclarée mais jamais utilisée, tandis que la règle no-undef
signale une erreur si une variable est utilisée sans être déclarée.
Vous trouverez également cette notation :
{
"rules": {
"quotes": [ 2, "double" ],
"no-unused-vars": 1,
"no-undef": 0
}
}Les valeurs 0, 1, 2 correspondent respectivement à off,
warn et error.
“off” or 0 - turn the rule off
“warn” or 1 - turn the rule on as a warning (doesn’t affect exit code)
“error” or 2 - turn the rule on as an error (exit code is 1 when triggered)
Bien entendu, il existe de nombreuses autres règles de linting que vous pouvez configurer en fonction de vos besoins. Vous trouverez des exemples de règles de linting de différentes entreprises sur github.
Pré-requis : Node.js doit être installé sur votre machine.
Pour cet exercice, vous allez installer ESLint et créer un fichier de configuration de linting pour un projet JavaScript. Le travail sera réalisé dans l’outil de développement Visual Studio Code.
jseslint.index.js dans le dossier du projet et
ajoutez-y le code suivant :console.log('Demo ESLint')$ npm init
This utility will walk you through creating a package.json file.
It only covers the most common items, and tries to guess sensible defaults.
See `npm help init` for definitive documentation on these fields
and exactly what they do.
Use `npm install <pkg>` afterwards to install a package and
save it as a dependency in the package.json file.
Press ^C at any time to quit.
package name: (jseslint)
version: (1.0.0)
description: ESLint projet for learning
entry point: (index.js)
test command:
git repository:
keywords:
author: Pierre Ferrari
license: (ISC)
About to write to /your/path/jseslint/package.json:
{
"name": "jseslint",
"version": "1.0.0",
"description": "ESLint projet for learning",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Pierre Ferrari",
"license": "ISC"
}
Is this OK? (yes) yes
$ npx eslint --init
You can also run this command directly using 'npm init @eslint/config@latest'.
> jseslint@1.0.0 npx
> create-config
✔ How would you like to use ESLint? · problems
✔ What type of modules does your project use? · esm
✔ Which framework does your project use? · none
✔ Does your project use TypeScript? · javascript
✔ Where does your code run? · browser
The config that you’ve selected requires the following dependencies:
eslint@9.x, globals, @eslint/js
✔ Would you like to install them now? · No / Yes
✔ Which package manager do you want to use? · npm
☕️Installing...
added 90 packages, and audited 91 packages in 1s
23 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Successfully created /your/path/jseslint/eslint.config.mjs file.
$ tree -L 1
.
├── eslint.config.mjs
├── index.js
├── node_modules
├── package.json
└── package-lock.json
2 directories, 4 filesDéclarez une variable non utilisée dans le fichier
index.js et observez comment ESLint signale une erreur.
Vous pouvez voir que la variable est soulignée en rouge et si vous
placez votre curseur dessus, ESLint affiche un message d’erreur.
'i' is assigned a value but never used. eslint (no-unused-vars)On peut également voir les erreurs dans la console de Visual Studio Code.
$ npx eslint index.js
/your/path/jseslint/index.js
1:5 error 'i' is assigned a value but never used no-unused-vars
✖ 1 problem (1 error, 0 warnings)Dans le fichier de configuration package.json ajouter
une commande pour lancer ESLint ainsi qu’une commande pour
démarrer l’exécution du script index.js.
{
"name": "jseslint",
"version": "1.0.0",
"description": "ESLint projet for learning",
"main": "index.js",
"scripts": {
"start": "node index.js",
"lint": "eslint \"**/*.js\" --ignore-pattern node_modules/"
},
"author": "Pierre Ferrari",
"license": "ISC",
"devDependencies": {...}
}Puis modifier les fichiers :
eslint.config.mjs
import globals from "globals"
import pluginJs from "@eslint/js"
export default [
{
languageOptions: {
globals: globals.browser
},
rules: {
quotes: [ "error", "double" ],
"no-unused-vars": "error",
"no-undef": "error",
"no-implicit-globals": "error",
"no-const-assign": "error",
"no-var": "error",
"prefer-const": "error",
"array-bracket-spacing": [ "error", "always", { "arraysInArrays": false } ],
eqeqeq: "error",
semi: [ "error", "never" ],
indent: [ "error", 2 ],
}
},
pluginJs.configs.recommended,
]et index.js sans changer quoi que ce
soit dans un premier temps.
var i = 0;
let arr = [[ 1, 2 ], 2, [ 3, 4],4,[5, 6 ], 7, [8, 9], 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
console.log('Demo ESLint')
for(y = 0; y < 10; y++)
{
console.log(arr[y]);
}
if (i == 10)
{
console.log('i is 10')
}
else
{
console.log('i is not 10')
}Ensuite, démarrer le script avec la commande npm start
et lancer ESLint avec la commande npm run lint.
Vous pouvez constater que le script fonctionne très bien mais qu’il ne respect pas les règles de linting.
Corriger les erreurs détectées par ESLint pour les faire disparaître.
Trouver et ajouter les règles de linting permettant de détecter les erreurs suivantes :
if (condition) {
// code
} else {
// code
}Si vous reprenez le code d’exemple fournit plus haut sans faire de modification, vous devriez obtenir les erreurs suivantes :
$ npx eslint index.js
1:1 error Unexpected var, use let or const instead no-var
1:10 error Extra semicolon semi
2:1 error This line has a length of 97. Maximum allowed is 80 ????
2:5 error 'arr' is never reassigned. Use 'const' instead prefer-const
2:31 error A space is required before ']' array-bracket-spacing
2:35 error A space is required after '[' array-bracket-spacing
2:47 error A space is required after '[' array-bracket-spacing
2:52 error A space is required before ']' array-bracket-spacing
2:97 error A space is required before ']' array-bracket-spacing
3:13 error Strings must use doublequote quotes
5:5 error 'y' is not defined no-undef
5:12 error 'y' is not defined no-undef
5:20 error 'y' is not defined no-undef
6:1 error Expected indentation of 0 tabs but found 2 spaces ????
6:3 error Opening curly brace does not appear on the same line as controlling statement ????
7:1 error Expected indentation of 1 tab but found 2 spaces ????
7:19 error 'y' is not defined no-undef
7:22 error Extra semicolon semi
10:7 error Expected '===' and instead saw '==' eqeqeq
11:1 error Opening curly brace does not appear on the same line as controlling statement ????
12:1 error Expected indentation of 1 tab but found 2 spaces ????
12:15 error Strings must use doublequote quotes
13:1 error Closing curly brace does not appear on the same line as the subsequent block ????
15:1 error Opening curly brace does not appear on the same line as controlling statement ????
16:1 error Expected indentation of 1 tab but found 2 spaces ????
16:15 error Strings must use doublequote quotesUne fois que vous obtenez toutes les erreurs, et donc que votre fichier de configuration d’ESLint est correct, vous pouvez les corriger pour les faire disparaître.
Les tests unitaires sont une pratique de développement logiciel qui consiste à tester les composants individuels d’une application de manière isolée. Les tests unitaires permettent de vérifier le bon fonctionnement des fonctions, des classes et des modules, et de détecter les erreurs de manière précoce.
Cela suppose également que le code soit organisé de manière à ce que les composants soient facilement testables. C’est pourquoi il est important de suivre les principes de conception logicielle tels que le découplage, l’encapsulation et la modularité.
Chaque langage possède ses propres outils de test unitaire. Voici quelques-uns des outils les plus populaires pour les langages de programmation courants :
Vitest est un outil de test unitaire pour JavaScript. Il est pensé pour être compatible avec l’outil Vite. Il est compatible avec le framework de test Jest très largement utilisé dans l’industrie.
Vitest possède des atouts par rapport à Jest :
import et
exportL’avantage de Vitest réside dans sa
console interactive. En effet, le développeur peut voir les résultats
des tests en temps réel dans la console de son navigateur. Cela permet
de détecter les erreurs plus rapidement et de faciliter le processus de
débogage. Ainsi, au moment d’envoyer du code à la partie
ops, il est possible de garantir que le code est
fonctionnel.
Pré-requis : Node.js doit être installé sur votre machine.
Pour cet exercice, vous allez installer Vitest et configurer un fichier de test unitaire pour un projet JavaScript. Le travail sera réalisé dans l’outil de développement Visual Studio Code.
L’ensemble des instructions pour réaliser cet exercice se trouve dans la vidéo DevTheory.
Jest et
Vitest et donc, il va faire beaucoup de modification en
cours de vidéo
Dans l’optique d’utiliser les tests unitaires dans un pipeline CI/CD, il est important de pouvoir lancer les tests en ligne de commande. On vous demande de réaliser toutes les étapes de mise en place d’un environnement de test permettant de tester un programme réalisé en Javascript.
Le programme sera basique. Il comportera un module mathématique qui contiendra trois fonctions :
add qui prendra deux paramètres et qui
retournera la somme de ces deux paramètres.sub qui prendra deux paramètres et qui
retournera la différence de ces deux paramètres.rotate qui prendra un tableau de nombres
et qui retournera un tableau de nombres où le premier élément est devenu
le dernier.math.js
export function add(a, b) {
// Votre code ici
}
export function sub(a, b) {
// Votre code ici
}
export function rotate(arr, n) {
// Votre code ici
}Les tests unitaires seront réalisés avec Vitest.
math.test.js
import { add, sub, rotate } from './math.js'
test('[add] expect the result of 1 + 2 to be 3', () => {
expect(add(1, 2)).toBe(3)
})
// les autres tests
...Les tests seront les suivants :
add avec les paramètres
1 et 2. Le résultat attendu est
3.add avec les paramètres
-1 et -0. Le résultat attendu est
-1.add avec les paramètres
-1.0 et 1.0. Le résultat attendu est
0.add avec les paramètres
1 et 'a'. Le résultat attendu est une
erreur.add avec les paramètres
'a' et [1]. Le résultat attendu est une
erreur.add avec les
paramètres qui ne sont pas des nombres. Le résultat attendu est une
erreur.sub identique aux tests de la
fonction add.rotate avec le tableau
[1, 2, 3, 4]. Le résultat attendu est
[2, 3, 4, 1].rotate avec le tableau
[a, 2, 3, 4]. Le résultat attendu est une erreur.rotate avec le tableau
[1, 2, 3, 4, 5]. Le résultat attendu est
[2, 3, 4, 5, 1].rotate avec le tableau
[1]. Le résultat attendu est [1].rotate avec le tableau
[]. Le résultat attendu est [].rotate avec le tableau
[[1], 2, 3, 4, 5, 6, 7, 8, 9, 10]. Le résultat attendu est
un erreur.Le résultat attendu est le suivant
$ npm run vitest
> js-test@1.0.0 vitest
> vitest --globals
DEV v2.0.5 /your/path/js-test
✓ math.test.js (16)
✓ [add] expect the result of 1 + 2 to be 3
✓ [add] expect the result of -1 + -0 to be -1
✓ [add] expect the result of -1.0 + 1.0 to be 0
✓ [add] expect the result of 1 + 'a' to be an error
✓ [add] expect the result of 'a' + [1] to be an error
✓ [sub] expect the result of 1 - 2 to be -1
✓ [sub] expect the result of -1 - -0 to be -1
✓ [sub] expect the result of -1.0 - 1.0 to be -2
✓ [sub] expect the result of 1 + 'a' to be an error
✓ [sub] expect the result of v + [a] to be an error
✓ [rotate] expect the result of [1, 2, 3, 4] to be [2, 3, 4, 1]
✓ [rotate] expect the result of [a, 2, 3, 4] to be an error
✓ [rotate] expect the result of [1, 2, 3, 4, 5] to be [2, 3, 4, 5, 1]
✓ [rotate] expect the result of [1] to be [1]
✓ [rotate] expect the result of [] to be []
✓ [rotate] expect the result of [[1], 2, 3, 4, 5, 6, 7, 8, 9, 10] to be an error
Test Files 1 passed (1)
Tests 16 passed (16)
Start at 13:52:56
Duration 239ms (transform 22ms, setup 0ms, collect 17ms, tests 6ms, environment 0ms, prepare 67ms)La documentation est une partie essentielle du développement logiciel. Elle permet de décrire le fonctionnement d’une application, d’une bibliothèque ou d’un module, et de fournir des informations sur son utilisation, ses fonctionnalités et ses API.
Il existe de nombreux outils de documentation pour les différents langages de programmation. Voici quelques-uns des outils les plus populaires :
JSDoc est un outil de documentation pour JavaScript qui permet de générer une documentation à partir des commentaires du code source. Il est largement utilisé dans l’industrie du logiciel pour documenter les bibliothèques et les modules JavaScript.
Un exemple de commentaire JSDoc ressemble à ceci :
/**
* Add two numbers.
* @param {number} a - The first number to add.
* @param {number} b - The second number to add.
* @returns {number} The sum of the two numbers.
*/
function add(a, b) {
return a + b;
}Dans cet exemple, nous avons documenté la fonction add
en spécifiant le type des paramètres et de la valeur de retour. Cela
permet de générer une documentation claire et précise à partir du code
source.
Pour générer la documentation à partir des commentaires JSDoc, il suffit d’exécuter la commande suivante :
$ npx jsdoc src/math.jsou alors
$ node_modules/.bin/jsdoc src/math.jsCette commande génère un répertoire out contenant les
fichiers HTML de la documentation. Vous pouvez ouvrir le fichier
index.html dans un navigateur pour visualiser la
documentation.

Reprenez l’exercice précédent des tests unitaires et ajoutez des commentaires JSDoc au code source du module mathématique. Générez ensuite la documentation à partir des commentaires JSDoc.
La documentation doit contenir les informations suivantes pour chaque fonction :
README.md à la racine du projet qui
explique comment installer et utiliser le module mathématique.see, link).math.js est un module ES6.Le résultat doit se trouver dans un répertoire docs à la
racine du projet. La commande pour générer la documentation doit aller
chercher la configuration, notamment du répertoire de sortie, dans le
fichier jsdoc-conf.js.
Le build est une étape du processus de développement logiciel qui consiste à compiler, à transformer et à regrouper les fichiers source en un exécutable ou en un package distribuable.
Chaque environnement de développement possède ses propres outils de
build avec des finalités bien différentes. Si vous écrivez
un programme en C, vous utiliserez make ou
cmake pour obtenir un fichier binaire exécutable tel qu’un
fichier ELF
pour Linux ou PE pour
Windows. Si vous écrivez un programme en Java, vous utiliserez
maven ou gradle pour obtenir un fichier
interprétable par la Java vm.
Si vous écrivez un programme en Javascript, vous utiliserez
webpack, vite, parcel ou
rollup pour fournir un répertoire contenant toutes les
dépendances nécessaires telles que les fichiers index.html,
index.js et style.css.
À cette étape, il est important de définir les particularités de
l’environnement de production. C’est une étape qui doit être réalisée en
collaboration avec les équipes ops. En effet, les équipes
ops doivent être en mesure de déployer l’application en
production et comme elles sont responsables de l’infrastructure, elles
doivent être impliquées dans le processus de build.
Prenons un exemple simple. Imaginons le développement d’une application web en JavaScript qui est en mesure de faire des conversions monétaires.
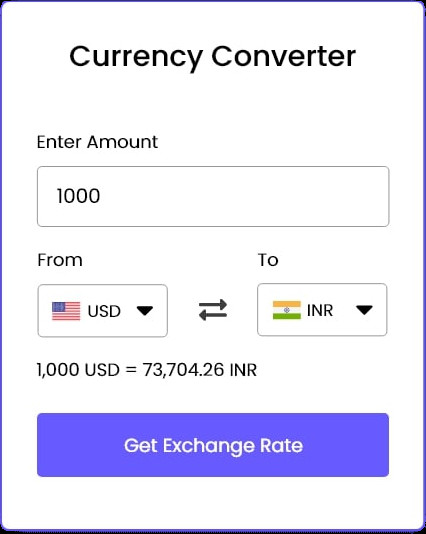
Le développeur travail avec les import / export de module Javascript
et une api personnelle basée sur l’API fetch
en mode asynchrone.
Dans son environnement, tout ce passe à merveille. Aucun problème n’est
détecté. Cependant, lorsqu’il envoie son code à l’équipe
ops, il reçoit en retour un message qui l’informe que son
application ne fonctionne pas.
vite v5.2.13 building for production...
✓ 5 modules transformed.
x Build failed in 97ms
error during build:
[vite:esbuild-transpile] Transform failed with 2 errors:
assets/index-!~{001}~.js:223:20: ERROR: Top-level await is not available in the configured target environment ("chrome87", "edge88", "es2020", "firefox78", "safari14" + 2 overrides)C’est normal car l’équipe ops utilise, pour ses tests,
un environnement qui ne supporte pas l’utilisation des méthodes
asynchrones directement dans le module de premier niveau.
La différence se résume à la simple ligne suivante de configuration
dans le fichier vite.config.js :
export default ({
build: {
target: 'esnext',
},
})Malheureusement, le développeur n’a pas fournit ce fichier de
configuration à l’équipe ops et il a ignoré ce fichier dans
le dépôt Git pensant qu’il s’agissait d’un fichier de configuration
local. Comme l’équipe ops utilise la version présente dans
le dépôt Git, elle n’a pas pu déployer l’application.
Inévitablement, les deux équipes seront en conflit pour savoir qui a raison et qui a tort. C’est pourquoi il est important de définir les particularités de l’environnement de production dès le début du projet et de les documenter.
Pour cet exercice nous utiliseront vitejs pour construire un site web simple basé sur du Javascript.
L’objectif de l’exercice est de réaliser le site web présenté ci-dessous.
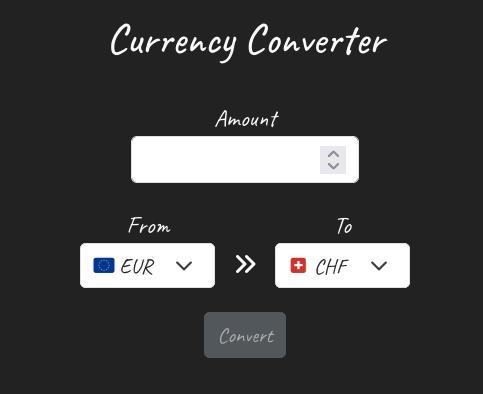
Ce site permet de convertir des devises. Il se base sur l’API ExchangeRate. L’API fournit un service gratuit pour obtenir les taux de change entre différentes devises. Dans sa version gratuite, on ne peut pas directement faire la conversion d’une devise en une autre mais on peut passer par le Dollar US car l’API fournit le taux de change entre le Dollar US et les autres devises.
€ → CHF revient à faire € ⇢ $ ⇢ CHF.
currency-data.json (depuis le
site github, visionner le fichier en mode Raw pour
comprendre son contenu).hand-writing à
choix disponible sur le site google fonts.api.js.
Elle expose au moins les méthodes asynchrones
getLatestRates et getSupportedCurrencies.main.jsque l’on place les
comportements (événements) de l’application et qu’on fait appel aux
méthodes du module api.js.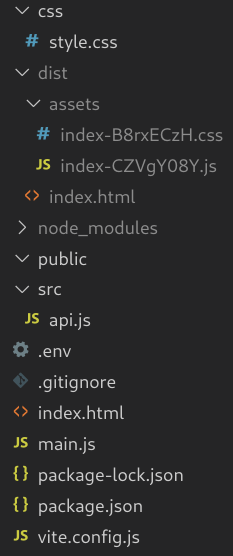
Grâce à l’outils vitejs vous
pourrez réaliser la partie build du projet. Le
build fournit un répertoire dist contenant
tous les fichiers nécessaires pour le déploiement en production. On peut
voir sur la structure ci-dessus que le build à déjà été
réalisé.
Une fois votre build réalisé, vous devez vérifier que le
site fonctionne correctement. Pour cela, vous devez :
dist dans un
serveur web local. Par exemple Laragon ou Wamp.index.html dans un navigateur via le
protocole HTTP.404 sur le
favicon.ico signifie que le navigateur n’a pas pu trouver
ce fichier.Au final, l’arborescence de votre projet doit ressembler à ceci :
.
├── dist
│ ├── assets
│ │ ├── index-BKEa98Qj.js
│ │ └── index-Col1SUQS.css
│ ├── favicon.png
│ └── index.html
├── css
│ └── style.css
├── index.html
├── main.js
├── .env
├── package.json
├── package-lock.json
├── public
│ └── favicon.png
├── README.md
├── src
│ ├── api.js
│ └── api.test.js
└── vite.config.jsVous pouvez remarquer que le répertoire public contient le
favicon du site. Si le fichier favicon se
trouve dans le dossier public c’est parce que vitejs le
copie automatiquement dans le répertoire dist lors du
build.
Le dossier racine comporte également un fichier .env qui
permet de définir des variables d’environnement utilisable par
vitejs. Par exemple, si vous avez besoin d’une clé d’API
pour l’API de conversion de devises, vous pouvez la définir dans ce
fichier.
.env
VITE_API_KEY=b596b2.................ea8d68b
VITE_API_ENDPOINT=https://openexchangerates.org/apiapi.js
const response = await fetch(`${import.meta.env.VITE_API_ENDPOINT}/latest.json?app_id=${import.meta.env.VITE_API_KEY}`)Le fichier .env est ignoré par git et ne doit pas être
versionné. Il doit être fourni par l’équipe ops lors du
déploiement en production.
Connaître des procédures de développement en équipe dont le suivi est compréhensible et traçable (p. ex. liaison des commits et des récits utilisateur, PullRequest/revue par les pairs). Connaître des pratiques de gestion du code source basée fonctionnalités (p. ex. flux de travail GIT, versionnage sémantique, etc.).
La partie Git du cours est entièrement basé sur le livre gratuit et officiel que l’on peut trouver à cette adresse : https://git-scm.com/book/fr/v2.
Cette partie s’articule autour de la lecture de ce livre (pas complètement 😓) et de la réalisation d’exercices pratiques. Voici comment il faut procéder :
Installez-vous confortablement sur votre chaise, téléchargez et ouvrez le livre officiel de Git.
Lisez les 3 premiers chapitres du livre. Au fur et à mesure de votre avancement, mettez en pratique les commandes qui sont présentées. Aucune aide externe ne vous est autorisée pour ces 3 chapitres. Vous devez vous débrouiller seul ou avec votre enseignant. Il ne vous est pas possible de demander à vos camarades de classe ni d’utiliser Internet!
Vous avez bien entendu le droit de créer des dépôts locaux et/ou distant sur Gitlab pour vous entraîner. Vous pourrez supprimer ces dépôts une fois que vous n’en aurez plus besoin.
Dans cette partie on vous explique les différents gestionnaires de versions, on vous parle de l’origine de Git et de ses prédécesseurs et on vous explique comment installer et configurer Git.
Comme il est indiqué dans ce chapitre:
Dans ce livre, nous utiliserons Git en ligne de commande. Tout d’abord, la ligne de commande est la seule interface qui permet de lancer toutes les commandes Git - la plupart des interfaces graphiques simplifient l’utilisation en ne couvrant qu’un sous-ensemble des fonctionnalités de Git. Si vous savez comment utiliser la version en ligne de commande, vous serez à même de comprendre comment fonctionne la version graphique, tandis que l’inverse n’est pas nécessairement vrai.
Votre objectif est d’installer Git sur votre machine si ce n’est pas
déjà fait, et de passer en revue les différents niveaux de
configuration, system, global et
local.
Déjà que vous y êtes, configurer votre nom et votre adresse email dans la configuration globale.
$ git config --global --list
user.email=pierre.ferrari@rpn.ch
user.name=piferrari
credential.helper=/usr/share/doc/git/contrib/credential/libsecret/git-credential-libsecret
init.defaultbranch=main
pull.rebase=false
alias.last=log -1 HEADLes différentes valeurs de configuration sont expliquées sur la page
de manuel de git-config que vous pouvez consulter avec la
commande man git-config ou en ligne à cette adresse : https://git-scm.com/docs/git-config.
Dans ce chapitre, vous allez apprendre les bases de Git. Vous allez apprendre à créer un dépôt, à y ajouter des fichiers, à les valider et à les pousser sur un serveur distant. Vous apprendrez également à ignorez des fichiers et à les renommer.
Commandes pratiquées dans ce chapitre :
$ git init
$ git add
$ git status
$ nano .gitignore
$ git clone
$ git commit
$ git status
$ git diff
$ git mv
$ git rm
$ git log
$ git reset
$ git checkout
$ git restore
$ git remote
$ git push
$ git pull
$ git fetch
$ git tag
$ git show
$ git lastDans ce chapitre, vous allez apprendre à créer des branches, à les fusionner et à les supprimer. Vous allez également apprendre à gérer les conflits de fusion.
Ce chapitre constitue une référence des commandes Git. Vous pouvez le consulter à tout moment pour retrouver une commande ou une option.
Après avoir pratiqué les exercices précédents, vous devriez être en mesure de réaliser l’exercice ci-dessous. Ce pourrait être un exercice d’examen.
votreNom contenant votre nom. Par
exemple ferrarip contenant
Pierre Ferrari.origin vers le dépôt distant exercice-base.
ATTENTION, on ne vous demande pas de le cloner, mais de
créer un lien vers ce dépôt.main du
dépôt distant dans votre dépôt local. En l’occurrence, un fichier
README.md.README.md dans votre dépôt local.Vous trouvez un dépôt binCraft à cette
adresse.
Le dépôt original est différent de ce dépôt pour plusieurs raison mais une des raisons c’est que le dépôt original contient des erreurs dans le décodage des valeurs binaires alors que dans ce dépôt, les erreurs ont étés corrigées. Votre travail consiste à retrouver les erreurs pour être en mesure de proposer des corrections au mainteneur du dépôt original.
Bien entendu, il ne faut pas chercher à lire le code pour trouver les erreurs. Vous devez utiliser Git pour faire le travail.
Une fois les erreurs identifiées, préparez un patch par erreur identifiée comme si vous vouliez soumettre une demande de fusion (merge request) au mainteneur du dépôt original.
On ne souhaite fournir que les modifications du fichier
binCraft_decoder.py puisque c’est le seul fichier identique
présent sur le dépôt d’origine. On souhaite également prendre en compte
toutes les modifications faites depuis le début, c’est-à-dire, depuis le
commit initiale ayant le hash cf2cb6d8 jusqu’à l’état
actuel HEAD
$ bincraft-decoder$ git diff --patch cf2cb6d8 HEAD binCraft_decoder.py > patch.txt
$ cat patch.txt
+++ b/binCraft_decoder.py
@@ -1,4 +1,4 @@
-#!/usr/bin/python3
+#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import struct
import math
@@ -96,10 +96,10 @@ def binCraftReader(file,zstd_compressed=False):
ac['lat'] = s32[2] / 1e6;
ac['lon'] = s32[3] / 1e6;
- ac['alt_baro'] = s16[8] * 25;
- ac['alt_geom'] = s16[9] * 25;
- ac['baro_rate'] = s16[10] * 8;
- ac['geom_rate'] = s16[11] * 8;
+ ac['alt_baro'] = s16[10] * 25;
+ ac['alt_geom'] = s16[11] * 25;
+ ac['baro_rate'] = s16[8] * 8;
+ ac['geom_rate'] = s16[9] * 8;
ac['nav_altitude_mcp'] = u16[12] * 4;
ac['nav_altitude_fms'] = u16[13] * 4;
@@ -150,7 +150,7 @@ def binCraftReader(file,zstd_compressed=False):
ac['nic_a'] = (u8[72] & 64) >> 6;
ac['nic_c'] = (u8[72] & 128) >> 7;
- ac['rssi'] = 10 * math.log10(u8[86]*u8[86]/65025 + 1.125e-5);
+ ac['rssi'] = 10 * math.log10(u8[86]*u8[86]/65025 + 1.125e-5) / math.log(10);
ac['dbFlags'] = u8[87];
ac['flight'] = genStr(u8,78,87)Reprenez l’exercice du currency converter que vous avez déjà
réalisé précédemment dans la partie build. Durant la
réalisation de cet exercice, on ne vous demandait pas de versionner
votre code. Vous allez maintenant versionner votre code.
README.md..gitignore spécialisé pour le
langage Javascript et le gestionnaire vitejs.first commitv1.0.0.€ → CHF, il doit pouvoir convertir CHF → € en
un clic.v1.1.0.v2.0.0.$ git log --graph --abbrev-commit --decorate --format=format:'%C(bold blue)%h%C(reset) - %C(auto)%d%C(reset) %C(white)%s%C(reset) %C(dim white)- %an%C(reset)' --all
* 1517d42 - (HEAD -> main, tag: v2.0.0, origin/main, origin/HEAD) feat(api)!: changement d'api et adaptation des tests unitaires - piferrari
* 7e5262d - (tag: v1.1.0) feat(app): ajout de la fonctionnalité permettant d'inverser la conversion, par exemple € → CHF par CHF → € en un clic - piferrari
* b9d7042 - (tag: v1.0.0) refactor(readme): mise à jour du fichier readme - piferrari
* 5a369fa - fix(js): suppression de l'event change inutile - piferrari
* c5eae45 - fix(html): correction du titre de la page - piferrari
* 9e758fb - refactor(vite): ajout du dossier public et utilisation de ce dossier pour favicon - piferrari
* 7a9ca98 - feat(js): ajout du programme de conversion, suppression des tests et import css via vite - piferrari
* 79955f1 - feat(html): ajout des formulaires html avec le css - piferrari
* 9ed7492 - feat(api): ajout de l'api exchange ainsi que des tests unitaires - piferrari
* 5e85721 - feat(vite): mise en place de l'environnement vite avec sa config - piferrari
* 3dd38d0 - Initial commit - Ferrari Pierre (PDF)
Vous pouvez également pratiquer les exercices suivants chez vous :
Utiliser un processus d’intégration automatisé est essentiel pour optimiser la qualité et la rapidité des cycles de développement logiciel. L’intégration automatisée consiste à déclencher automatiquement une série de tests et de validations à chaque modification du dépôt.
Ce processus permet de détecter rapidement les erreurs de compilation, les conflits de fusion, ou les bugs introduits par des modifications récentes, réduisant ainsi les délais entre la détection d’un problème et sa résolution. De plus, l’automatisation garantit que les tests sont exécutés de manière cohérente et exhaustive, augmentant ainsi la fiabilité du logiciel. Par exemple, dans un environnement DevOps, l’intégration automatisée peut inclure des tests unitaires, des tests d’intégration, des vérifications de la qualité du code, et même le déploiement sur des environnements de staging, permettant ainsi aux équipes de déceler les problèmes potentiels avant que le code n’atteigne la production. Cette approche non seulement accélère le cycle de développement, mais aussi améliore la qualité et la stabilité du produit final, tout en réduisant les risques de régressions et en favorisant une culture de développement itératif et collaboratif.
Il existe plusieurs manières de procéder pour faire de l’intégration continue. Chaque entreprise possède sa propre manière de faire même si elle se base sur des concepts communs. Ce que vous allez mettre en pratique est un exemple parmi d’autres.
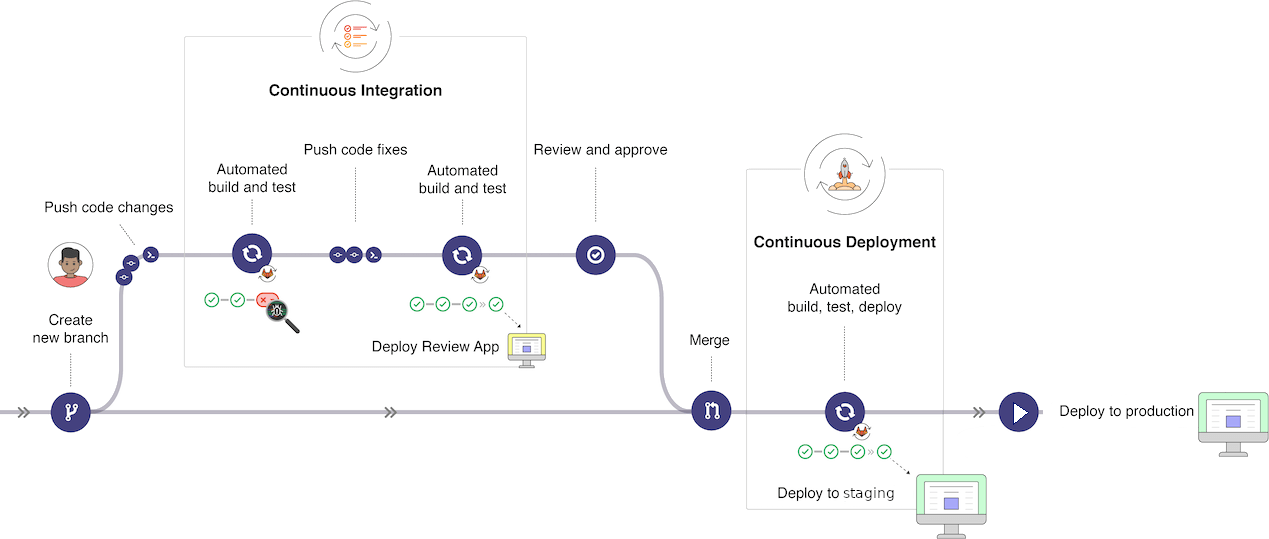
Dans cet exemple, on voit un développeur qui va ajouter une fonctionnalité ou corriger un bug.
Il va créer une branche à partir de la branche main pour
réaliser son travail. Il fera des commits réguliers pour sauvegarder son
travail. Une fois qu’il pense être au bout de son travail, il va pousser
sa branche sur le dépôt distant. Cette action va démarrer un pipeline
CI/CD qui va tester le code, le compiler, le valider. Une fois que tous
les tests mis en place seront passés (✔), le code sera proposé à une
revue par un pair, un autre développeur ou un responsable.
Une fois la revue terminée, l’auteur va créer une demande de fusion
(merge request) pour fusionner sa branche avec la branche
main. Cette demande de fusion va déclencher un nouveau
pipeline CI/CD qui va tester le code, le compiler, le valider et le
déployer sur un environnement de staging.
Dans la phase de staging, un groupe de testeur utilisera la nouvelle version proposée pour vérifier que tout fonctionne correctement. Si tout est OK, le code validé sera déployé en production.
GitLab propose un outil d’intégration continue et de déploiement continu intégré directement dans son outil de gestion de versions. Cet outil s’appelle GitLab CI/CD.
GitLab CI/CD permet de définir des pipelines d’intégration continue et de déploiement continu directement dans le fichier de configuration du dépôt Git. Ces pipelines sont déclenchés automatiquement à chaque modification du dépôt, permettant ainsi de tester, de compiler et de déployer le code de manière automatisée.
Les pipelines GitLab CI/CD sont définis dans un fichier
.gitlab-ci.yml à la racine du dépôt Git. Ce fichier
contient les étapes du pipeline, les tâches à exécuter, les dépendances
entre les tâches, et les conditions de déclenchement du pipeline.
Voici un exemple de fichier .gitlab-ci.yml pour un
pipeline simple :
stages:
- build
- test
- deploy
build:
stage: build
script:
- npm install
- npm run build
test:
stage: test
script:
- npm test
deploy:
stage: deploy
script:
- npm run deploy
only:
- mainDans cet exemple, le pipeline est composé de trois étapes :
build, test et deploy. Chaque
étape contient une ou plusieurs tâches à exécuter, définies dans la
section script. Les tâches sont exécutées dans l’ordre
défini par les stages, et les dépendances entre les étapes
sont gérées automatiquement par GitLab CI/CD.
stage s’exécute dans un conteneur système
lxd séparé. Le conteneur correspond à une installation
d’Ubuntu 20.04 vierge
Créez un dépôt sur le serveur GitLab de l’école. Nommez ce dépôt
cicd-basique.
Dans le menu de gauche, cliquez sur Build puis sur
Pipeline editor. Activez les pipelines GitLab CI/CD pour ce
projet en créant le fichier .gitlab-ci.yml par un simple
appui sur le bouton Configure pipeline. Vous vous trouvez
alors dans l’éditeur de pipeline.
Commiter le fichier .gitlab-ci.yml en cliquant sur le
bouton Commit changes. Rendez-vous ensuite dans l’onglet
Pipelines pour voir le pipeline se déclencher.
Cet exercice est en réalité une vidéo réalisée par M. Droz lors d’un cours en ligne. Vous allez suivre pas à pas les instructions de la vidéo pour réaliser un pipeline GitLab CI/CD.
La vidéo se trouve à cette adresse : Ubicast S2.
Pour cet exercice, vous allez créer un pipeline GitLab CI/CD pour un projet JavaScript en NodeJS. Le pipeline doit inclure les étapes suivantes :
Le travail sera réalisé dans l’outil de développement Visual Studio Code.
js-cicd. Le projet est vide pour l’instant.js-cicd.js-cicd en exécutant la commande
npm init.$ npm install dayjsindex.js dans le dossier du projet et
ajoutez-y le code suivant :import dayjs from "dayjs"
const today = dayjs()
const year_end = dayjs('2024-12-31')
console.log(year_end.diff(today, 'day'))package.json pour ajouter le
type module ainsi que les scripts
start et test suivants :
"main": "index.js",
"type": "module",
"scripts": {
"start": "node index.js",
"test": "echo \"Error: no test specified\" && exit 1"
}npm start et npm test.$ npm start
> js-cicd@1.0.0 start
> node index.js
194$ npm test
> js-cicd@1.0.0 test
> echo "Error: no test specified" && exit 1
Error: no test specified.gitlab-ci.yml à la racine du projet
et ajoutez le contenu suivant :stages:
- install
- run
- test
- deploy
install:
stage: install
before_script:
- placer ici le nécessaire pour installer les dépendances du projet
script:
- placer ici le code nécessaire pour ce stage
run:
stage: run
before_script:
- placer ici le nécessaire pour installer les dépendances du projet
script:
- placer ici le code nécessaire pour ce stage
test:
stage: test
before_script:
- placer ici le nécessaire pour installer les dépendances du projet
script:
- placer ici le code nécessaire pour ce stage
deploy:
stage: deploy
script:
- echo "Deploying to staging server..."
only:
- mainErreurs :
Il y a des erreurs dans l’exécution du pipeline, c’est normal si vous
n’avez rien changé au fichier YAML présent ci-dessous. En effet, dans ce
fichier il n’y a actuellement aucune commande valide. Trouvez-les les
commandes permettant d’effectuer les 3 premiers
stages uniquement.
Le corrigé est dans la branche correct.
On est obligé de faire l’installation de node dans chaque job car c’est un nouveau conteneur qui est lancé à chaque job. Il n’y a pas de persistance entre les jobs.
J’ai essayé de mettre en place du cache mais apparemment, il n’est pas supporté dans les runners partagés lxc.
Dès que le job test est lancé, ça plante et c’est
normal. Il n’y a pas de test dans le projet et la commande retourne la
valeur 1. C’est pour cela que le pipeline est en erreur.
Comment savoir que c’est une erreur. Par convention, un script retourne la valeur 0 si tout s’est bien passé et une autre valeur si une erreur est survenue.
$ printf "Hello"
$ echo $?
0
$ printf "Hello %d" a
bash: printf: a: nombre non valable
Hello 0
$ echo $?
1
Les pipelines GitLab CI/CD sont exécutés par des agents appelés
runners. Les runners sont des machines virtuelles ou
physiques qui exécutent les tâches du pipeline. Ils peuvent être
hébergés sur le cloud, sur site ou sur des machines dédiées. GitLab
propose des runners partagés et des runners spécifiques à chaque projet,
permettant ainsi de personnaliser l’environnement d’exécution des
pipelines en fonction des besoins du projet.
Les runners GitLab CI/CD sont configurés dans les paramètres du projet GitLab. Vous pouvez définir des runners partagés ou spécifiques à chaque projet, en fonction de vos besoins. Les runners peuvent être configurés pour exécuter des tâches spécifiques, utiliser des images Docker personnalisées, ou se connecter à des services externes pour exécuter des tâches spécifiques.

Pour créer un runner local, il faut installer le logiciel
gitlab-runner sur la machine qui va exécuter les tâches du
pipeline. Le runner peut être installé sur n’importe quelle machine
compatible avec GitLab CI/CD, y compris les machines virtuelles, les
conteneurs Docker, les serveurs physiques, etc.
Nous installerons un runner dans une machine virtuelle Ubuntu 20.04. Pour cela, nous allons suivre les étapes suivantes :
gitlab-runner sur la machine
virtuelle en suivant les instructions de la documentation
officielle.ubuntu@m347:~$ curl -sL "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh" | sudo bash
[sudo] password for ubuntu:
Detected operating system as Ubuntu/jammy.
Checking for curl...
Detected curl...
Checking for gpg...
Detected gpg...
...
ubuntu@m347:~$ sudo apt install gitlab-runnerjs-cicd, ajoutez un
runner spécifique au projet en suivant les instructions de la documentation
officielle.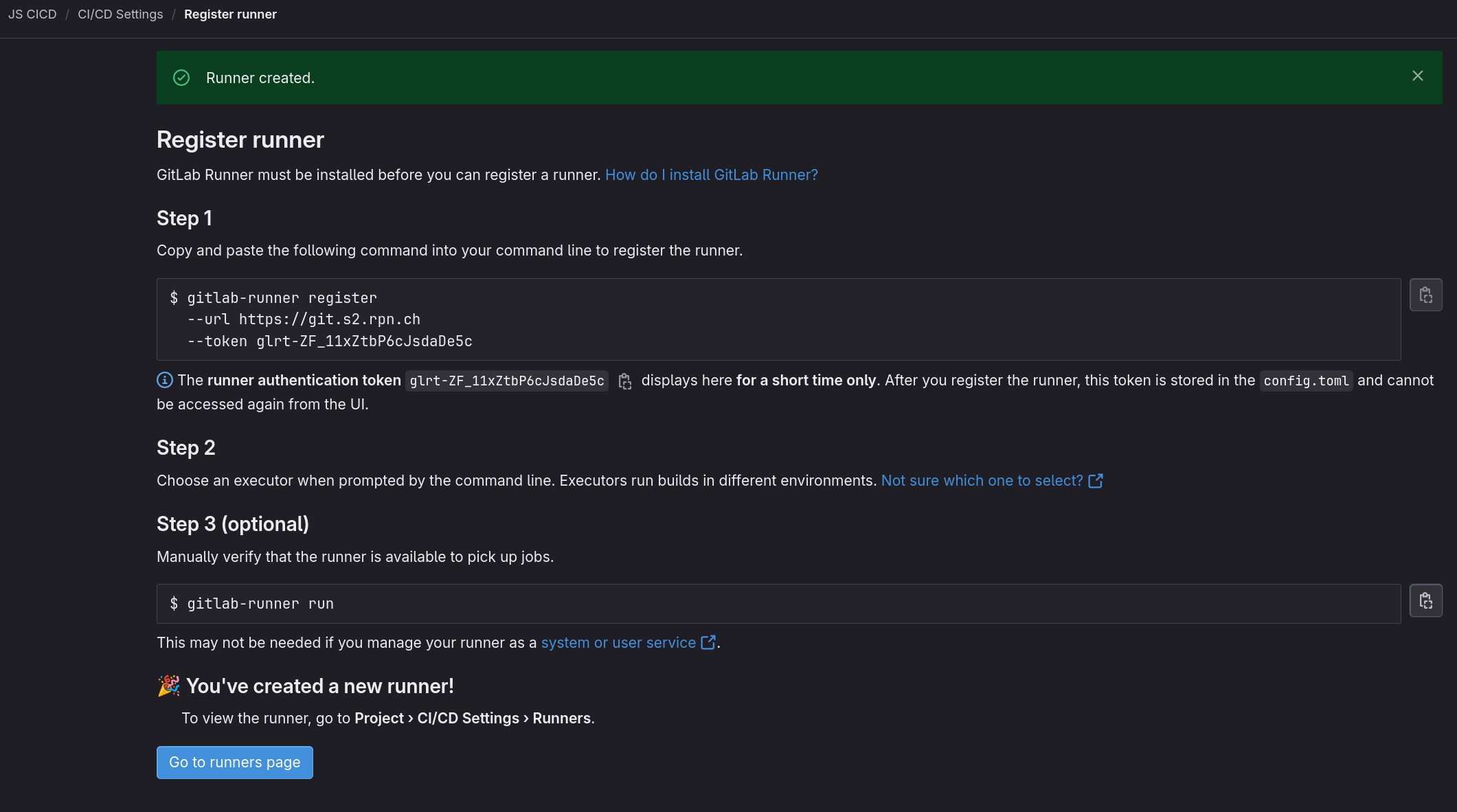
ubuntu@m347:~$ gitlab-runner register --url https://git.s2.rpn.ch --token glrt-ZF_11xZtbP6cJsdaDe5c
ubuntu@m347:~$ gitlab-runner run
Runtime platform arch=amd64 os=linux pid=3420 revision=b92ee590 version=17.4.0
Starting multi-runner from /home/ubuntu/.gitlab-runner/config.toml... builds=0 max_builds=0
WARNING: Running in user-mode.
WARNING: Use sudo for system-mode:
WARNING: $ sudo gitlab-runner...
Configuration loaded builds=0 max_builds=1
listen_address not defined, metrics & debug endpoints disabled builds=0 max_builds=1
[session_server].listen_address not defined, session endpoints disabled builds=0 max_builds=1
Initializing executor providers builds=0 max_builds=1
Checking for jobs... received job=6941 repo_url=https://git.s2.rpn.ch/versioning/js-cicd.git runner=ZF_11xZtb
Added job to processing list builds=1 job=6941 max_builds=1 project=5320 repo_url=https://git.s2.rpn.ch/versioning/js-cicd.git time_in_queue_seconds=1
Appending trace to coordinator...ok code=202 job=6941 job-log=0-317 job-status=running runner=ZF_11xZtb sent-log=0-316 status=202 Accepted update-interval=1m0s
Removed job from processing list builds=0 job=6941 max_builds=1 project=5320 repo_url=https://git.s2.rpn.ch/versioning/js-cicd.git time_in_queue_seconds=1
Checking for jobs... received job=6942 repo_url=https://git.s2.rpn.ch/versioning/js-cicd.git runner=ZF_11xZtb
Added job to processing list builds=1 job=6942 max_builds=1 project=5320 repo_url=https://git.s2.rpn.ch/versioning/js-cicd.git time_in_queue_seconds=3
Appending trace to coordinator...ok code=202 job=6942 job-log=0-1524 job-status=running runner=ZF_11xZtb sent-log=0-1523 status=202 Accepted update-interval=1m0sSources :
Cette partie est un copier / coller du blog de Stéphane Robert. Elle est copier ici au cas où le blog disparaitrait.
Lui-même c’est inspiré de la documentation officielle de GitLab.
Tout bon consultant DevOps se doit d’optimiser ses pipelines CI/CD.
GitLab CI/CD, offre une variété de conditions de workflow qui permettent
une personnalisation et une optimisation importantes des pipelines. Ces
conditions, comme if, when,
except, rules et workflow, sont
des instruments clés pour gérer le comportement des jobs dans vos
pipelines.
Pourquoi les Conditions sont-elles essentielles ?
Simplement parce que toutes les étapes d’un pipeline ne doivent pas nécessairement être exécutées à chaque commit ou à chaque modification du code source. C’est pour cette raison que GitLab CI/CD permet l’utilisation de conditions dans le fichier YAML.
Les conditions définissent les règles qui déterminent si une étape du pipeline doit être exécutée ou non. Elles permettent d’optimiser le processus de développement en exécutant uniquement les étapes nécessaires.
Pour définir des conditions sur un job du pipeline, il suffit d’y
ajouter une section rules. Chaque règle spécifie une
condition sous la forme d’une expression conditionnelle et le job sera
exécuté si cette condition est évaluée comme vraie.
job:
script:
- echo "Cette étape s'exécute si la condition est satisfaite"
rules:
- if: '$CI_COMMIT_BRANCH == "main"'Dans cet exemple, le job sera exécuté uniquement si la
branche du commit est main. Cet exemple est très simple
mais les possibilités offertes par les conditions sont vastes. Vous
pouvez créer des conditions complexes en utilisant des opérateurs
logiques ET, OU ainsi que des variables
d’environnement que vous aurez vous-même définies ou qui sont fournies
par GitLab.
Voyons quelques exemples d’utilisation courants de conditions :
rules:
- if: '$CI_COMMIT_TAG'Ici, le job sera exécuté uniquement si le commit est associé à un tag.
rules:
- if: '$CI_PIPELINE_SOURCE == "manual"'Ce job s’exécutera seulement si le pipeline a été déclenché manuellement.
when pour Contrôler le Déclenchementwhen est utilisé à l’intérieur des règles
rules pour définir le moment où un job doit être exécuté.
GitLab offre plusieurs options pour when afin de
personnaliser le déclenchement de vos jobs en fonction de scénarios
spécifiques.
on_successrules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: on_successDans cet exemple, le job sera exécuté uniquement si la branche du
commit est main et si tous les jobs précédents dans le
pipeline ont été exécutés avec succès.
on_failurerules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: on_failureCe job s’exécutera uniquement si la branche du commit est
main et si au moins l’un des jobs précédents dans le
pipeline a échoué.
alwaysrules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: alwaysCe job sera toujours exécuté, quelle que soit l’état des jobs
précédents, tant que la branche du commit est main.
manualrules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: manualCe job ne s’exécute que lorsque l’utilisateur le déclenche manuellement, indépendamment des autres conditions.
delayedrules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: delayed
start_in: 30 minutesCe job s’exécute automatiquement, mais il est retardé de 30 minutes à partir du déclenchement du pipeline.
scheduledrules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: scheduled
cron: "0 12 * * *"Ce job est planifié pour s’exécuter tous les jours à midi.
workflowLa directive workflow détermine si un pipeline doit être
créé et exécuté. Contrairement aux règles appliquées à des jobs
individuels, workflow permet de contrôler le déclenchement
de l’ensemble du pipeline en se basant sur des critères globaux. Cette
capacité de gestion à un niveau supérieur offre un contrôle précis et
efficace sur l’exécution des pipelines, en particulier dans des projets
complexes avec de multiples branches et conditions.
Un cas d’utilisation courant de workflow est la mise en
place de conditions pour exécuter des pipelines uniquement pour certains
événements ou pour certaines branches. Par exemple, vous pourriez
vouloir déclencher un pipeline seulement lors d’un push sur
la branche principale ou sur des branches de fonctionnalités, mais pas
sur des branches de corrections de bugs. Voici comment cela peut être
configuré :
workflow:
rules:
- if: '$CI_PIPELINE_SOURCE == "push"'
- if: '$CI_COMMIT_BRANCH == "main"'
- if: '$CI_COMMIT_BRANCH =~ /^feature-/'Dans cet exemple, le pipeline est déclenché lors d’un
push sur la branche principale main ou sur une
branche dont le nom commence par feature-. Cette
configuration permet d’assurer que les ressources ne sont pas gaspillées
sur des pipelines non essentiels, tout en garantissant que les branches
importantes reçoivent l’attention nécessaire.
workflow peut également intégrer des logiques plus
complexes, comme des conditions basées sur des variables
d’environnement, des tags ou des changements spécifiques dans le code.
Cela permet une flexibilité et une personnalisation élevées, adaptant
vos pipelines aux besoins spécifiques de votre projet.
Exemple : Éviter les exécutions redondantes de pipelines
Imaginons un cas où vous souhaitez éviter que le même pipeline soit
déclenché à la fois par un push et par un tag
sur le même commit. En effet, si vous créez un tag avec la
commande git tag <tagname>, le tag sera
créer localement. Vous devrez donc poursuivre votre travail par un
git push origin --tags. Ceci est un scénario courant où des
pipelines redondants peuvent se lancer si les règles ne sont pas bien
configurées. Voici comment workflow peut être utilisé pour
gérer cela :
workflow:
rules:
- if: '$CI_COMMIT_TAG'
when: never
- if: '$CI_PIPELINE_SOURCE == "push"'Dans cet exemple, le pipeline est configuré pour ne pas se déclencher
lorsqu’un tag est appliqué grâce à
when: never. Cela signifie que si un commit est à la fois
poussé et tagué, le pipeline ne se déclenchera que pour le
push, évitant ainsi un déclenchement redondant pour le
tag.
Exemple : Gérer les pipelines pour les merge requests
Un autre cas d’usage fréquent est la gestion des pipelines pour les
merge requests. Imaginez que vous avez ouvert une merge request et pour
une raison quelconque, un commit est poussé sur la branche de la merge
request. Vous ne voulez pas que le pipeline se déclenche à la fois pour
le commit et pour la merge request. Voici comment workflow
peut être utilisé pour gérer cela :
workflow:
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
- if: '$CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS'
when: neverDans cette configuration, le pipeline se déclenche uniquement pour les événements de merge requests. Si un commit est poussé sur une branche qui a une merge request ouverte, le pipeline ne se déclenchera pas séparément pour cette branche, évitant ainsi des exécutions en double.
Ces exemples illustrent le fonctionnement de la directive
workflow pour affiner la logique de déclenchement de vos
pipelines dans GitLab CI/CD, vous permettant ainsi de gérer efficacement
les ressources et d’éviter des exécutions inutiles ou redondantes.
rules et workflowL’intégration et l’orchestration efficaces des pipelines dans GitLab
CI/CD peuvent être grandement améliorées en combinant judicieusement les
rules au niveau des jobs avec la directive
workflow pour le pipeline global. Cette combinaison permet
une gestion fine et une optimisation des déclenchements et exécutions
des jobs, adaptant ainsi les pipelines aux exigences spécifiques et aux
conditions de votre projet.
Exemple : Gestion de pipelines en fonction des branches et des événements
Imaginez un scénario où vous souhaitez exécuter des jobs différents en fonction de la branche sur laquelle les commits sont poussés, tout en gérant globalement le déclenchement des pipelines pour éviter les redondances. Voici comment cela peut être configuré :
workflow:
rules:
- if: '$CI_PIPELINE_SOURCE == "push" && $CI_COMMIT_BRANCH == "main"'
- if: '$CI_PIPELINE_SOURCE == "schedule"'
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
deploy:
script: deploy.sh
rules:
- if: '$CI_COMMIT_BRANCH == "main"'
when: manual
- if: '$CI_COMMIT_BRANCH =~ /^release-/'
when: on_success
test:
script: test.sh
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'Ici, le job deploy est configuré pour s’exécuter
manuellement sur la branche principale et automatiquement en cas de
succès sur les branches commençant par release-. Le job
test est quant à lui déclenché uniquement pour les merge
requests. Le workflow global est configuré pour déclencher
le pipeline pour les push sur la branche principale, les
événements de planification et les événements de merge requests, tout en
évitant les déclenchements redondants.
En comprenant et en appliquant ces concepts dans vos projets, vous pourrez assurer que vos pipelines ne sont pas seulement fonctionnels, mais qu’ils sont également conçus de manière à répondre efficacement aux changements et exigences de votre environnement de développement. Cela conduira à une intégration et une livraison continues plus robustes, fiables et efficientes, un objectif clé dans toute démarche DevOps.
En parcourant un dépôt GitLab, vous trouvez le fichier
.gitlab-ci.yml suivant :
stages:
- build
- test
- deploy
workflow:
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
- if: "$CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS"
when: never
- if: "$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH"
...💬 Comment connaître le nom de la branche par défaut
$CI_DEFAULT_BRANCH de ce dépôt ?
💬 Quels sont les autres mots clés utilisables avec la variable
$CI_PIPELINE_SOURCE ?
💬 Quel est le comportement du pipeline si un commit est poussé sur la branche principale ?
💬 Quel est le comportement du pipeline si un commit est poussé sur une branche qui a une merge request ouverte ?
Être en mesure de créer un pipeline GitLab CI/CD complet pour un projet de conversion de devises en utilisant les conditions de déclenchement et les règles de workflow.
Le travail s’effectue dans des branches séparées. Interdictions de
travailler directement sur la branche main.
Le pipeline doit inclure les étapes suivantes :
Changelog.md
contenant les modifications apportées en se basant sur les messages de
commit.docs.zip contenant le site web de documentation. Ce fichier
zip pourra être téléchargé depuis l’interface GitLab, dézippé dans un
dossier www de Laragon par exemple, et visualisé.[T] = Toujours, [M] = Uniquement lors d’un merge request sur main
Pour pouvoir déployer le site web sur un serveur de staging, vous devez disposer d’un serveur web Apache2 ou Nginx. Vous pouvez utiliser une machine virtuelle ou un conteneur Docker pour simuler le serveur de staging.
Par exemple, si vous utilisez un runner local dans une machine virtuelle Ubuntu, vous pouvez installer un serveur Apache2 dans cette même machine. Votre runner aura alors la possibilité de pousser les fichiers du runner vers le serveur Apache2.
Pour être complet dans cette simulation, il serait intéressent de
pousser les fichiers via rsync
ou scp
sur le serveur de staging. Dans les deux cas, vous aurez besoin d’un
serveur OpenSSH sur la
machine Ubuntu.
Conservez la configuration par défaut du serveur OpenSSH pour simplifier la mise en place.
Pour le nom d’utilisateur et le mot de passe à utiliser avec la connexion SSH, vous devez utiliser les variables CI/CD. L’utilisation est détaillée dans la vidéo de M. Droz.